TPC-DS Benchmark: Trino 477 and Hive 4 on MR3 2.2

Since May 2023, we have been evaluating the performance of Trino and Hive on MR3 using the TPC-DS Benchmark. As we ran all experiments in the same cluster and with the same scale factor of 10TB, we can now observe steady performance improvements of both systems over the past two years. In our latest article, we report that Trino maintains the lead in average response time under sequential workloads, while Hive on MR3 consistently outperforms Trino under concurrent workloads.
Although we designed the comparison to be fair in all aspects, a correctness issue in Trino’s results for query 23 complicates the comparison slightly. Specifically Hive (as well as Spark) returns the following results for queries 23-1 and 23-2 (a single row for each query), whereas Trino returns empty rows:
| 41002.32 |
| Santos | Edward | 41002.32|
It is debatable, however, whether empty rows from Trino are incorrect results or still acceptable outcomes due to Trino's precision scheme for decimal division. In any case, Trino 477, its latest release, incorporates a patch (Improve decimal arithmetic operation type inference #26422) that aligns its behavior with Hive and Spark, and now we can evaluate the performance of Trino and Hive on MR3 without concerns about correctness.
In this article, we evaluate the performance of the latest versions:
- Trino 477 (released in September 2025)
- Hive 4.0.0 on MR3 2.2 (released in October 2025)
Our goal is to present a fair and up-to-date performance comparison between the two systems under identical conditions. We refer the reader to our previous article (April 2025) for a general introduction to Trino and Hive on MR3, and to our latest article (July 2025) for a comparison of their architectures.
Experiment Setup
We use exactly the same experiment setup as in the previous article. Trino runs on Java 24, and Hive on MR3 runs on Java 22. In particular, we reuse the same configuration parameters for Trino from the previous experiment. The scale factor for the TPC-DS benchmark is 10TB.
