TypeScript
This page shows how to use 1) TypeScript code for generating YAML files and 2) a pre-built Docker images available at DockerHub in order to run Hive on MR3 on Kubernetes with multiple nodes. By following the instructions, the user will learn:
- how to use TypeScript code to run Hive on MR3, along with MR3-UI, Grafana, Superset, and Spark on MR3.
After installing Hive on MR3,
change to the directory typescript.
cd typescript/
Overview
Hive on MR3 consists of four components: Metastore, HiveServer2, MR3 DAGAppMaster, and MR3 ContainerWorkers. The MR3 release can create additional components shown in the following diagram.
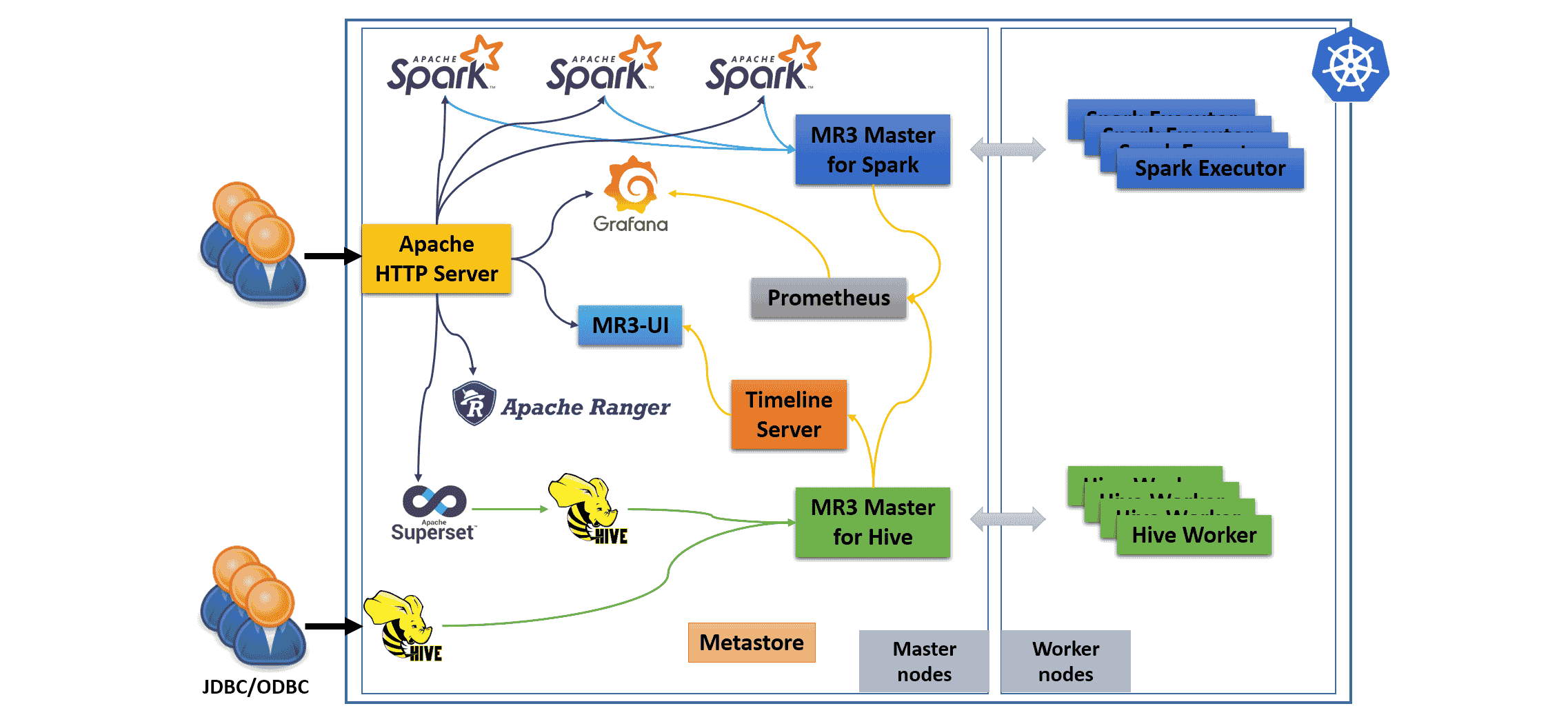
- The user can connect to public HiveServer2 (via JDBC/ODBC) which is exposed to the outside of the Kubernetes cluster. Multiple HiveServer2 instances can be created.
- The user can connect to Apache HTTP Server which serves as a gateway to MR3-UI, Grafana, Superset, Ranger, and Spark UI.
