Troubleshooting
General
java.lang.OutOfMemoryError
There is no universal solution to the problem of OutOfMemoryError.
Here is a list of suggestions for reducing memory pressure in MR3.
- Increase the amount of memory allocated to each mapper, reducer, or ContainerWorker. See Resource Configuration.
- To avoid using free memory to store shuffle output (when pipelined shuffling is enabled),
set
tez.runtime.use.free.memory.writer.outputto false intez-site.xml. See Memory Setting for more details. - To avoid using free memory to store shuffle input,
set
tez.runtime.use.free.memory.fetched.inputto false intez-site.xml. Iftez.runtime.use.free.memory.fetched.inputshould be set to true, settez.runtime.free.memory.factor.for.fetched.inputto a smaller value (e.g., 2.0 instead of 6.0). See Memory Settings for more details. - If the execution fails with
OutOfMemoryErrorfromPipelinedSorter.allocateSpace(), the value of the configuration keytez.runtime.io.sort.mbintez-site.xmlis too large for the amount of available memory. See Memory Setting for more details. - If
OutOfMemoryErroroccurs during ordered shuffle, try a smaller value fortez.runtime.shuffle.merge.percentintez-site.xml. - For executing batch queries, set
mr3.container.task.failure.num.sleepsto a non-zero value inmr3-site.xml. See OutOfMemoryError.
Map Vertexes get stuck in the state of Initializing.
Sometimes a Map Vertex may get stuck in the state of Initializing for a long time
while generating InputSplits in DAGAppMaster.
This usually occurs when DAGAppMaster scans a huge number of input files,
especially if input data is stored on S3.
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 llap Initializing -1 0 0 -1 0 0
Reducer 2 llap New 4 0 0 4 0 0
Reducer 3 llap New 1 0 0 1 0 0
In such a case, the user can try the following approaches.
- Merge input files if there are many small input files.
- Set
hive.exec.orc.split.strategytoBIinhive-site.xml. - If input data is stored on S3,
- increase values for
mapreduce.input.fileinputformat.list-status.num-threadsandhive.exec.input.listing.max.threads(either inside Beeline connections or by restarting HiveServer2). Here we assume that DAGAppMaster is allocated enough CPU resources. - adjust the value for
fs.s3a.block.sizeincore-site.xml.
- increase values for
A query fails with too many fetch failures.
A query may fail after fetch failures:
Caused by: java.io.IOException: Map_1: Shuffle failed with too many fetch failures and insufficient progress! failureCounts=1, pendingInputs=1, fetcherHealthy=false, reducerProgressedEnough=true, reducerStalled=true
In the following example,
Map 1 initially succeeds, but later reruns its Tasks because Reducer 2 experiences many fetch failures.
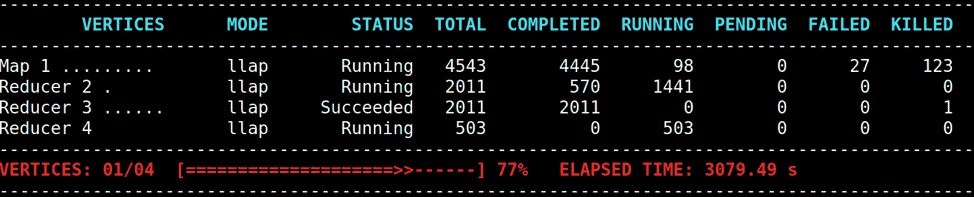
In such a case, the user can try to reduce the chance of fetch failures or recover from fetch failures as follows.
- Enable pipelined shuffling and use free memory to store shuffle input/output so as to minimize disk access.
- Decrease the value of the configuration key
tez.runtime.shuffle.total.parallel.copiesintez-site.xml(e.g., from 360 to 180) to reduce the total number of concurrent fetchers in each ContainerWorker. - Decrease the value of the configuration key
tez.runtime.shuffle.parallel.copiesintez-site.xml(e.g., from 10 to 5) to reduce the number of fetchers per LogicalInput (all of which run in parallel). This achieves the effect of reducing the load on the side of shuffle handlers because fewer requests are simultaneously made from reducers. - Increase the value of the configuration key
tez.runtime.shuffle.connect.timeoutintez-site.xml(e.g., to 17500) if connection attempts fail frequently.