In a sequential test, we submit 99 queries from the TPC-DS benchmark. We report the total execution time, the average response time, and the execution time of each individual query. For average response time, we use the geometric mean of execution times, as it takes into account outlier queries that run unusually short or long.
In a concurrent test, we use a concurrency level of 10, 20, or 40 and start the same number of clients, each submitting queries 30 to 49 from the TPC-DS benchmark in a unique sequence. For each run, we measure the longest execution time among all clients.
Raw data of the experiment results
For the reader's perusal, we attach the table containing the raw data of the experiment results. Here is a link to [Google Docs].
Analysis of sequential tests
Query completion
Both systems complete all queries successfully.
Correctness
Both systems return the same results for all queries.
Total execution time
In terms of total execution time, Hive on MR3 runs faster than Trino.
- Trino completes all queries in 4,470 seconds, up from 4,245 seconds in Trino 476.
- Hive on MR3 completes all queries in 4,160 seconds, down from 4,299 seconds in Hive 4 on MR3 2.1.
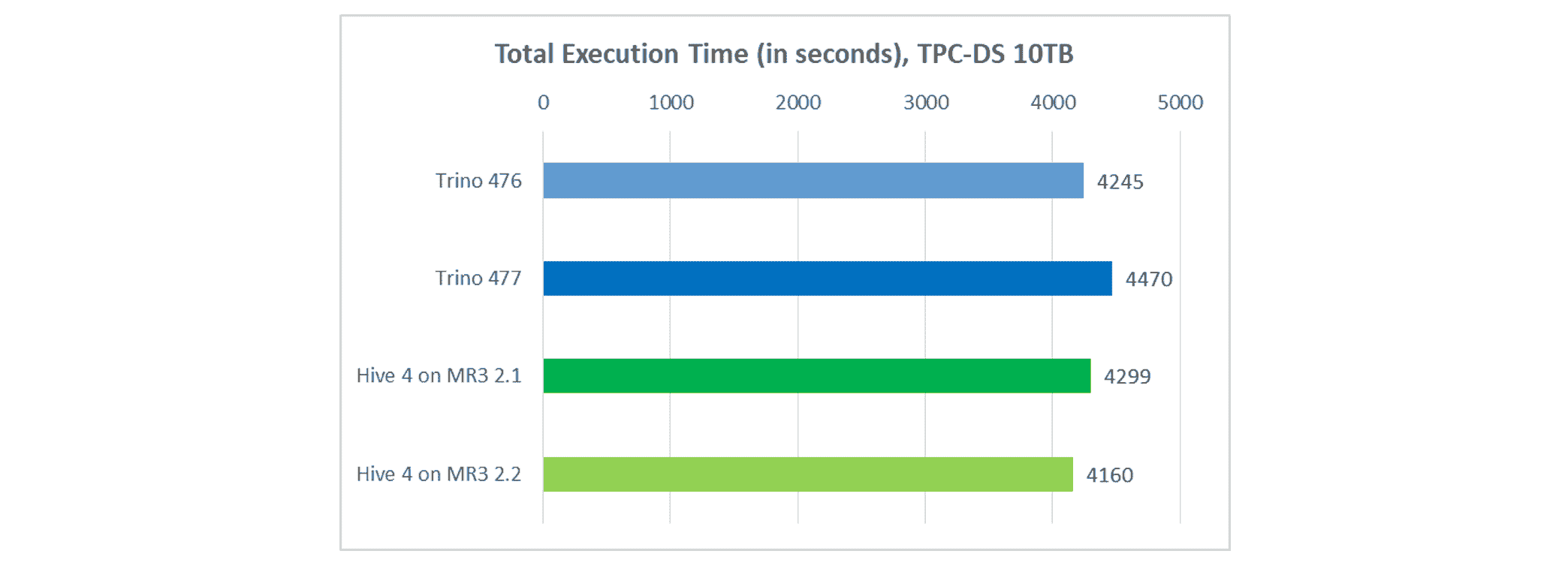
For Trino, a few queries take longer than in Trino 476, as shown in the following table (all times in seconds):
| Query | Trino 476 | Trino 477 |
|---|---|---|
| Query 4 | 120.968 | 156.66 |
| Query 23-1 | 317.117 | 360.526 |
| Query 23-2 | 319.522 | 370.114 |
| Query 54 | 135.835 | 159.989 |
| Query 97 | 147.187 | 171.158 |
As the patch (Improve decimal arithmetic operation type inference #26422) in Trino 477 specifically addresses the correctness issue in queries 23-1 and 23-2, the increase in the execution time may be related to this change.
The slight performance improvement of Hive on MR3 is due to a few optimizations in Hive query compilation.
Average response time
In terms of average response time, Trino remains faster.
- Trino completes each query in 17.11 seconds on average, down from 17.46 seconds in Trino 476.
- Hive on MR3 completes each query in 18.30 seconds on average, up from 17.84 seconds in Hive on MR3 2.1.
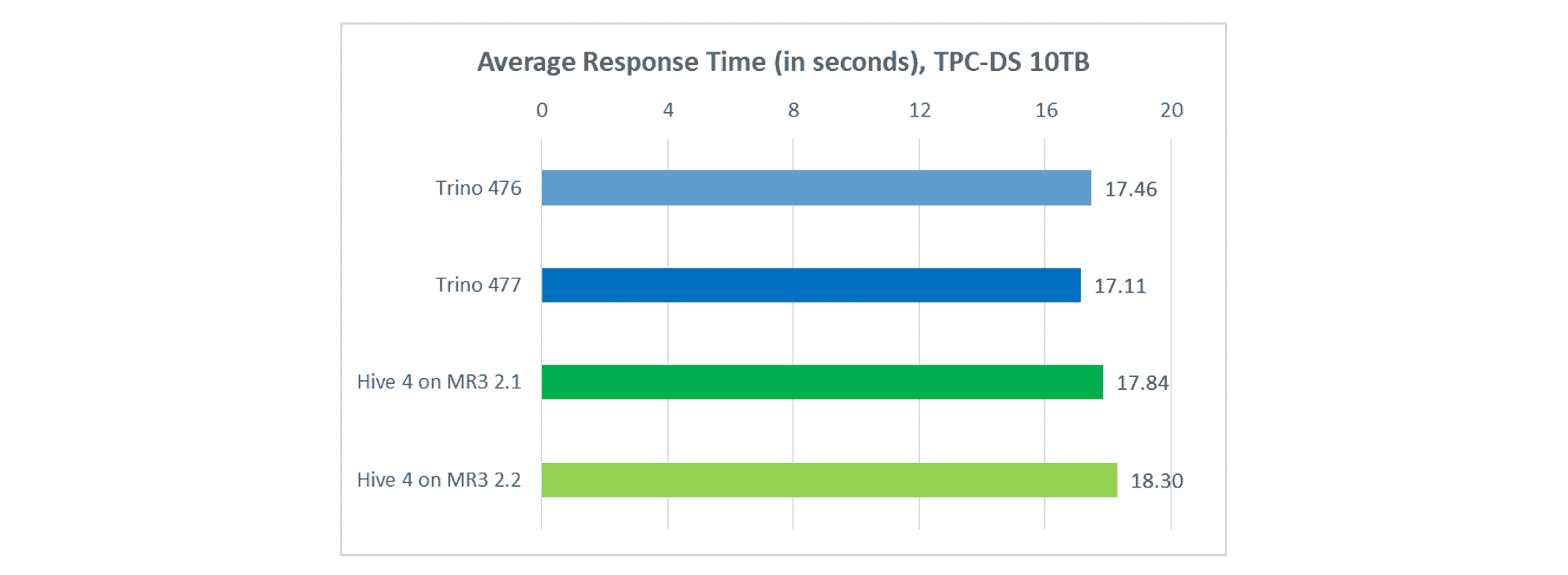
Compared with the previous versions, Trino shows is about 2 percent faster, while Hive on MR3 is about 2.5 percent slower, primarily because of an increase in query compilation overhead.