- Internally we run a Timeline Server to collect history logs from DAGAppMaster, and a Prometheus server to collect metrics from DAGAppMaster.
- Superset connects to internal HiveServer2 which is not exposed to the outside of the Kubernetes cluster. Superset with internal HiveServer2 is optional.
- All HiveServer2 instances share a common MR3 DAGAppMaster and its ContainerWorkers.
- Independently of Hive on MR3, multiple Spark drivers sharing a common MR3 DAGAppMaster and its ContainerWorkers can run inside the Kubernetes cluster.
- HiveServer2 and Spark drivers are automatically configured to share Metastore.
Hive on MR3 requires three types of storage:
- Data source such as HDFS or S3
- Either PersistentVolume or HDFS/S3 for storing transient data
- hostPath volumes for storing intermediate data in ContainerWorker Pods
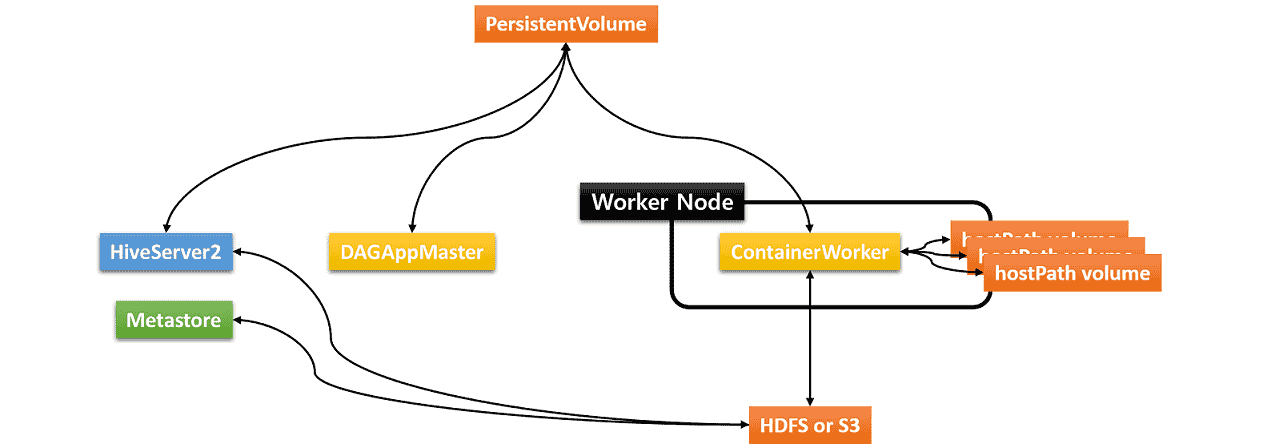
The hostPath volumes are mounted at runtime in each ContainerWorker Pod. These hostPath volumes hold intermediate data to be shuffled between ContainerWorker Pods. In order to be able to mount the same set of hostPath volumes in every ContainerWorker Pod, an identical set of local directories should be ready in all worker nodes (where ContainerWorker Pods are created).
Running Hive on MR3 involves the following steps.
- The user creates a configuration file in TypeScript.
- The user executes TypeScript to generate a single YAML file containing the specification for all the components.
- The user executes
kubectlto start Hive on MR3.
In the second step, TypeScript checks if all configuration parameters in the output YAML file are set consistently across all the components.
Installing node, npm, ts-node
To execute TypeScript code,
Node.js node, Node package manager npm, and TypeScript execution engine ts-node
should be available.
In our example, we use the following versions.
node -v
v12.22.12
npm -v
8.8.0
ts-node --version
v10.7.0
Install dependency modules.
npm install --save uuid
npm install --save js-yaml
npm install --save typescript
npm install --save es6-template-strings
npm install --save @types/node
npm install --save @tsconfig/node12
npm install --save @types/js-yaml
npm install --save @types/uuid
Change to the working directory src/general/run
and create a symbolic link.
cd src/general/run/
ln -s ../../server/ server
Basics
We specify configuration parameters for all the components
in a single TypeScript file run.ts.
vi run.ts
const basicsEnv: basics.T = ...
const metastoreEnv: metastore.T = ...
const hiveEnv: hive.T = ...
const masterEnv: master.T = ...
const workerEnv: worker.T = ...
const rangerEnv: ranger.T = ...
const timelineEnv: timeline.T = ...
const supersetEnv: superset.T = ...
const sparkEnv: spark.T = ...
const sparkmr3Env: sparkmr3.T = ...
const dockerEnv: docker.T = ...
const secretEnv: secret.T = ...
const driverEnv: driver.T = ...
