Remote Shuffle Service
Remote shuffle service with Celeborn
Apache Celeborn is a remote shuffle service which enables MR3 to store intermediate data generated by mappers on Celeborn worker nodes, rather than on local disks. Reducers directly request Celeborn workers for intermediate data, thus eliminating the need for MR3 shuffle handlers (or the Hadoop shuffle service).
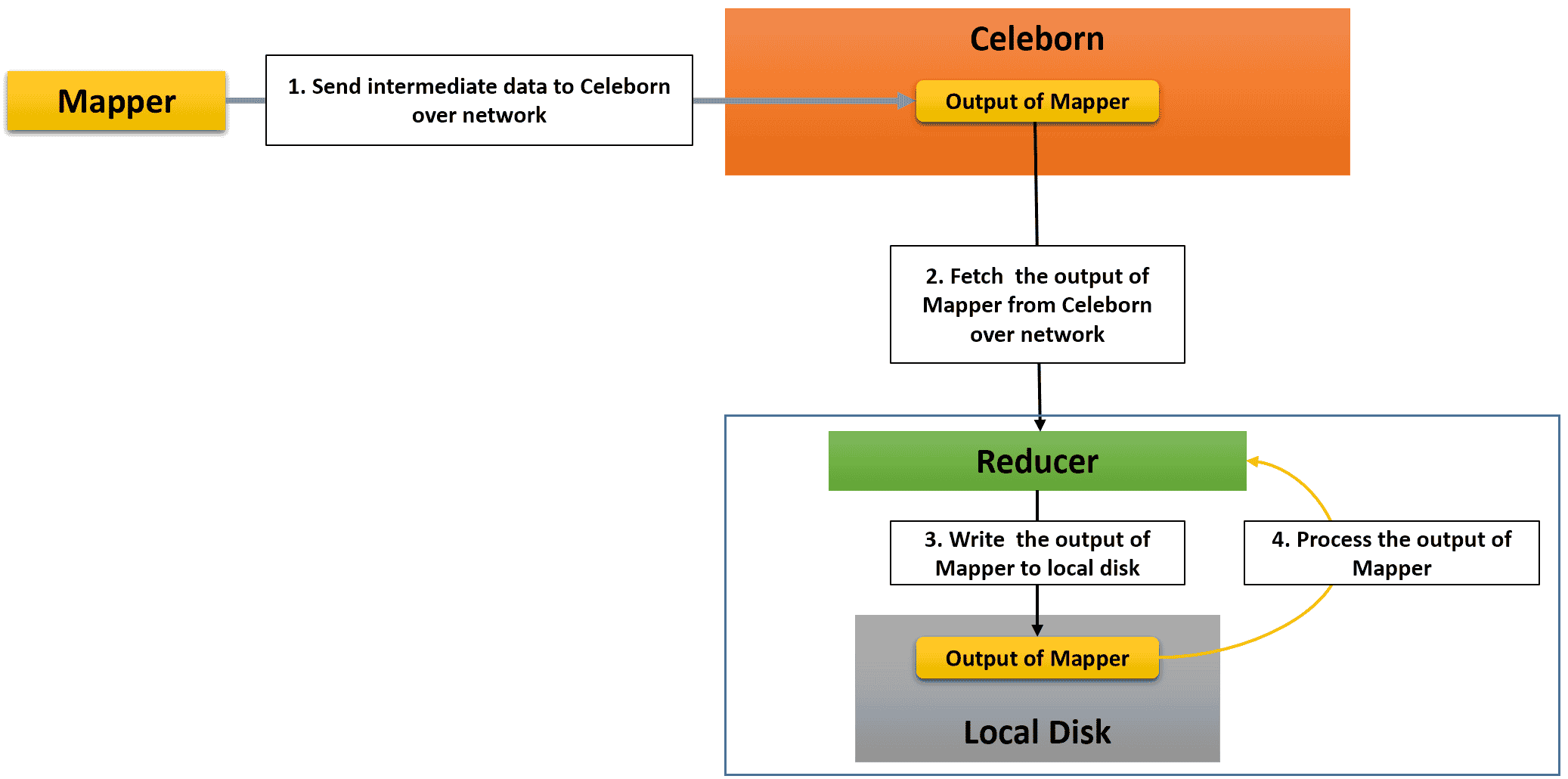
Since intermediate data is stored on Celeborn worker nodes instead of local disks, one of the key benefits of using Celeborn is that MR3 now needs only half as much space on local disks. Furthermore the use of Celeborn enables MR3 to directly process the output of mappers on the reducer side (skipping steps 3 and 4 in the above diagram), thus eliminating over 95% of writes to local disks when executing typical queries.
The lower requirement on local disk storage is particularly important when running MR3 on public clouds where 1) the total capacity of local disks attached to each node is limited and 2) attaching local disks is expensive.
Celeborn officially supports Spark and Flink. We have extended the runtime system of MR3 to use Celeborn for remote shuffle service.