Shuffle Configuration
The performance of Hive on MR3 is heavily influenced by its shuffle configuration. The key components involved in shuffling are: 1) ShuffleServer and 2) shuffle handlers.
ShuffleServer manages fetchers that send fetch requests to remote ContainerWorkers, whereas shuffle handlers provides a shuffle service by managing fetch requests from remote ContainerWorkers.
Configuring ShuffleServer
Hive on MR3 centralizes the management of all fetchers under a common ShuffleServer (see Managing Fetchers).
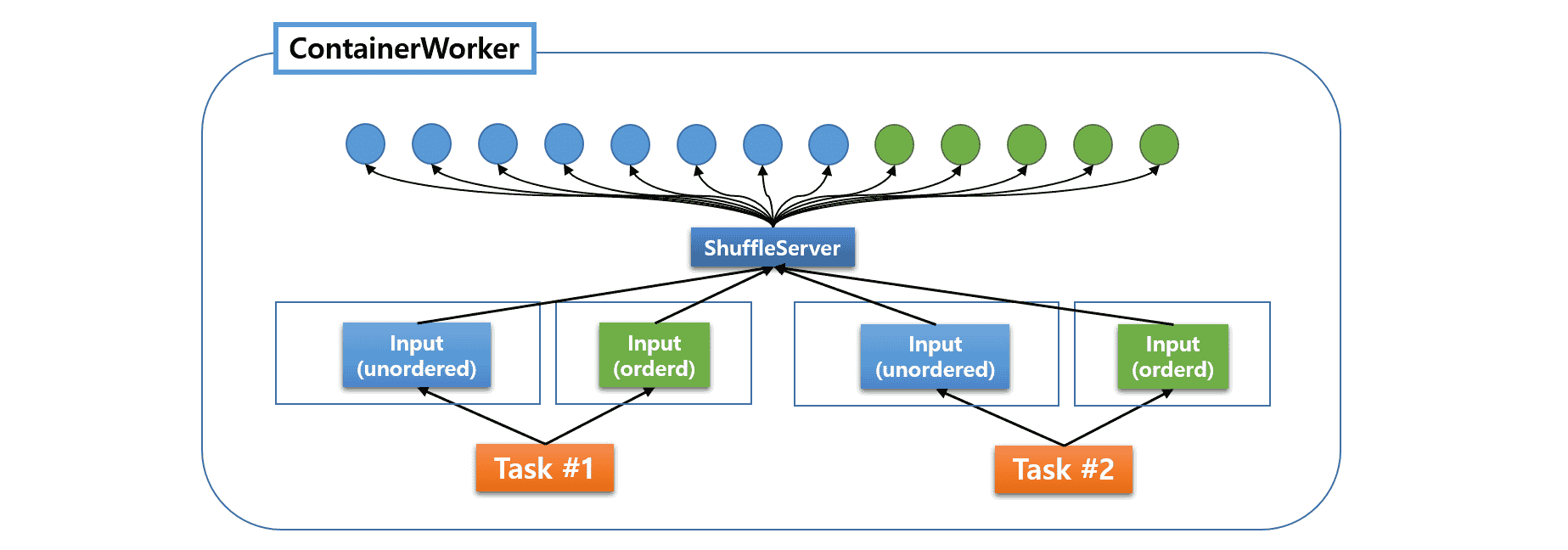
After choosing the resources for ContainerWorkers and the concurrency level,
the user should adjust two configuration keys in tez-site.xml.
tez.runtime.shuffle.parallel.copiesspecifies the maximum number of concurrent fetchers that a single LogicalInput can request.tez.runtime.shuffle.total.parallel.copiesspecifies the maximum number of concurrent fetchers that can run inside a ContainerWorker.
We recommend starting with the following settings:
tez.runtime.shuffle.parallel.copiesto 10tez.runtime.shuffle.total.parallel.copiesto 10 * the total number of cores assigned to each ContainerWorker
Using MR3 shuffle handlers
By default, Hive on MR3 uses MR3 shuffle handlers instead of an external shuffle service.
The following configuration keys in mr3-site.xml and tez-site.xml
enable the runtime system of MR3 to route intermediate data to MR3 shuffle handlers.
mr3.use.daemon.shufflehandlerinmr3-site.xmlspecifies the number of shuffle handlers in each ContainerWorker. If its value is greater than zero, a ContainerWorker creates its own threads for shuffle handlers. If it is set to zero, no shuffle handlers are created and MR3 uses an external shuffle service.tez.am.shuffle.auxiliary-service.idintez-site.xmlshould be set totez_shufflein order to use MR3 shuffle handlers. On Hadoop, it can be set tomapreduce_shuffleto use the Hadoop shuffle service, in which casemr3.use.daemon.shufflehandleris ignored.
Running too many shuffle handlers or creating too many threads per shuffle handler
can negatively impact performance on ContainerWorkers with limited resources.
Hence
the user may have to adjust the value for the configuration key tez.shuffle.max.threads in tez-site.xml in order to limit the total number of threads for shuffle handlers.