The description of each field is found in the file CONFIG.txt in the root directory typescript.
For example,
the field namespace in basics.T specifies the Kubernetes namespace.
vi ../../../CONFIG.txt
src/server/api/basics.ts
- namespace
Kubernetes namespace
Hive/Spark on MR3 requires a unique namespace.
All Pods created by Hive/Spark on MR3 belong to the same namespace.
After updating run.ts, we execute ts-node to generate 1) a YAML file run.yaml
containing the description of every Kubernetes resource required by Hive on MR3
and 2) another YAML file (e.g., spark1.yaml) for creating a Spark driver Pod.
ts-node run.ts
ls *.yaml
run.yaml spark1.yaml
If a wrong parameter is given or an inconsistency between parameters is detected,
we get an error message instead.
In the following example,
we get an error message "Namespace is mandatory." on the field namespace.
ts-node run.ts
Execution failed: AssertionError [ERR_ASSERTION]: Input invalid: [{"field":"namespace","msg":"Namespace is mandatory."}]
Run failed: AssertionError [ERR_ASSERTION]: Input invalid: [{"field":"namespace","msg":"Namespace is mandatory."}]
Hence the user can learn the meaning of each field
and generate YAML files after updating run.ts.
For most fields, the user may use their default values in run.ts.
Below we explain those fields specific to our example.
basicsEnv: basics.T
namespace should be set to the Kubernetes namespace in which all the components are created.
vi run.ts
const basicsEnv: basics.T = {
namespace: "hivemr3",
warehouseDir should be set to the HDFS directory or S3 bucket storing the warehouse.
(e.g., hdfs://hdfs.server:8020/hive/warehouse or s3a://hivemr3/hive/warehouse).
Note that for using S3, we should use prefix s3a, not s3.
In our example, we store the warehouse on S3-compatible storage.
vi run.ts
const basicsEnv: basics.T = {
warehouseDir: "s3a://hivemr3/warehouse",
The user can use either a PersistentVolume or HDFS/S3 to store transient data.
In our example,
we use an NFS volume to create a PersistentVolume.
The NFS server runs at 192.168.10.1 and uses a directory /home/nfs/hivemr3.
Hive on MR3, MR3-UI, Grafana, Superset, and Ranger all use the same PersistentVolume.
vi run.ts
const basicsEnv: basics.T = {
createPersistentVolume: {
nfs: {
server: "192.168.10.1",
path: "/home/nfs/hivemr3"
}
},
In our example,
we access S3-compatible storage using credentials kept in environment variables.
s3aEndpoint is set to point to the storage server.
vi run.ts
const basicsEnv: basics.T = {
s3aEndpoint: "http://orange0:9000",
s3aCredentialProvider: "EnvironmentVariable",
As a prerequisite,
every worker node where ContainerWorker Pods or Spark driver Pods may run
should have an identical set of local directories for storing intermediate data.
These directories are mapped to hostPath volumes in each ContainerWorker Pod.
Set hostPaths to the list of local directories
(which should be writable to the user with UID 1000).
vi run.ts
const basicsEnv: basics.T = {
hostPaths: "/data1/k8s,/data2/k8s,/data3/k8s",
We create a Service for exposing Apache server to the outside of the Kubernetes cluster.
By setting externalIp to a public IP address
and externalIpHostname to a valid host name,
we create a LoadBalancer for Apache server.
In our example, we expose Apache server at IP address 192.168.10.1.
vi run.ts
const basicsEnv: basics.T = {
externalIp: "192.168.10.1",
externalIpHostname: "orange1",
We create another Service of LoadBalancer type
for exposing HiveServer2 to the outside of the Kubernetes cluster.
hiveserver2Ip should be set to a public IP address for HiveServer2
so that clients can connect to it from the outside of the Kubernetes cluster.
By default, HiveServer2 uses port 9852 for Thrift transport and port 10001 for HTTP transport.
In our example, we expose HiveServer2 at the same IP address as Apache server.
hiveserver2IpHostname should be set to an alias for the host name for HiveServer2.
(The alias is used only internally for Kerberos instance and SSL encryption.)
vi run.ts
const basicsEnv: basics.T = {
hiveserver2Ip: "192.168.10.1",
hiveserver2IpHostname: "orange1",
In our example, we set masterNodeSelector and workerNodeSelector
so as to place master Pods
(for Metastore, HiveServer2, MR3 DAGAppMaster, MR3-UI/Grafana, Apache server, Superset, Ranger, and Spark drivers)
on those nodes with label roles: masters
and worker Pods (for MR3 ContainerWorkers) on those nodes with label roles: workers.