See Shuffle Configuration for more details.
Generating a large table fails with fetch failures.
Using free memory to store shuffle input/output can fail queries generating large tables. In such a case, try to disable free memory to store shuffle input/output. Disabling pipelined shuffling can also help.
Map Vertexes generate too many tasks and downstream Vertexes get stuck or fail with OutOfMemoryError.
If the number of mappers of a Map Vertex becomes a performance problem
(e.g., due to too many shuffle requests generated by downstream reducers),
the user can adjust the configuration keys tez.grouping.min-size and tez.grouping.max-size
to reduce the number of mappers.
Alternatively the user can directly set the configuration key tez.grouping.split-count
to the desired number of mappers.
This is especially important when mappers generate Bloom filters,
whose size remains constant regardless of the total number of mappers.
In such a case,
the execution time of downstream reducers is nearly proportional to the number of mappers,
so setting tez.grouping.split-count to a smaller value has an immediate effect.
MR3 DAGAppMaster shows moderate to high CPU usage even when it is idle.
This is usually the case when many ContainerWorkers are running in a large cluster.
Every ContainerWorker attempts to obtain the next command to execute
by sending a message to DAGAppMaster
at a regular interval specified by the configuration key mr3.container.busy.wait.interval.ms.
By default,
ContainerWorkers contact DAGAppMaster every 25 milliseconds,
sending approximately 40 messages per second.
When DAGAppMaster is idle (processing no DAGs),
its CPU usage is mainly due to processing these messages from ContainerWorkers.
In a large cluster with many ContainerWorkers,
The user can increase the value of mr3.container.busy.wait.interval.ms
(e.g., to 100) to reduce CPU usage.
The first query executed after starting Hive on MR3 does not use task location hints.
MR3 uses task location hints where ContainerWorkers are currently running.
For example, a task location hint 'foo' is valid
only if a ContainerWorker is currently running on node 'foo'.
As a result, the counter HOST_LOCAL_TASK_ATTEMPTS is 0 (or close to 0)
for any query executed when no ContainerWorkers are running.
A query calling UDFs or using JdbcStorageHandler fails with ClassNotFoundException.
If the configuration key mr3.am.permit.custom.user.class is set to false for security reasons,
InputInitializer, VertexManager, or OutputCommitter running inside DAGAppMaster
may not use custom Java classes.
Hence
a query calling UDFs or using JdbcStorageHandler may try to load custom Java classes and generate ClassNotFoundException.
To prevent ClassNotFoundException in such a case,
set mr3.am.permit.custom.user.class to true in mr3-site.xml.
Metastore does not collect all column statistics even with both hive.stats.autogather and hive.stats.column.autogather set to true.
The user should manually execute the analyze table command.
Loading a table fails with FileAlreadyExistsException.
An example of FileAlreadyExistsException is:
Caused by: org.apache.hadoop.fs.FileAlreadyExistsException: Failed to rename s3a://hivemr3/warehouse/tpcds_bin_partitioned_orc_1000.db/.hive-staging_hive_2023-05-17_07-37-59_392_7290354321306036074-2/-ext-10002/000000_0/delta_0000001_0000001_0000/bucket_00000 to s3a://hivemr3/warehouse/tpcds_bin_partitioned_orc_1000.db/web_site/delta_0000001_0000001_0000/bucket_00000; destination file exists
This usually happens when speculative execution is enabled.
The user can disable speculative execution by setting the configuration key hive.mr3.am.task.concurrent.run.threshold.percent to 100.0 in hive-site.xml.
A query accessing S3 fails with SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool.
This can happen in DAGAppMaster executing InputInitializer, in which case the Beeline and DAGAppMaster generate such errors as:
### from Beeline
ERROR : FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Terminating unsuccessfully: Vertex failed, vertex_22169_0000_1_02, Some(RootInput web_sales failed on Vertex Map 1: com.datamonad.mr3.api.common.AMInputInitializerException: web_sales)Map 1 1 task 2922266 milliseconds: Failed
### from DAGAppMaster
Caused by: java.lang.RuntimeException: ORC split generation failed with exception: java.io.InterruptedIOException: Failed to open s3a://hivemr3-partitioned-2-orc/web_sales/ws_sold_date_sk=2451932/000001_0 at 14083 on s3a://hivemr3-partitioned-2-orc/web_sales/ws_sold_date_sk=2451932/000001_0: com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
This can also happen in ContainerWorkers, in which case ContainerWorkers generate such errors as:
...... com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
at org.apache.hadoop.fs.s3a.S3AUtils.translateInterruptedException(S3AUtils.java:340) ~[hadoop-aws-3.1.2.jar:?]
