DAG/Task Scheduling
In order to maximize throughput (i.e., the number of queries completed per unit time) or minimize turnaround time (i.e., the time from accepting a query to completing it), MR3 provides a sophisticated scheme for scheduling and executing Tasks originating from different DAGs. Internally MR3 proceeds through three stages before sending Tasks to ContainerWorkers for execution:
- Mapping DAGs to Task queues using DAGScheduler
- Assigning priorities to Tasks
- Scheduling Tasks in each Task queue using TaskScheduler
1. DAG scheduling
MR3 DAGScheduler uses the configuration key mr3.dag.queue.scheme to assign DAGs to Task queues.
The default value is common.
common(default): DAGScheduler uses a common Task queue for all DAGs.individual: DAGScheduler creates a Task queue for each individual DAG.capacity: DAGScheduler uses capacity scheduling.
If mr3.dag.queue.scheme is set to individual,
DAGScheduler tries to schedule a Task from the DAG
that is currently consuming the least amount of resources in terms of memory.
In this way, MR3 makes its best efforts to allocate the same amount of resources to all active DAGs.
Since a new DAG is instantly allocated its fair share of resources
while an old DAG is not penalized for its long duration,
the execution time of a DAG is predictable in concurrent environments.
For example,
if a DAG completes in 100 seconds with no concurrent DAGs,
it has a reasonable chance of completing in around 100 * 10 = 1000 seconds with 9 concurrent DAGs of the same structure.
In concurrent environments,
setting mr3.dag.queue.scheme to common usually achieves a higher throughput than setting it to individual.
This is because
the optimization implemented for increasing the temporal locality of intermediate data works best
when MR3 is allowed to analyze the dependency between Tasks of all DAGs at once.
For example,
when the entire input of a Task becomes available,
MR3 may decide to schedule it immediately even in the presence of many Tasks of higher priorities.
If mr3.dag.queue.scheme is set to individual, however,
the optimization is much less effective because
MR3 can analyze only the dependency between Tasks belonging to the same DAG.
In short,
setting mr3.dag.queue.scheme to common enables MR3 to globally optimize the execution of all DAGs
whereas setting it to individual does not.
Capacity scheduling
If mr3.dag.queue.scheme is set to capacity,
MR3 DAGScheduler uses capacity scheduling by managing multiple Task queues with different priorities and capacity requirements.
The user specifies the policy for capacity scheduling with another configuration key mr3.dag.queue.capacity.specs.
Each entry consists of the name of a Task queue and the minimum capacity in percentage.
Task queues are specified in the order of priority.
As an example,
setting mr3.dag.queue.capacity.specs to high=80,medium=50,default=20,background=0
is interpreted as follows.
- MR3 creates four Task queues (
high,medium,default,background) in the order of priority. That is, Task queuehighis assigned the highest priority while Task queuebackgroundis assigned the lowest priority. - Task queue
highis guaranteed 80 percent of resources. Idle resources not claimed byhigh, however, can be allocated to Task queues with lower priorities. - Task queue
mediumis guaranteed 50 percent of resources ifhighconsumes no more than 50% of resources. - Task queue
defaultis guaranteed 20 percent of resources ifhighandmediumconsume no more than 80% of resources. - Task queue
backgroundis guaranteed no resources at all. Hence it consumes resources only when no other Task queues request resources.
As another example,
assume that mr3.dag.queue.capacity.specs is set to high=40,medium=20,default=10,background=0.
After meeting capacity requirements of Task queues high, medium, and default,
30 percent of resources still remain.
In such a case,
MR3 allocates remaining resources to Task queues with higher priorities first.
As a result,
Task queue background is allocated no resources
as long as the other Task queues with higher priorities request the remaining 30 percent of resources.
As a special rule, if a Task queue default is not specified,
MR3 automatically appends default:0 to the value of mr3.dag.queue.capacity.specs.
For example,
foo=80,bar=20 is automatically expanded to foo=80,bar=20,default=0.
Hence a Task queue default is always available under capacity scheduling.
A DAG specifies its Task queue with the configuration key mr3.dag.queue.name
(which is effective only with capacity scheduling).
If a DAG chooses a non-existent Task queue or does not specify its Task queue,
it is assigned to the Task queue default.
DAGScheduler logs the status of capacity scheduling periodically
(every 10 seconds by default).
In the following example, we see that
Task queue high is consuming 36 percent of resources with 208 pending TaskAttempts.