These fields are optional.
vi run.ts
const basicsEnv: basics.T = {
masterNodeSelector: { key: "roles", value: "masters" },
workerNodeSelector: { key: "roles", value: "workers" },
The user may use host names (instead of IP addresses) when configuring Hive on MR3.
In such a case, set hostAliases.
In our example, we set two host aliases.
vi run.ts
const basicsEnv: basics.T = {
hostAliases: [
{ ip: '192.168.10.100', hostnames: "orange0" },
{ ip: '192.168.10.1', hostnames: "orange1" }],
metastoreEnv: metastore.T
We use a MySQL server for Metastore whose address is 192.168.10.1.
vi run.ts
const metastoreEnv: metastore.T = {
dbType: "MYSQL",
databaseHost: "192.168.10.1",
databaseName specifies the name of the database for Hive inside the MySQL server.
vi run.ts
const metastoreEnv: metastore.T = {
databaseName: "hivemr3",
userName and password specify the user name and password of the MySQL server for Metastore.
vi run.ts
const metastoreEnv: metastore.T = {
userName: "root",
password: "passwd",
To initialize database schema, set initSchema to true.
In our example, we do not initialize because we use existing database schema.
vi run.ts
const metastoreEnv: metastore.T = {
initSchema: false,
We allocate 2 CPU cores and 4GB of memory to the Metastore Pod.
vi run.ts
const metastoreEnv: metastore.T = {
resources: {
cpu: 2,
memoryInMb: 4 * 1024
},
hiveEnv: hive.T
We allocate 2 CPU cores and 6GB of memory to a HiveServer2 Pod.
vi run.ts
const hiveEnv: hive.T = {
resources: {
cpu: 2,
memoryInMb: 6 * 1024
},
masterEnv: master.T
We allocate 2 CPU cores and 4GB of memory to the DAGAppMaster Pod for Hive (not for Spark).
vi run.ts
const masterEnv: master.T = {
resources: {
cpu: 2,
memoryInMb: 4 * 1024
},
workerEnv: worker.T
We allocate 4 CPU cores and 16GB of memory to each ContainerWorker Pod for Hive.
We set numTasksInWorker to 4
so that up to four Tasks can run concurrently inside a single ContainerWorker.
vi run.ts
const workerEnv: worker.T = {
workerMemoryInMb: 16 * 1024,
workerCores: 4,
numTasksInWorker: 4,
We set numMaxWorkers to 10
so that up to 10 ContainerWorkers Pods are created for Hive.
vi run.ts
const workerEnv: worker.T = {
numMaxWorkers: 10,
rangerEnv: ranger.T
No change is necessary because we do not use Ranger for authorization.
timelineEnv: timeline.T
We allocate 0.25 CPU cores and 512MB of memory to the Apache server Pod.
vi run.ts
const timelineEnv: timeline.T = {
apacheResources: {
cpu: 0.25,
memoryInMb: 0.5 * 1024
},
For a Pod running MR3-UI/Grafana, we allocate 2 CPU cores and 6GB of memory.
vi run.ts
const timelineEnv: timeline.T = {
resources: {
cpu: 2,
memoryInMb: 6 * 1024
},
supersetEnv: superset.T
We set supersetEnabled to true to run Superset for connecting to Hive on MR3.
Running Superset creates an internal instance of HiveServer2
which is not exposed to the outside of the Kubernetes cluster.
If supersetEnabled is set to false, no additional instance of HiveServer2 is created.
vi run.ts
const supersetEnv: superset.T = {
supersetEnabled: true,
We allocate 2 CPU cores and 8GB of memory to the Superset Pod.
vi run.ts
const supersetEnv: superset.T = {
resources: {
cpu: 2,
memoryInMb: 8 * 1024
},
sparkEnv: spark.T (Optional)
We register four names for Spark drivers: spark1, spark2, spark3, spark4.
When a Spark driver with one of these names is created,
its UI page is accessible via Apache server.
(Creating Spark drivers with different names is allowed,
but their UI pages are not accessible via Apache server.)
vi run.ts
const sparkEnv: spark.T = {
driverNameStr: "spark1,spark2,spark3,spark4"
sparkmr3Env: sparkmr3.T (Optional)
We allocate 2 CPU cores and 4GB of memory to the DAGAppMaster Pod for Spark (not for Hive).
vi run.ts
const sparkmr3Env: sparkmr3.T = {
resources: {
cpu: 2,
memoryInMb: 4 * 1024
},
We allocate 4 CPU cores and 12GB + 4GB = 16GB of memory to each ContainerWorker Pod
for Spark.