...
Caused by: com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
Depending on the settings for S3 buckets and the properties of datasets,
the user may have to adjust the values for the following configuration keys in core-site.xml.
- Increase the value of
fs.s3a.connection.maximum(e.g., to 2000 or higher) - Increase the value of
fs.s3a.threads.max - Increase the value of
fs.s3a.threads.core - Set
fs.s3a.blocking.executor.enabledto false
For more details, see Access to S3.
A non-deterministic query (i.e., one whose result can vary with each execution) may fail even when fault tolerance is enabled.
By default, MR3 assumes that DAGs consist of determinate Vertexes whose output is always the same given the same input. A non-deterministic query, however, produces a DAG with indeterminate Vertexes whose output can vary across executions.
To handle such cases, the user must inform MR3 of the presence of indeterminate Vertexes
by setting the configuration key hive.mr3.dag.include.indeterminate.vertex to true.
Note that fault tolerance is not supported for these DAGs when fetch failures occur.
Iceberg
Loading Iceberg tables fails.
An example of an error message is:
org.apache.iceberg.exceptions.NotFoundException: Can not read or parse commitTask manifest file: hdfs://kbhadoop01:9000/hivemr3/warehouse/blacklight.db/monthly_question_i/temp/hive_20250508170807_7d7e1f3e-8bf3-4b7a-80fa-205d2cb48a7b-job_80331_0000/task-584.forCommit
This can happen when speculative execution is enabled.
The user can disable speculative execution by setting the configuration key hive.mr3.am.task.concurrent.run.threshold.percent to 100.0 in hive-site.xml.
On Hadoop
A query accessing HDFS fails with org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block.
A query accessing HDFS may fail with BlockMissingException:
java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: java.io.IOException: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1848301428-10.1.90.9-1589952347981:blk_1078550925_4810302 file=/tmp/tpcds-generate/10000/catalog_returns/data-m-08342
...
Caused by: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1848301428-10.1.90.9-1589952347981:blk_1078550925_4810302 file=/tmp/tpcds-generate/10000/catalog_returns/data-m-08342
at org.apache.hadoop.hdfs.DFSInputStream.refetchLocations(DFSInputStream.java:875)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:858)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:837)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:566)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:756)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:825)
at java.io.DataInputStream.read(DataInputStream.java:149)
...
This error can occur even when the HDFS block is actually available.
It usually occurs when the date warehouse contains too many small files.
For Hive 3 on MR3,
the user should set the configuration key hive.optimize.sort.dynamic.partition to true
before creating new tables.
Setting hive.merge.tezfiles to true also helps to avoid creating too many small files.
This error can be also the result of using too small values for a few configuration keys. For example, the user can try adjusting the following configuration keys.
hive.exec.max.dynamic.partitions.pernode(e.g., from the default value of 1000 to 100000)hive.exec.max.dynamic.partitions(e.g., from the default value of 100 to 100000)
On Kubernetes
Metastore fails to find a database connector jar file with ClassNotFoundException.
If Metastore fails to find a database connector jar file, it prints error messages like:
2020-07-18T04:03:14,856 ERROR [main] tools.HiveSchemaHelper: Unable to find driver class
java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
The classpath of Metastore includes the directories /opt/mr3-run/lib and /opt/mr3-run/host-lib
inside the Metastore Pod,
and the user can place a custom database connector jar file in one of these two directories
as follows.
If a PersistentVolume is available,
the user can copy the database connector jar file
to the subdirectory lib in the PersistentVolume and
use PersistentVolumeClaim work-dir-volume in yaml/metastore.yaml.