2022-08-12T09:10:48,635 INFO [All-In-One] TaskAttemptQueue$: DAGScheduler All-In-One 2211840MB: high = 208/36%, medium = 2371/43%, default = 169/20%, background = 856/0%
MR3 never preempts TaskAttempts running in Task queues with lower priorities in order to find resources requested by Task queues with higher priorities. Hence even the Task queue with the highest priority may have to wait for a while if all the resources are being used by Tasks queues with lower priorities.
2. Assigning Task priorities
In MR3, the priority of a Task is determined by 1) the priority of its DAG and 2) the priority of its Vertex, where the DAG priority takes precedence over the Vertex priority. For example, Tasks with a higher DAG priority have higher priorities than Tasks with a lower DAG priority regardless of their Vertex priorities. For Tasks with the same DAG priority, TaskScheduler considers their Vertex priorities.
MR3 uses the configuration key mr3.dag.priority.scheme to assign DAG priorities.
The default value is fifo.
fifo(default): MR3 assign DAG priorities sequentially. That is, the first DAG is assigned DAG priority 0, the second DAG is assigned DAG priority 1, and so on.concurrent: MR3 assigns the same DAG priority to all DAGs.
If mr3.dag.queue.scheme is set to individual, the user may ignore mr3.dag.priority.scheme
because every DAG maintains its own Task queue.
MR3 uses another configuration key mr3.vertex.priority.scheme to update Vertex priorities.
The interpretation of the configuration key mr3.vertex.priority.scheme is as follows.
intact: MR3 does not update Vertex priorities already specified in the DAG.roots: MR3 recalculates Vertex priorities based on the distance from root Vertexes that read input data.leaves: MR3 recalculates Vertex priorities based on the distance to leaf Vertexes that produce output data.postorder(default): MR3 recalculates Vertex priorities based on the postorder traversal of the DAG.normalize: MR3 normalizes Vertex priorities in the range between 0 and 12252240 (2^4 * 3^2 * 5 * 7 * 11 * 13 * 17, a highly composite number).
The precise definition of roots/leaves/postorder/normalize is a lot more subtle than it appears
because in general, DAGs are not single-rooted trees.
For our purpose, we content ourselves with an example that shows the result of assigning Vertex priorities to the same DAG.
The following diagram shows the result of assigning Vertex priorities to a DAG that Hive on MR3 generates
from query 44 of the TPC-DS benchmark.
Note that in the case of postorder, all Vertexes have different priorities.
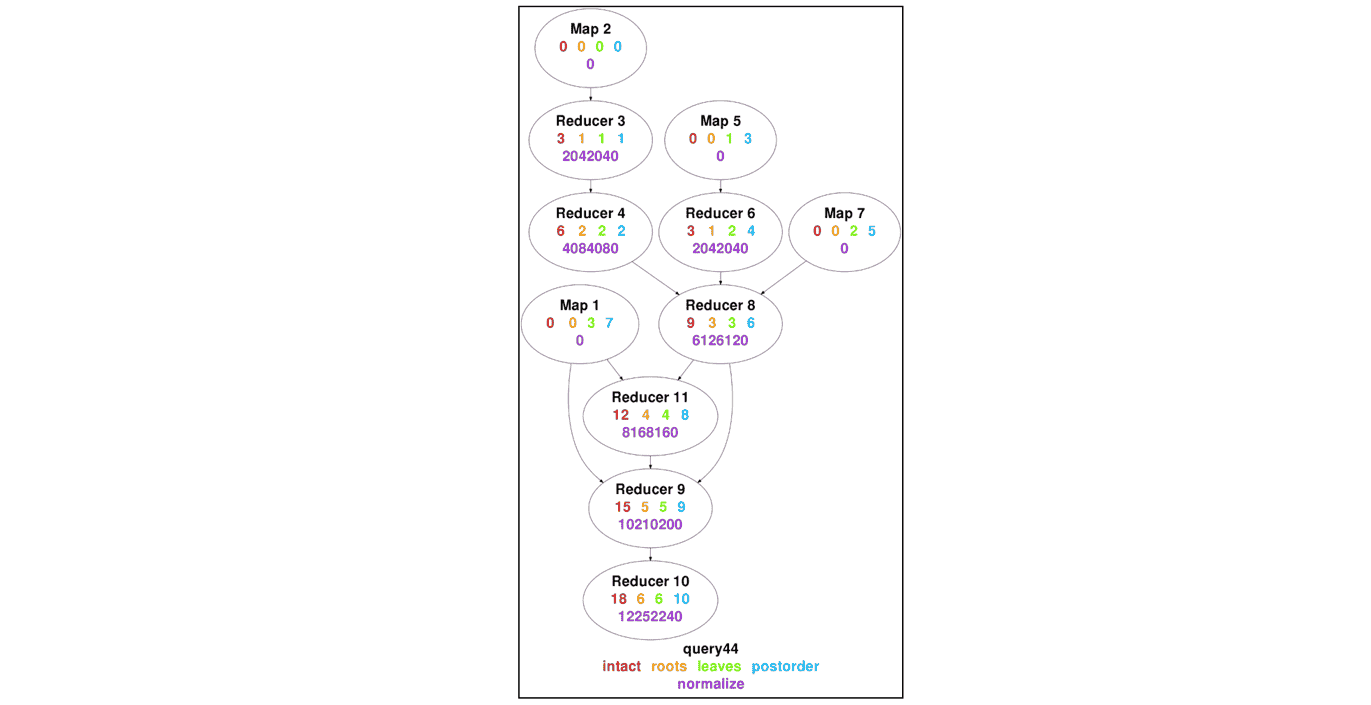
The default value of mr3.vertex.priority.scheme is postorder
as it typically achieves the highest throughput.
