TPC-DS Benchmark: Trino 476, Spark 4.0.0, and Hive 4 on MR3 2.1 (MPP vs MapReduce)

In our previous article, we evaluated the performance of Trino 468, Spark 4.0.0-RC2, and Hive 4.0.0 on MR3 2.0 using the TPC-DS Benchmark with a scale factor of 10TB.
- Correctness. Trino returns incorrect results for both subqueries of query 23.
- Total execution time (Sequential). Trino is the fastest, followed closely by Hive on MR3 (4,442 seconds vs 4,874 seconds). Spark is the slowest, skewed by a few outlier queries (15,678 seconds).
- Average response time (Sequential). Trino maintains the lead in average response time, with Hive on MR3 again closely behind (17.49 seconds vs 19.76 seconds).
- Longest execution time (Concurrent). Under concurrent workloads (10, 20, and 40 clients), Hive on MR3 consistently outperforms both Trino and Spark.
In this article, we evaluate the performance of the latest versions:
- Trino 476 (released in June 2025)
- Spark 4.0.0 (released in May 2025)
- Hive 4.0.0 on MR3 2.1 (released in July 2025)
By conducting the experiment in the same cluster used in the previous evaluation, we can assess the improvements in the newer versions. In the end, we draw the same conclusions as in the previous article, but the performance gap between Trino and Hive on MR3 is now much narrower in sequential tests (4,245 seconds vs 4,299 seconds) and slightly wider in concurrent tests.
Experiment Setup
We use exactly the same experiment setup as in the previous article, except for the Java versions.
- Java 24 for Trino (required by Trino 476)
- Java 22 for Spark and Hive on MR3
The scale factor for the TPC-DS benchmark is 10TB.
In a sequential test, we submit 99 queries from the TPC-DS benchmark. We report the total execution time, the average response time, and the execution time of each individual query. For average response time, we use the geometric mean of execution times, as it takes into account outlier queries that run unusually short or long.