Then the jar file is mounted in the directory /opt/mr3-run/lib inside the Metastore Pod.
vi yaml/metastore.yaml
spec:
template:
spec:
containers:
volumeMounts:
- name: work-dir-volume
mountPath: /opt/mr3-run/lib
subPath: lib
With Helm, the user should set metastore.mountLib to true in hive/values.yaml.
vi hive/values.yaml
metastore:
mountLib: true
If a PersistentVolume is not available (e.g., when using HDFS/S3 instead),
the user can mount it in the directory /opt/mr3-run/host-lib using a hostPath volume.
vi yaml/metastore.yaml
spec:
template:
spec:
containers:
volumeMounts:
- name: host-lib-volume
mountPath: /opt/mr3-run/host-lib
With Helm, hive/values.yaml should set metastore.hostLib to true
and set metastore.hostLibDir to a common local directory
containing the jar file on all worker nodes.
vi hive/values.yaml
metastore:
hostLib: true
hostLibDir: "/home/ec2-user/lib"
DAGAppMaster Pod does not start because mr3-conf.properties does not exist.
MR3 generates a property file mr3-conf.properties from ConfigMap mr3conf-configmap-master
and mounts it inside DAGAppMaster Pod.
If DAGAppMaster Pod fails with the following error message,
it means that either ConfigMap mr3conf-configmap-master is corrupt or mr3-conf.properties has not been generated.
2020-05-15T10:35:10,255 ERROR [main] DAGAppMaster: Error in starting DAGAppMasterjava.lang.IllegalArgumentException: requirement failed: Properties file mr3-conf.properties does not exist
In such a case, try again after manually deleting ConfigMap mr3conf-configmap-master
so that Hive on MR3 can start without a ConfigMap of the same name.
ContainerWorker Pods never get launched.
Try adjusting the resource for DAGAppMaster and ContainerWorker Pods.
In conf/mr3-site.xml, the user can adjust the resource for the DAGAppMaster Pod.
<property>
<name>mr3.am.resource.memory.mb</name>
<value>16384</value>
</property>
<property>
<name>mr3.am.resource.cpu.cores</name>
<value>2</value>
</property>
In conf/hive-site.xml, the user can adjust the resource for ContainerWorker Pods.
<property>
<name>hive.mr3.all-in-one.containergroup.memory.mb</name>
<value>16384</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.vcores</name>
<value>2</value>
</property>
A query accessing S3 makes no progress because Map vertexes get stuck in the state of Initializing.
If DAGAppMaster fails to resolve host names, the execution of a query may get stuck in the following state:

In such a case, check if the configuration key mr3.k8s.host.aliases is set properly in conf/mr3-site.xml.
For example, if the user sets the environment variable HIVE_DATABASE_HOST in env.sh to the host name (instead of the address) of the MySQL server,
its address should be specified in mr3.k8s.host.aliases.
Internally the class AmazonS3Client (running inside InputInitializer of MR3) throws an exception java.net.UnknownHostException,
which, however, is swallowed and never propagated to DAGAppMaster.
As a consequence, no error is reported and the query gets stuck.
A query fails with DiskErrorException: No space available in any of the local directories.
A query may fail with DiskErrorException:
ERROR : Terminating unsuccessfully: Vertex failed, vertex_2134_0000_1_01, Some(Task unsuccessful: Map 1, task_2134_0000_1_01_000000, java.lang.RuntimeException: org.apache.hadoop.util.DiskChecker$DiskErrorException: No space available in any of the local directories.
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:370)
...
Caused by: org.apache.hadoop.util.DiskChecker$DiskErrorException: No space available in any of the local directories.
In such a case, check if the configuration key mr3.k8s.pod.worker.hostpaths in conf/mr3-site.xml is properly set, e.g.:
<property>
<name>mr3.k8s.pod.worker.hostpaths</name>
<value>/data1/k8s,/data2/k8s,/data3/k8s,/data4/k8s,/data5/k8s,/data6/k8s</value>
</property>
In addition, check if the directories listed in mr3.k8s.pod.worker.hostpaths are writable to the user with UID 1000.
Kerberos on Kubernetes
Metastore fails with javax.security.auth.login.LoginException: ICMP Port Unreachable.
If the KDC is not set properly, Metastore may fail with LoginException:
Exception in thread "main" org.apache.hadoop.security.KerberosAuthException: failure to login: for principal: hive/admin@PL from keytab /opt/mr3-run/key/hive-admin.keytab javax.security.auth.login.LoginException: ICMP Port Unreachable
This error usually occurs when Metastore cannot reach the KDC server via ports 88 and 749. In particular, make sure that the KDC server is reachable via UDP ports 88 and 749 as well as TCP ports 88 and 749.