We set numTasksInWorker to 4 so that
up to four Tasks can run concurrently inside a single ContainerWorker
(which runs a Spark executor).
vi run.ts
const sparkmr3Env: sparkmr3.T = {
workerMemoryInMb: 12 * 1024,
workerMemoryOverheadInMb: 4 * 1024,
workerCores: 4.0,
numTasksInWorker: 4,
We set numMaxWorkers to 16 so that up to 16 ContainerWorkers Pods are created for Spark.
vi run.ts
const sparkmr3Env: sparkmr3.T = {
numMaxWorkers: 16,
dockerEnv: docker.T
No change is necessary because we use pre-built Docker images.
secretEnv: secret.T
As s3aCredentialProvider is set to EnvironmentVariable in basicsEnv
and we access S3-compatible storage,
S3 access ID and secret should be specified
in environment variables AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY.
vi run.ts
const secretEnv: secret.T = {
secretEnvVars: [
{ name: "AWS_ACCESS_KEY_ID", value: "_your_aws_access_key_id_" },
{ name: "AWS_SECRET_ACCESS_KEY", value:"_your_aws_access_key_id_" }
]
driverEnv: driver.T
We create a YAML file spark1.yaml for creating a Spark driver Pod
with 2 CPU cores and 8GB of memory.
vi run.ts
const driverEnv: driver.T = {
name: "spark1",
resources: {
cpu: 2,
memoryInMb: 8 * 1024
}
Running Hive on MR3
After generating a YAML file run.yaml,
the user can create Kubernetes resources and start Hive on MR3 with kubectl.
ts-node run.ts
kubectl create -f run.yaml
...
statefulset.apps/superset created
configmap/apache-configmap created
statefulset.apps/apache created
If successful, the user can find a total of 7 Pods:
- Apache server
- Public HiveServer2
- Internal HiveServer2 (if Superset is enabled)
- Metastore
- DAGAppMaster for Hive
- Superset (if Superset is enabled)
- MR3-UI/Grafana(which also runs a Timeline Server and Prometheus)
The DAGAppMaster Pod may restart a few times if the MR3-UI/Grafana Pod is not initialized quickly.
kubectl get pods -n hivemr3
NAME READY STATUS RESTARTS AGE
apache-0 1/1 Running 0 83s
hiveserver2-595f4c56c4-z5cq5 1/1 Running 0 83s
hiveserver2-internal-75946d895d-k5bkh 1/1 Running 0 83s
metastore-0 1/1 Running 0 83s
mr3master-2961-0-85fdf5dcb5-v7fr2 1/1 Running 0 64s
superset-0 1/1 Running 0 83s
timeline-0 4/4 Running 0 83s
The user can check if Superset has started successfully.
kubectl logs -n hivemr3 superset-0
...
[2025-03-22 05:51:56 +0000] [87] [INFO] Starting gunicorn 20.1.0
[2025-03-22 05:51:56 +0000] [87] [INFO] Listening at: http://0.0.0.0:8088 (87)
[2025-03-22 05:51:56 +0000] [87] [INFO] Using worker: gthread
[2025-03-22 05:51:56 +0000] [89] [INFO] Booting worker with pid: 89
logging was configured successfully
2025-03-22 05:51:57,993:INFO:superset.utils.logging_configurator:logging was configured successfully
2025-03-22 05:51:58,000:INFO:root:Configured event logger of type <class 'superset.utils.log.DBEventLogger'>
...
The user can find that several directories have been created under the PersistentVolume.
Inside the HiveServer2 Pod,
the PersistentVolume is mounted in the directory /opt/mr3-run/work-dir.
kubectl exec -n hivemr3 -it hiveserver2-internal-75946d895d-k5bkh -- /bin/bash -c 'export PS1="$ "; ls /opt/mr3-run/work-dir/'
apache2.log ats grafana hive httpd.pid prometheus superset
Accessing MR3-UI, Grafana, Superset
The user can access MR3-UI, Grafana, and Superset at the following URLs
where orange1 is the host name assigned to Apache server.