Analysis of concurrent tests
Query completion
Both systems successfully complete all queries at concurrency levels of 10, 20, and 40.
Longest execution time
In terms of longest execution time, Hive on MR3 remains faster. For concurrency levels of 10, 20, and 40:
- Trino completes all queries in 2,453, 4,867, and 10,099 seconds, respectively.
- Hive on MR3 completes all queries in 1,799, 3,749, and 7,527 seconds, respectively.
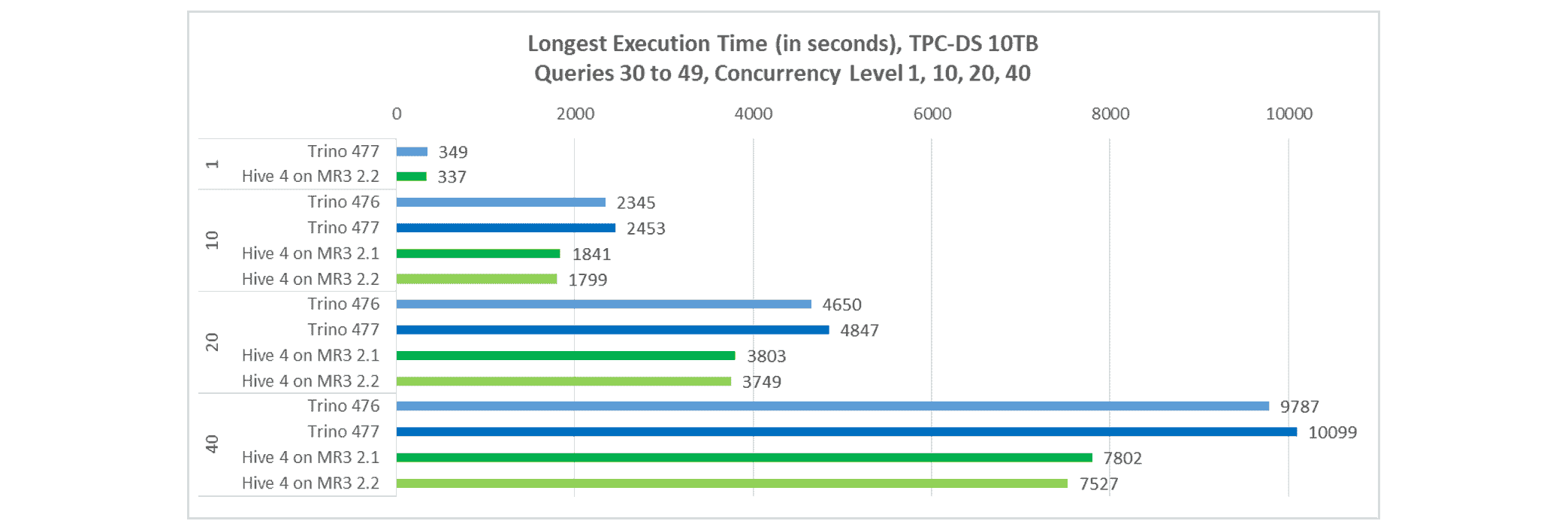
The results for a concurrency level of 1 are obtained from the sequential tests.