Intuitively postorder attempts to execute a Task
immediately after all of its producer Tasks have completed,
thereby increasing the temporal locality of intermediate data shuffled between Tasks.
Experiment 1. Every Beeline client submits the same set of queries.
In the first experiment, we run 16 Beeline clients each of which submits 17 queries, query 25 to query 40, from the TPC-DS benchmark. (The scale factor for the TPC-DS benchmark is 10TB.) When executed sequentially, these queries complete in 46 seconds on average while the longest-running query takes about 110 seconds. In order to better simulate a realistic environment, each Beeline client submits these 17 queries in a unique sequence.
The following graph shows the progress of every Beeline client (where the y-axis denotes the elapsed time). Each color corresponds to a unique query across all Beeline clients.
- We set
mr3.dag.queue.schemetocommon. - The graph labeled
fifosetsmr3.dag.priority.schemetofifoandmr3.vertex.priority.schemetointact. - Every remaining graph sets
mr3.dag.priority.schemetoconcurrentandmr3.vertex.priority.schemeto its label.
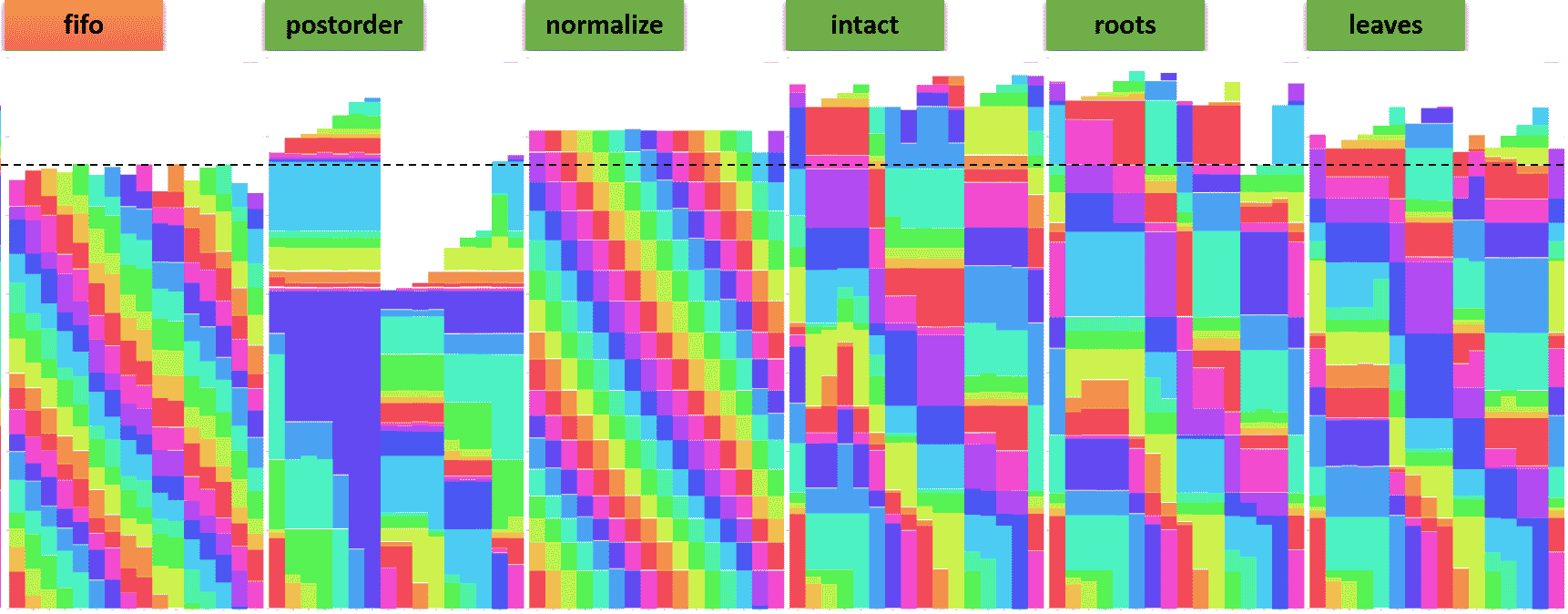
We make the following observations:
- Setting
mr3.dag.priority.schemetofifoyields the shortest running time, i.e., the highest throughput. - Setting
mr3.vertex.priority.schemetopostorderresults in the lowest total resource consumption.