- MR3-UI:
http://orange1:8080/ui/ - Grafana:
http://orange1:8080/grafana/ - Superset:
http://orange1:8080/
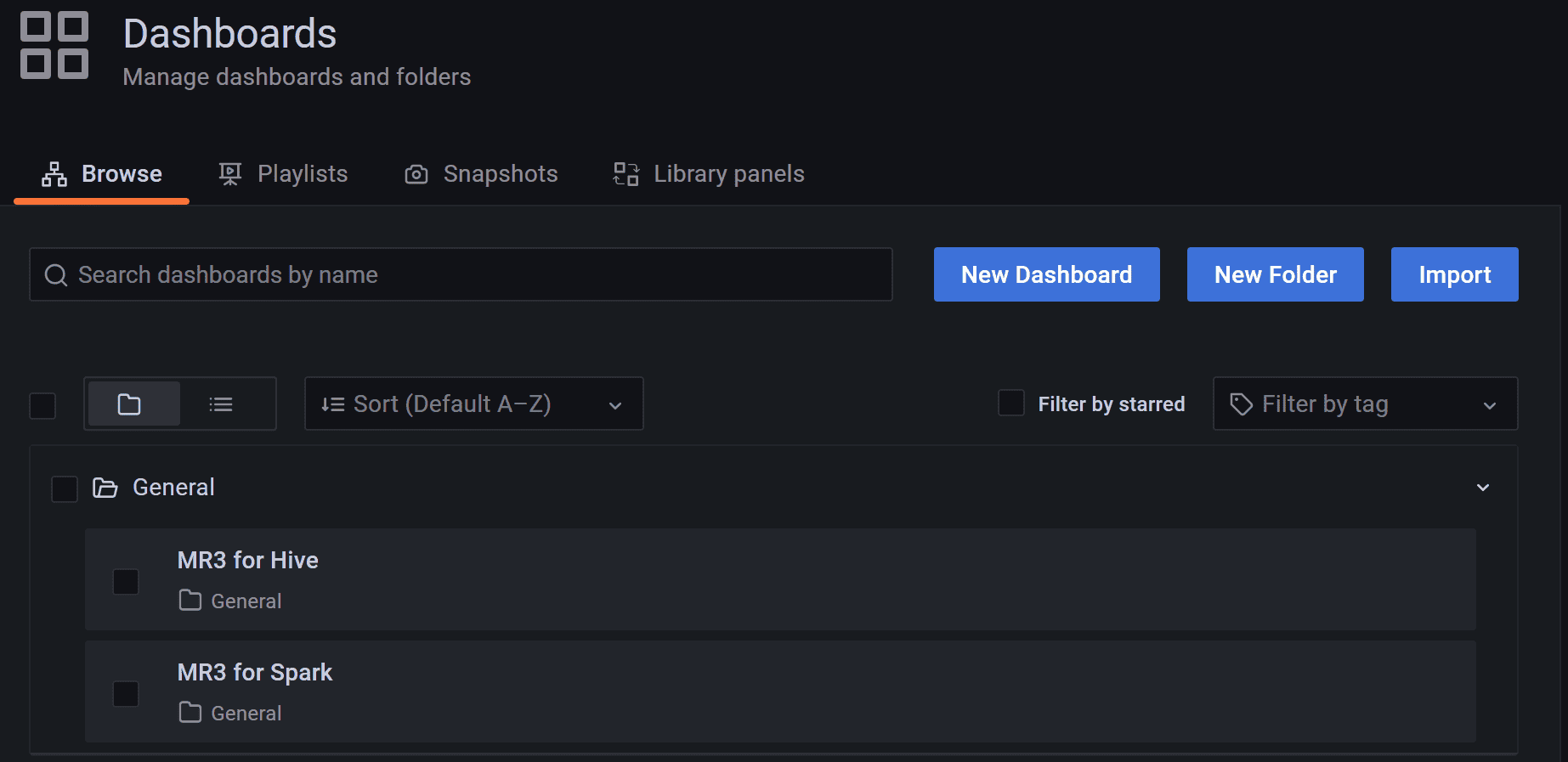
MR3-UI shows details of DAGs executed by MR3 for Hive.

For Grafana,
the password for the user admin is initialized to admin,
and can be changed after the first login.
The user can watch MR3 for Hive on the dashboard MR3 for Hive
(and MR3 for Spark on the dashboard MR3 for Spark after starting Spark on MR3 later).