Beeline fails with org.ietf.jgss.GSSException.
Beeline may fail with GSSException even if a valid Kerberos ticket is available:
javax.security.sasl.SaslException: GSS initiate failed
...
Caused by: org.ietf.jgss.GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)
at sun.security.jgss.krb5.Krb5InitCredential.getInstance(Krb5InitCredential.java:147) ~[?:1.8.0_112]
at sun.security.jgss.krb5.Krb5MechFactory.getCredentialElement(Krb5MechFactory.java:122) ~[?:1.8.0_112]
at sun.security.jgss.krb5.Krb5MechFactory.getMechanismContext(Krb5MechFactory.java:187) ~[?:1.8.0_112]
at sun.security.jgss.GSSManagerImpl.getMechanismContext(GSSManagerImpl.java:224) ~[?:1.8.0_112]
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:212) ~[?:1.8.0_112]
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:179) ~[?:1.8.0_112]
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:192) ~[?:1.8.0_112]
In such a case,
adding a Java option -Djavax.security.auth.useSubjectCredsOnly=false may work.
KrbApErrException: Message stream modified or KrbException: Message stream modified
Because of a bug in Kerberos,
Hive on MR3 may fail to authenticate even with valid keytab files.
In such a case, it usually prints an error message KrbApErrException: Message stream modified.
org.apache.hive.service.ServiceException: Unable to login to kerberos with given principal/keytab
...
Caused by: org.apache.hadoop.security.KerberosAuthException: failure to login: for principal: hive/gold7@PL from keytab /opt/mr3-run/key/hive.service.keytab javax.security.auth.login.LoginException: Message stream modified (41)
...
Caused by: sun.security.krb5.internal.KrbApErrException: Message stream modified (41)
at sun.security.krb5.KrbKdcRep.check(KrbKdcRep.java:101) ~[?:1.8.0_242]
at sun.security.krb5.KrbAsRep.decrypt(KrbAsRep.java:159) ~[?:1.8.0_242]
at sun.security.krb5.KrbAsRep.decryptUsingKeyTab(KrbAsRep.java:121) ~[?:1.8.0_242]
at sun.security.krb5.KrbAsReqBuilder.resolve(KrbAsReqBuilder.java:308) ~[?:1.8.0_242]
at sun.security.krb5.KrbAsReqBuilder.action(KrbAsReqBuilder.java:447) ~[?:1.8.0_242]
at com.sun.security.auth.module.Krb5LoginModule.attemptAuthentication(Krb5LoginModule.java:780) ~[?:1.8.0_242]
The root cause of the bug is unknown
and the user should find a fix specific to the Docker image.
The user can try a workaround by removing the setting for renew_lifetime in krb5.conf.
vi conf/krb5.conf
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
forwardable = true
# renew_lifetime = 7d
rdns = false
default_realm = RED
default_ccache_name = /tmp/krb5cc_%{uid}
DAGAppMaster prints error messages with User ... cannot perform AM view operations.
A mismatch between the user in DOCKER_USER
and the service name in HIVE_SERVER2_KERBEROS_PRINCIPAL in env.sh
makes HiveServer2 unable to establish a connection to DAGAppMaster.
In such a case, DAGAppMaster keeps printing error messages like:
2019-07-04T09:42:17,074 WARN [IPC Server handler 0 on 8080] ipc.Server: IPC Server handler 0 on 8080, call Call#32 Retry#0 com.datamonad.mr3.master.DAGClientHandlerProtocolBlocking.getSessionStatus from 10.43.0.0:37962
java.security.AccessControlException: User gitlab-runner/indigo20@RED (auth:TOKEN) cannot perform AM view operations
at com.datamonad.mr3.master.DAGClientHandlerProtocolServer.checkAccess(DAGClientHandlerProtocolServer.scala:239) ~[mr3-tez-0.1-assembly.jar:0.1]
at com.datamonad.mr3.master.DAGClientHandlerProtocolServer.checkViewAccess(DAGClientHandlerProtocolServer.scala:233) ~[mr3-tez-0.1-assembly.jar:0.1]
...