Experiment 2. Every Beeline client submits a unique query repeatedly.
In the second experiment, we run 8 Beeline clients each of which submits a unique query from the TPC-DS benchmark a total of 10 times. (The scale factor for the TPC-DS benchmark is 10TB.) The following table shows the properties of the 8 queries. We may think of Beeline 1 and 2 as executing short-running interactive jobs, and Beeline 7 and 8 as executing long-running ETL jobs.
| Beeline | Query | Number of Vertexes | Execution time in a sequential run (seconds) |
|---|---|---|---|
| Beeline 1 (leftmost, red) | Query 91 | 9 | 5.479 |
| Beeline 2 | Query 3 | 4 | 24.959 |
| Beeline 3 | Query 57 | 10 | 36.549 |
| Beeline 4 | query 30 | 11 | 52.502 |
| Beeline 5 | query 5 | 18 | 77.906 |
| Beeline 6 | query 29 | 13 | 99.199 |
| Beeline 7 | query 50 | 9 | 273.457 |
| Beeline 8 (rightmost, pink) | query 64 | 31 | 424.751 |
The following graphs shows the progress of every Beeline client.
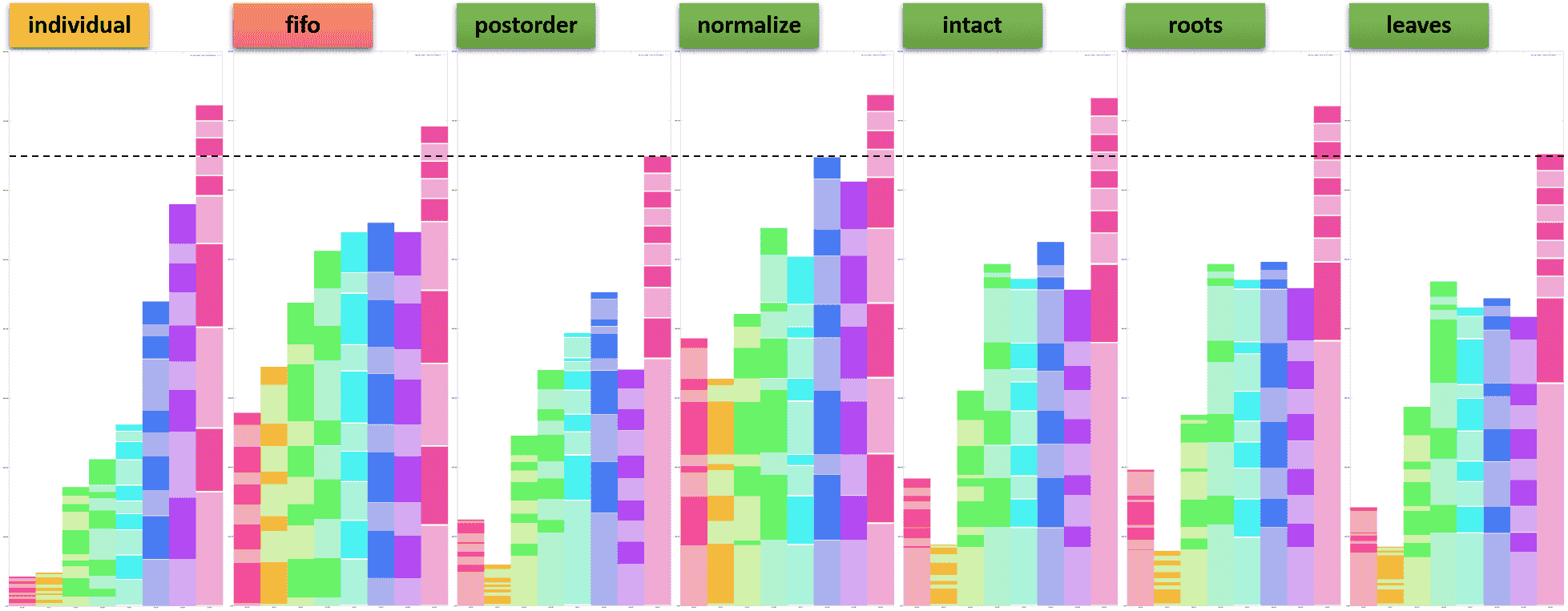
We make the following observations.