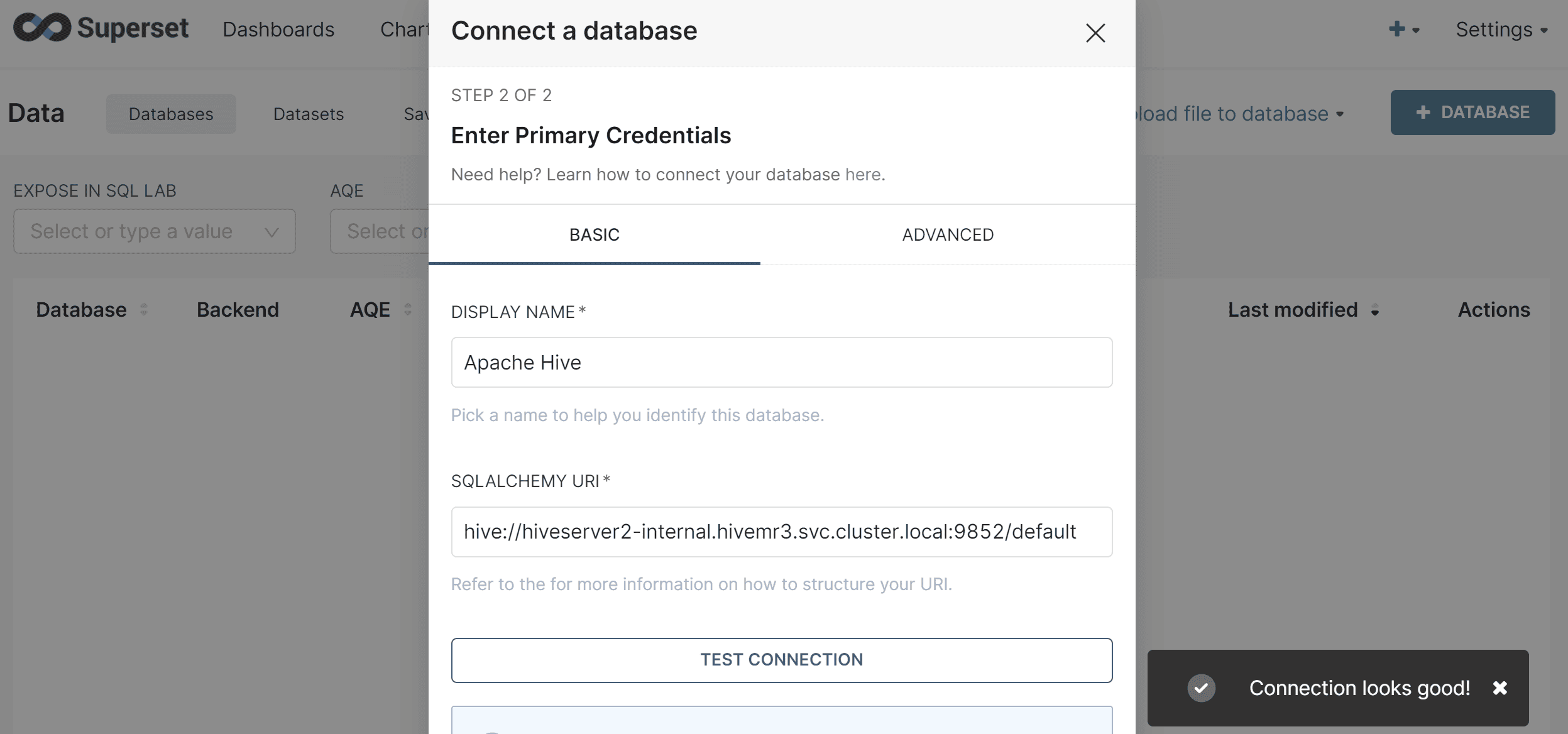
For Superset,
the password for the user admin is initialized to admin,
and can be changed after the first login.
The user should manually register a database source using a Hive URI.
As Kerberos is not used, the Hive URI should be:
hive://hiveserver2-internal.hivemr3.svc.cluster.local:9852/default
Running queries
The user may use any client program (not necessarily Beeline included in the MR3 release) to connect to HiveServer2. For example, the user can run Beeline using JDBC URL:
jdbc:hive2://orange1:9852/;
In this case, queries are sent to public HiveServer2
(hiveserver2-dc45588b-xl856 in our example).
Alternatively the user can submit queries from Superset.
In this case, queries are sent to internal HiveServer2
(hiveserver2-internal-75946d895d-k5bkh in our example).
After running a few queries, ContainerWorker Pods for Hive are created
whose names all start with mr3worker-.
kubectl get pods -n hivemr3
NAME READY STATUS RESTARTS AGE
...
mr3worker-6d6b-1 1/1 Running 0 11s
mr3worker-6d6b-2 1/1 Running 0 11s
mr3worker-6d6b-3 1/1 Running 0 11s
...
Running Spark on MR3
We create a Spark driver Pod with the YAML file spark1.yaml.
kubectl create -f spark1.yaml
service/spark1 created
pod/spark1 created
kubectl get pods -n hivemr3
...
spark1 1/1 Running 0 14s
Inside the Spark driver Pod,
the user can use run-spark-shell.sh to run Spark shell (in the same way as spark-shell)
and run-spark-submit.sh to submit Spark jobs (in the same way as spark-submit).