In a concurrent test, we use a concurrency level of 10, 20, or 40 and start the same number of clients, each submitting queries 30 to 49 from the TPC-DS benchmark in a unique sequence. For each run, we measure the longest execution time among all clients.
Raw data of the experiment results
For the reader's perusal, we attach the table containing the raw data of the experiment results. Here is a link to [Google Docs].
Analysis of sequential tests
Query completion
Every system completes all queries successfully.
Correctness
As in the previous evaluation, Trino still returns wrong results for query 23.
Total execution time
In terms of total execution time, Trino is the fastest, but Hive on MR3 is nearly as fast.
- Trino completes all queries in 4,245 seconds.
- Spark completes all queries in 15,266 seconds.
- Hive on MR3 completes all queries in 4,299 seconds.
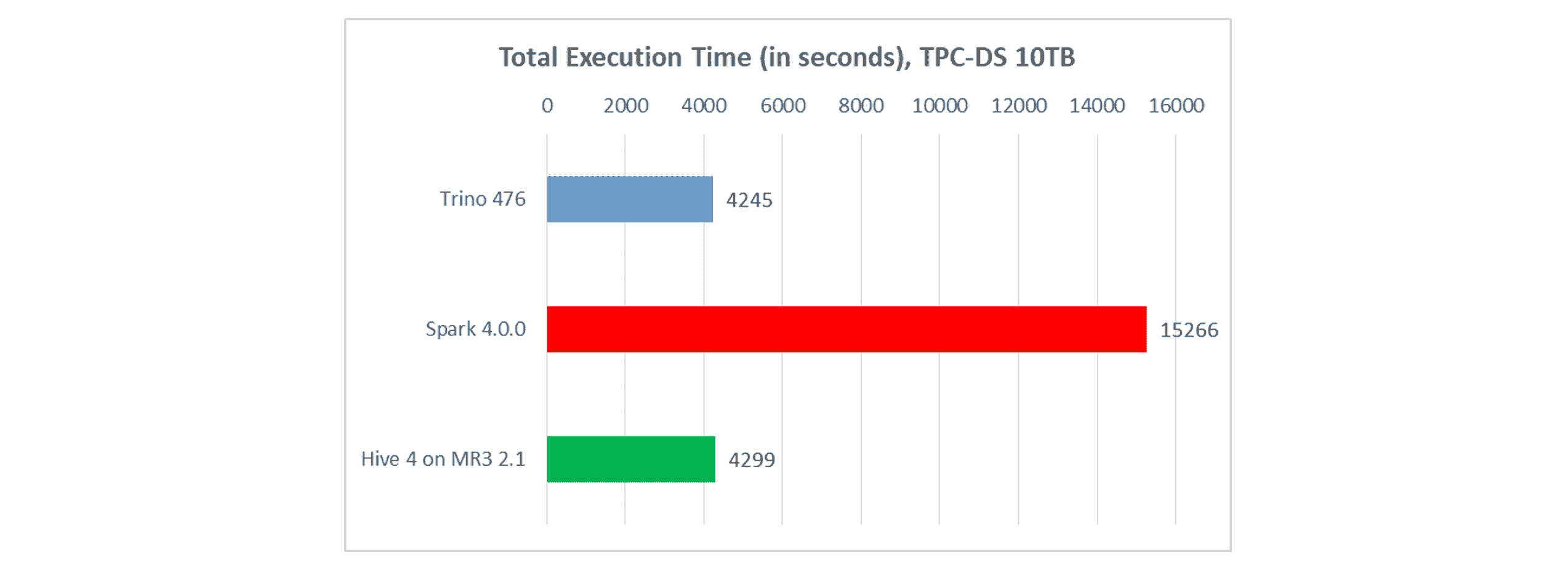
The three systems are all faster than their previous versions, but Hive on MR3 shows the most significant improvement as it is about 13 percent faster (from 4,873 seconds of Hive on MR3 2.0). Trino is about 5 percent faster (from 4,441 seconds of Trino 468), and Spark shows a slight improvement (from 15,678 seconds of Spark 4.0.0-RC2).
Average response time
In terms of average response time, Trino remains the fastest, but Hive on MR3 is nearly as fast.
- Trino completes each query in 17.46 seconds on average.
- Spark completes each query in 38.24 seconds on average.
- Hive on MR3 completes each query in 17.84 seconds on average.
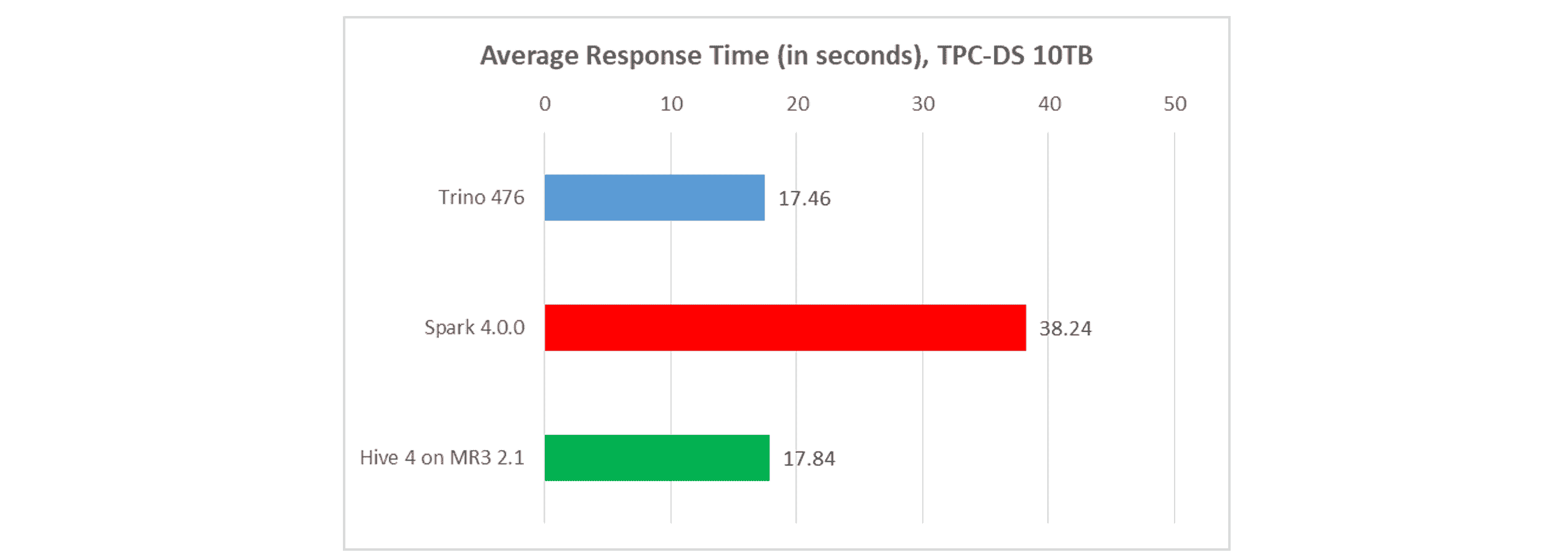
Compared with the previous versions, Trino shows virtually no difference (from 17.49 seconds of Trino 468), while Hive on MR3 is about 10 percent faster (from 19.76 seconds of Hive on MR3 2.0). Spark is slightly slower (from 37.65 seconds of Spark 4.0.0-RC2), but the difference is statistically insignificant because of the relatively long running time.