As in the previous article, Hive on MR3 consistently leads at all concurrency levels. The gap between Trino and Hive on MR3 is larger than in the previous experiments, as Trino is slower while Hive on MR3 is faster. For example, at a concurrency level of 40, Hive on MR3 is now 34.2% faster than Trino, up from 25.4% between Hive on MR3 2.1 and Trino 476.
Conclusions
Over the past two and a half years, both Trino and Hive on MR3 have made steady progress in improving performance. The following graphs show the changes in 1) total execution time and 2) geometric mean of execution times for the 10TB TPC-DS benchmark in the same cluster.
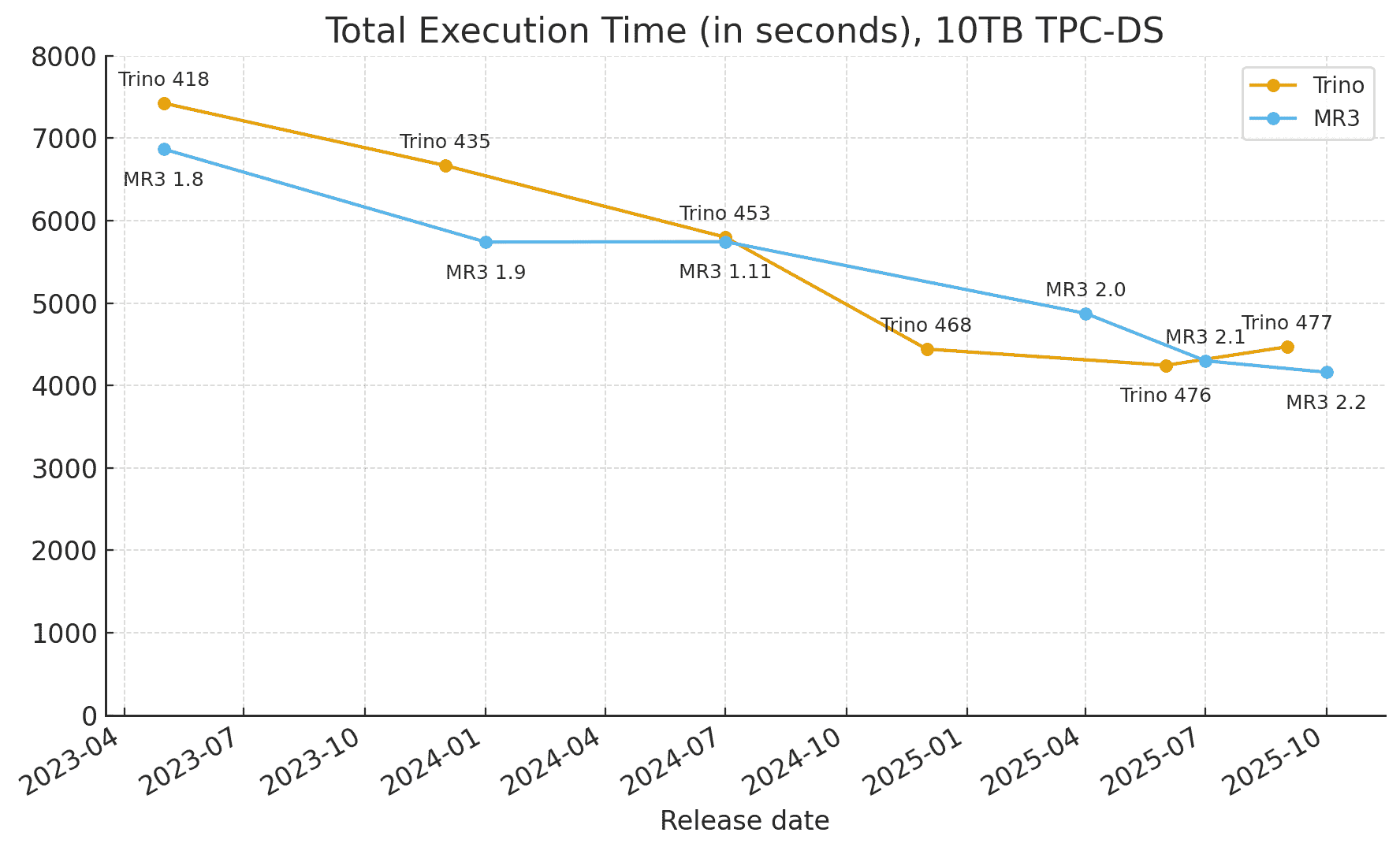
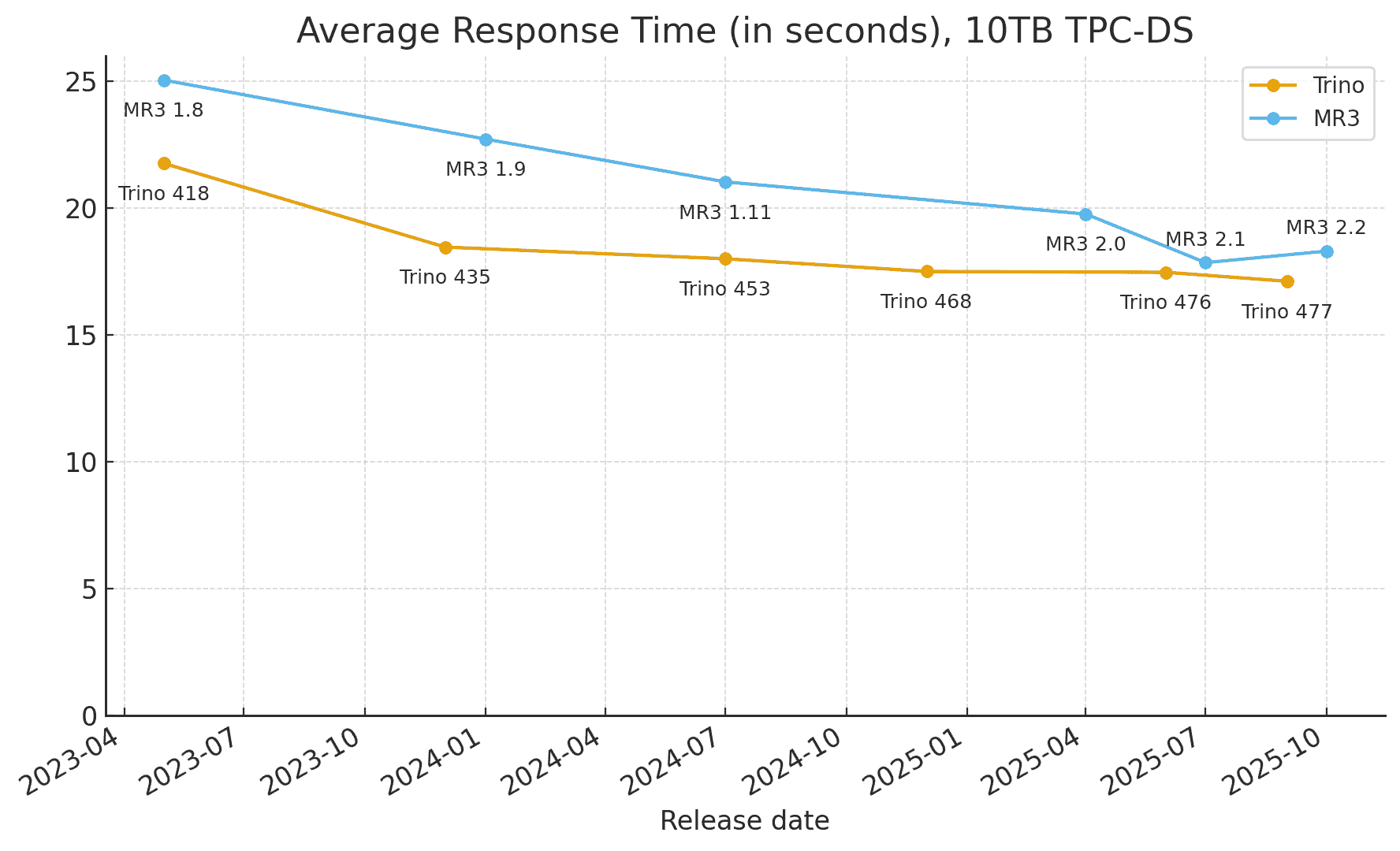
We observe that both Trino and Hive on MR3 have achieved remarkable reductions (about 40 percent) in total execution time:
- Trino: from about 7,400 seconds to 4,500 seconds;
- Hive: on MR3 from about 6,900 seconds to 4,200 seconds.
Our results demonstrate meaningful progress for both systems, with Trino continuing to lead in average response time and Hive on MR3 maintaining its advantage under concurrent workloads. We expect both systems to continue evolving, delivering further gains in efficiency in future releases.