- Setting
mr3.dag.queue.schemetoindividualachieves the fairest distribution of resources among Beeline clients because the total execution time for a Beeline client is approximately proportional to the execution time of its query in a sequential run. Note that settingmr3.dag.priority.schemetoconcurrentandmr3.vertex.priority.schemetonormalizeproduces a completely different result. For example, every Beeline client spends about the same amount of time for the first execution of its query. - If
mr3.dag.priority.schemeis set toconcurrent, settingmr3.vertex.priority.schemetopostorderyields both the highest throughput and the shortest turnaround time. Settingmr3.vertex.priority.schemetoleavesis the second best choice.
3. Task scheduling
A Task queue is associated with a unique instance of MR3 TaskScheduler. When a ContainerWorker sends a request with specific resource limits (CPU cores and memory), TaskScheduler searches the Task queue for a Task of the highest priority whose static resource requirements do not exceed the provided limits. In the actual implementation, it considers not only Task priorities but also location hints of Tasks. It may occasionally ignore Task priorities to increase resource utilization, and can even revise Task priorities dynamically to prevent deadlock.
Given the unique challenge of designing an efficient scheduler when Tasks from different DAGs can be mixed within ContainerWorkers, TaskScheduler leverages a dynamic property called producer-completeness to maximize resource utilization. Producer-completeness is a property of a Vertex that indicates whether all its producer Vertexes have completed. That is, a Vertex becomes producer-complete when all its producer Vertexes have finished executing their Tasks. (By definition, a Vertex with no incoming edges is producer-complete from the start.)
Executing producer-incomplete Tasks, i.e., those that are not producer-complete yet, risks wasting compute resources while waiting for their input to become available. Therefore, when producer-complete Tasks are present in the Task queue, TaskScheduler avoids executing producer-incomplete Tasks. This strategy of dynamically overriding priorities also increases the temporal locality of intermediate data shuffled between tasks, further improving efficiency. On the other hand, if all producer-complete Tasks are already under execution, TaskScheduler begins to execute remaining Tasks to avoid idle compute resources. This strategy works because some Tasks can make progress even when their input is only partially available.
TaskScheduler uses the configuration key mr3.taskattempt.queue.scheme
to choose a scheme for scheduling Tasks for execution in ContainerWorkers.
The default scheme is indexed.
basic: TaskScheduler does not use the optimization based on producer-completeness. This scheme should be used only for performance comparison.simple,opt,indexed(default): TaskScheduler applies the optimization based on producer-completeness. (simpleandoptare earlier versions ofindexed.)spark: TaskScheduler uses a Spark-style scheme in which consumer Tasks are scheduled only after all their producer Tasks have completed.
indexed scheme
TaskScheduler using the indexed scheme
also applies an optimization to reduce the likelihood of stragglers delaying their consumer Tasks.
The idea is that, within the same Vertex, Tasks with larger input data
are likely to take longer to complete than those with smaller input data.
Therefore TaskScheduler assigns higher priorities to Tasks with larger input data
so that potential stragglers can start earlier.
In the following example,
two straggler Tasks (in green) significantly delay the progress of consumer Tasks (in blue):

By scheduling such straggler Tasks earlier, we can mitigate their impact on downstream execution.
The configuration key mr3.vertex.high.task.priority.fraction specifies the fraction of
Tasks to be assigned higher priorities within the same Vertex.
The default value is 0.05.
Strict mode
If the configuration key mr3.taskattempt.queue.scheme.strict is set to true,
TaskScheduler runs in strict mode and schedules Tasks
only on ContainerWorkers that match their location hints.
In contrast, TaskScheduler in non-strict mode may choose to ignore location hints
when no matching ContainerWorkers are available.
(Tasks with no location hints are not affected.)
Since only mappers can have location hints,
the strict scheme is particularly useful for Hive on MR3 with LLAP I/O enabled
where reading input data is slow or expensive,
for example, when input data is stored on Amazon S3.
The configuration key mr3.taskattempt.queue.scheme.strict is effective
only with the indexed and spark schemes.