Analysis of concurrent tests
Query completion
Every system successfully completes all queries at concurrency levels of 10, 20, and 40.
Longest execution time
In terms of longest execution time, Hive on MR3 is the fastest. For concurrency levels of 10, 20, and 40:
- Trino completes all queries in 2,345, 4,650, 9,787 seconds, respectively.
- Spark completes all queries in 3138, 5,995, 12,515 seconds, respectively.
- Hive on MR3 completes all queries in 1,841, 3,803, 7,802 seconds, respectively.
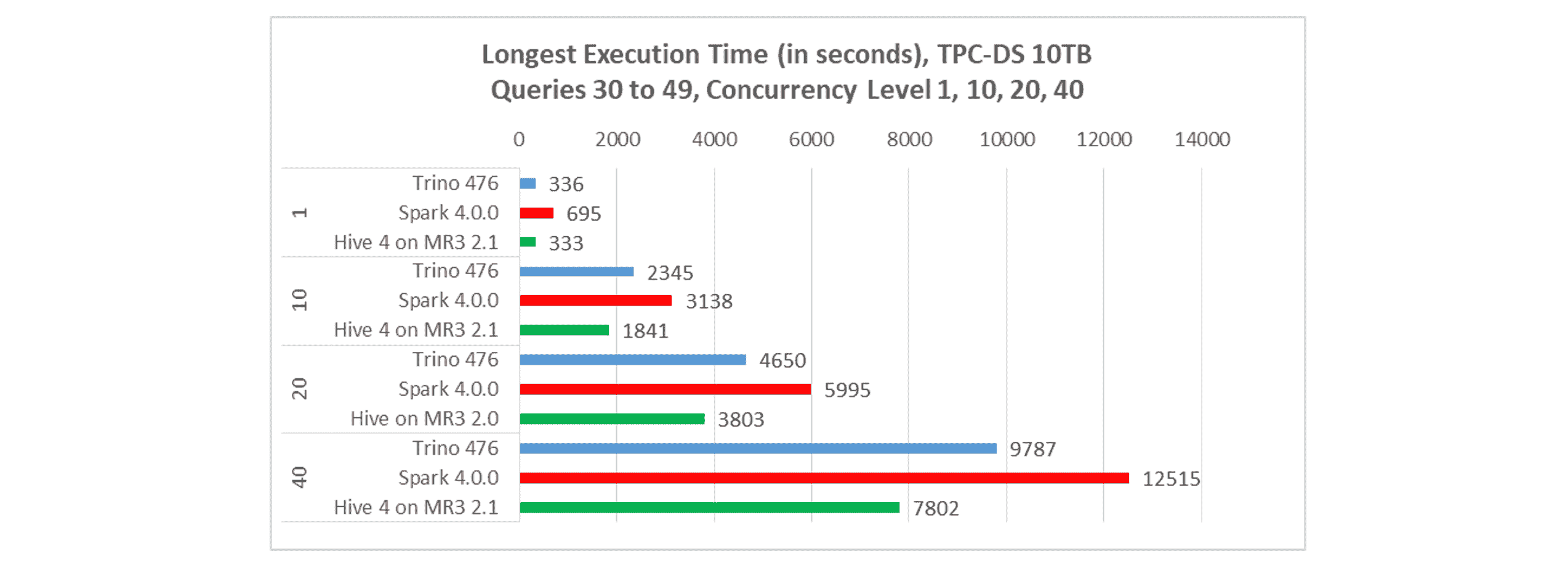
The results for a concurrency level of 1 are obtained from the sequential tests.