If permission checking is disabled in DAGAppMaster, ContainerWorkers print error messages like:
2020-08-16T16:34:01,019 ERROR [Tez Shuffle Handler Worker #1] shufflehandler.ShuffleHandler: Shuffle error :
java.io.IOException: Owner 'root' for path /data1/k8s/dag_1/container_K@1/vertex_3/attempt_70888998_0000_1_03_000000_0_10003/file.out did not match expected owner 'hive'
at org.apache.hadoop.io.SecureIOUtils.checkStat(SecureIOUtils.java:281) ~[hadoop-common-3.1.2.jar:?]
See Kerberos authentication on Kubernetes for more details.
When using encrypted (Kerberized) HDFS, executing a query with no input files fails with AccessControlException.
If encrypted HDFS is used, creating a fresh table or inserting values to an existing table may fail, while executing queries that only read data works okay.
... org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
...
This error occurs if the configuration key hive.mr3.dag.additional.credentials.source
is not set in hive-site.xml.
See Accessing HDFS for details.
A similar error can occur inside DAGAppMaster while generating splits. (The log of DAGAppMaster reports credentials associated with each DAG.)
2023-08-31 15:24:19,402 [main] INFO ContainerWorker [] - Credentials for Y@container_1694103365516_0016_01_000004: SecretKeys = 0, Tokens = 2: List(HDFS_DELEGATION_TOKEN, mr3.job)
...
2023-08-31 16:19:08,183 [DAG1-Input-4-3] WARN org.apache.hadoop.ipc.Client [] - Exception encountered while connecting to the server : org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
2023-08-31 16:19:08,195 [DAG1-Map 1] ERROR Vertex [] - RootInput order_detail failed on Vertex Map 1
com.datamonad.mr3.api.common.AMInputInitializerException: order_detail
at
...
Caused by: java.io.IOException: org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
In such a case,
check if the configuration key dfs.encryption.key.provider.uri
or hadoop.security.key.provider.path is set in core-site.xml.
See Accessing HDFS for details.
Ranger
HiveServer2 throws NullPointerException when downloading Ranger policies, and Beeline cannot execute queries.
HiveServer2 fails to download Ranger policies and generates NullPointerException:
2020-10-08T12:23:08,872 ERROR [Thread-6] util.PolicyRefresher: PolicyRefresher(serviceName=ORANGE_hive): failed to refresh policies. Will continue to use last known version of policies (-1)
com.sun.jersey.api.client.ClientHandlerException: java.lang.RuntimeException: java.lang.NullPointerException
...
Caused by: java.lang.NullPointerException
Beeline fails to execute queries due to a lack of privileges:
0: jdbc:hive2://orange1:9852/> use tpcds_bin_partitioned_orc_1003;
Error: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [gitlab-runner] does not have [USE] privilege on [tpcds_bin_partitioned_orc_1000] (state=42000,code=40000)
These errors may disappear
after setting policy.download.auth.users to include the user of HiveServer2 in the Config Properties panel.

Test Connection fails in the Config Properties panel.
Check if the jdbc.url field is set properly.
Examples are:
jdbc:hive2://indigo20:9852/when neither Kerberos nor SSL is used.jdbc:hive2://indigo20:9852/;principal=hive/indigo20@RED;when Kerberos is used.jdbc:hive2://indigo20:9852/;principal=hive/indigo20@RED;ssl=true;sslTrustStore=/opt/mr3-run/ranger/key/hivemr3-ssl-certificate.jks;when both Kerberos and SSL are used.
Apache Ranger Admin Service fails to start.
In order to find out the cause of the failure, check out the file catalina.out
in the Ranger container (not the Solr container) inside the Ranger Pod.
In the following example, Admin Service fails to start because a wrong Kerberos keytab file is provided.
kubectl exec -it -n hivemr3 hivemr3-ranger-0 -c ranger /bin/bash;
root@hivemr3-ranger-0:/opt/mr3-run/ranger# cat work-local-dir/log/ranger-admin/catalina.out
…
SEVERE: Tomcat Server failed to start:java.io.IOException: Login failure for rangeradmin/orange1@PL from keytab /opt/mr3-run/ranger/key/rangeradmin.keytab
java.io.IOException: Login failure for rangeradmin/orange1@PL from keytab /opt/mr3-run/ranger/key/rangeradmin.keytab
...
Caused by: java.security.GeneralSecurityException: Checksum failed
...