In our example, we run Spark shell.
kubectl exec -n hivemr3 -it spark1 -- /bin/bash
spark@spark1:/opt/mr3-run/spark$ ./run-spark-shell.sh
Starting Spark shell takes a while because it creates a new DAGAppMaster Pod.
Spark shell may fail to start if the DAGAppMaster Pod does not start quickly.
In such a case, execute run-spark-shell.sh again.
kubectl get pods -n hivemr3
...
mr3master-spark-2962-0-6b66c79d8c-4mjkh 0/1 Running 0 10s
...
spark1 1/1 Running 0 96s
The new Spark driver is configured to use Hive Metastore included in Hive on MR3.
In the following example, we run Spark SQL to access a table pokemon1 created by Hive on MR3.
scala> spark.sql("show databases").show
...
scala> spark.sql("select COUNT(name) from pokemon1 group by power_rate").show
...
We find three new ContainerWorker Pods whose names start with mr3executor-.
Each of these Pods runs a Spark executor.
kubectl get pods -n hivemr3
...
mr3executor-cee5-1 1/1 Running 0 23s
mr3executor-cee5-2 1/1 Running 0 18s
...
mr3master-spark-2962-0-6b66c79d8c-4mjkh 1/1 Running 0 3m44s
...
spark1 1/1 Running 0 5m10s
Running two Spark applications
To demonstrate two Spark applications sharing ContainerWorker Pods,
we create another Spark driver Pod called spark2.
Create a copy of spark1.yaml and replace spark1 with spark2.
cp spark1.yaml spark2.yaml
sed -i 's/spark1/spark2/g' spark2.yaml
Then we create a new Spark driver Pod with spark2.yaml.
kubectl create -f spark2.yaml
service/spark2 created
pod/spark2 created
kubectl get pods -n hivemr3
...
spark1 1/1 Running 0 7m12s
spark2 1/1 Running 0 9s
Inside the new Pod, the user can run Spark shell or submit Spark jobs.
The new Spark driver may not create additional ContainerWorker Pods
because both the Spark drivers share ContainerWorker Pods.
By default, we use fair scheduling
(with containerSchedulerScheme set to fair in sparkmr3Env,
or equivalently mr3.container.scheduler.scheme set to fair in mr3-site.xml).
Hence MR3 tries to divide
ContainerWorker Pods equally between the two Spark drivers.
While Spark drivers are running inside the Spark driver Pods, the user can access their UI pages at the following URLs:
- Spark driver
spark1:http://orange1:8080/spark1/ - Spark driver
spark2:http://orange1:8080/spark2/
Limitations in accessing Hive Metastore from Spark SQL
While Spark on MR3 is automatically configured to use Hive Metastore included in Hive on MR3, there are a few limitations when using Spark SQL.
- Spark SQL cannot access transactional tables.
- An update to a table by Hive may not be immediately visible to Spark SQL. To make such an update visible, the user should manually refresh the table.
- Spark SQL is not affected by the authorization mechanism of Hive
(specified by
authorizationinhiveEnv, or equivalentlyhive.security.authorization.managerinhive-site.xml) because it does not send queries to HiveServer2. In other words, Spark SQL can access any (non-transactional) tables.
For safe operations, Hive should not update tables that are to be accessed simultaneously by Spark SQL. Instead try to create and update (non-transactional) tables in Spark SQL and only read such tables from Hive (e.g., to populate transactional tables).
By default, Spark on MR3 is configured to create ORC tables.
vi server/spark-resources/spark-defaults.conf
spark.sql.legacy.createHiveTableByDefault=false
spark.sql.sources.default=orc
To create Parquet tables, set spark.sql.sources.default to parquet.
scala> spark.conf.set("spark.sql.sources.default", "parquet")
Stopping Hive/Spark on MR3
In order to terminate Hive/Spark on MR3 and delete all Kubernetes resources, execute kubectl.
kubectl delete -f spark1.yaml
service "spark1" deleted
pod "spark1" deleted
kubectl delete -f spark2.yaml
service "spark2" deleted
pod "spark2" deleted
We see that even though there is no Spark application running, the DAGAppMaster Pod and the ContainerWorker Pods for Spark are still alive. This is a feature, not a bug, because DAGAppMaster and ContainerWorkers are not owned by a particular Spark application. For example, any new Spark driver automatically uses these existing Pods for Spark.
kubectl get pods -n hivemr3
...
mr3master-spark-2962-0-6b66c79d8c-4mjkh 1/1 Running 0 10m
...
Execute kubectl with run.yaml to delete all the remaining Kubernetes resources.
kubectl delete -f run.yaml