As in the previous article, Hive on MR3 consistently leads at all concurrency levels. For example, at a concurrency level of 40, Hive on MR3 is 25.4% faster than Trino and 60.4% faster than Spark.
Standard deviation of query execution times
To evaluate fairness and consistency in resource allocation under concurrency, we measure the standard deviation of query execution times from the longest-running client.
The following graph shows standard deviations from the concurrent tests.

As in the previous article, Hive on MR3 shows the lowest standard deviation across all concurrency levels, indicating that it delivers the most balanced query execution.
Conclusions
The fact that Hive on MR3 matches Trino in speed is significant from an architectural perspective. Below we explain why.

MPP architecture and push model
For a long time, there has been a consensus in industry that the MPP (Massively Parallel Processing) architecture, in conjunction with the push model for shuffling data from producers to consumers, is the de facto approach for building high-performance query engines. Unsurprisingly, most of the popular query engines follow this architecture — including Presto, Trino, Impala, and Dremio — all emphasizing execution speed as their primary strength. Trino even claims to “run at ludicrous speed” on its official website!
The MPP architecture along with the push model, however, makes it difficult to implement fault tolerance reliably. It is not uncommon to see MPP-based query engines simply ignore the issue, opting to re-execute the entire query if any failure occurs. Even so, engineers often find ways to work around such architectural limitations. For example, Trino now provides support for fault tolerance by materializing intermediate data on distributed storage. In short, the MPP architecture has benefited from its inherent performance advantage from the very beginning and is now evolving toward supporting fault tolerance.
MapReduce architecture and pull model
At the other end of the spectrum is the MapReduce architecture, coupled with the pull model for fetching data from producers to consumers. Because intermediate data is written to local disks, this architecture naturally supports fault tolerance and is often considered as the only viable choice when fault tolerance is essential. Hadoop MapReduce, Spark, Tez, and MR3 belong to this category, all providing fault tolerance at the architectural level.
The MapReduce architecture along with the pull model, however, has an inherent performance problem. Around 2010 (before the release of Spark and Tez), there was an active debate in academia about the future of the MapReduce architecture. At the time, it was unclear whether it would fade away due to performance issues or endure thanks to its strong support for fault tolerance.
- Pavlo et al. (A Comparison of Approaches to Large-scale Data Analysis, SIGMOD 2009) point out that Hadoop MapReduce has a serious performance problem related to the pull model.
- Dean and Ghemawat (MapReduce: A Flexible Data Processing Tool, Communications of the ACM, 2010) acknowledge that the pull model has a performance problem, but argue that the push model is inappropriate because of the requirement of fault tolerance.
- Stonebraker et al. (MapReduce and Parallel DBMSs: Friends or Foes?, Communications of the ACM, 2010) predict that the pull model is fundamental to fault tolerance and thus unlikely to be changed in Hadoop MapReduce.
Fast forward to 2025, we now know that the MapReduce architecture has survived, but its performance problem still persists. For example, Spark, once touted as a lightning-fast replacement for MapReduce, is no match for Trino when it comes to executing SQL queries, as clearly demonstrated in our experimental results. Therefore the MapReduce architecture should evolve in the opposite way from the MPP architecture by focusing on improving performance without compromising fault tolerance.
MR3: The best of both MPP and MapReduce worlds
Hive on MR3 demonstrates that a system based on the MapReduce architecture can achieve execution speed typically associated with the MPP architecture. For example, MR3 implements architectural optimizations that mirror techniques commonly taken for granted in MPP-based systems, such as storing intermediate data in memory rather than materializing it on local disks. At the same time, MR3 preserves the fault tolerance inherent to the MapReduce architecture. In this way, MR3 effectively combines the performance characteristics of MPP with the reliability of MapReduce, thereby offering the best of both worlds.
Hive on MR3 runs on Hadoop, on Kubernetes, and in standalone mode. Visit the Quick Start Guides to try Hive on MR3.