For example, on a node with 40 cores,
setting tez.shuffle.max.threads to the default value of 0
creates 2 * 40 = 80 threads for each shuffle handler.
If mr3.use.daemon.shufflehandler is set to 20, a ContainerWorker creates a total of 80 * 20 = 1600 threads for shuffle handlers, which may be excessive.
For running Hive on MR3, the user can set hive.mr3.use.daemon.shufflehandler
in hive-site.xml which is mapped to mr3.use.daemon.shufflehandler.
We recommend starting with the following settings:
tez.shuffle.max.threadsto 20hive.mr3.use.daemon.shufflehandlerto the total number of cores assigned to each ContainerWorker / 2
Pipelined shuffling
Shuffling in MR3 proceeds in either pipelined mode or non-pipelined mode.
- With pipelined shuffling, whenever an output buffer of a TaskAttempt is filled,
a message (of type
DataMovementEvent) is sent to downstream TaskAttempts. Hence a downstream TaskAttempt can fetch the output data of an upstream TaskAttempt through several interleaved shuffle requests. - With non-pipelined shuffling, a message is sent to downstream TaskAttempts only after the entire output data becomes available and gets merged in a single output file. Hence a downstream TaskAttempt makes a single shuffle request to fetch the output data of an upstream TaskAttempt.
The user can enable pipelined shuffling
by setting the configuration key tez.runtime.pipelined-shuffle.enabled to true in tez-site.xml.
To use pipelined shuffling, it is recommended to disable speculative execution
(by setting hive.mr3.am.task.concurrent.run.threshold.percent to 100.0 in hive-site.xml)
to avoid launching multiple concurrent TaskAttempts for the same Task.
This is because with pipelined shuffling,
partial results from separate TaskAttempts may not be mixed in downstream TaskAttempts.
Specifically
a downstream TaskAttempt kills itself whenever it receives partial results
from different upstream TaskAttempts.
Experimental results based on the 10TB TPC-DS benchmark show that
pipelined shuffling usually improves the performance of Hive on MR3.
Fault tolerance also works correctly with pipelined shuffling.
The configuration key tez.runtime.pipelined-shuffle.enabled is set to true in the MR3 release.
We recommend pipelined shuffling as the default mode. For executing long-running batch queries that may occasionally trigger fault tolerance, however, we recommend non-pipelined shuffling for its higher stability.
Compressing intermediate data
Compressing intermediate data usually results in better shuffle performance.
The user can compress intermediate data by setting the following two configuration keys in tez-site.xml.
tez.runtime.compressshould be set to true.tez.runtime.compress.codecshould be set to the codec for compressing intermediate data.
By default, tez.runtime.compress.codec is set to org.apache.hadoop.io.compress.SnappyCodec in tez-site.xml.
On Hadoop, the Snappy library should be manually installed on every node.
On Kubernetes and in standalone mode,
the Snappy library is already included in the MR3 release.
The user can also use Zstandard compression
after installing the Zstandard library and setting tez.runtime.compress.codec to
org.apache.hadoop.io.compress.ZStandardCodec.
Note, however, that a query may fail if it generates large intermediate files (e.g., over 25MB).
Local disks
ContainerWorkers write intermediate data on local disks, so using fast storage for local disks (such as NVMe SSDs) always improves shuffle performance. Using multiple local disks is also preferable to using just a single local disk because Hive on MR3 rotates local disks when creating files for storing intermediate data.
Backpressure
The configuration key tez.shuffle.max.block.requests.thread.multiple in tez-site.xml
specifies a multiplier used in calculating
the threshold for the total number of active shuffle requests that triggers backpressure:
tez.shuffle.max.block.requests.thread.multiple* the total number of shuffle handlers =tez.shuffle.max.block.requests.thread.multiple*mr3.use.daemon.shufflehandler*tez.shuffle.max.threads
The default value of tez.shuffle.max.block.requests.thread.multiple is 2.
Set it to a larger value (e.g., 3) in order to allow more active shuffle requests.
Speculative fetching
In typical environments, the default settings for speculative fetching in the MR3 release generally work well to prevent fetch delays:
tez.runtime.shuffle.speculative.fetch.wait.millis= 12500tez.runtime.shuffle.stuck.fetcher.threshold.millis= 2500tez.runtime.shuffle.stuck.fetcher.release.millis= 7500tez.runtime.shuffle.max.speculative.fetch.attempts= 2
The default settings are particularly suitable for interactive queries because a speculative fetcher is created relatively quickly: about 5 seconds (7500 - 2500 = 5000 milliseconds) after the initial detection of a stalled fetcher. For executing long-running batch queries or shuffle-heavy queries, fetch delays are more likely to occur, so less aggressive settings may be more appropriate. For example, the user can use the following settings:
tez.runtime.shuffle.speculative.fetch.wait.millis= 30000tez.runtime.shuffle.stuck.fetcher.threshold.millis= 2500tez.runtime.shuffle.stuck.fetcher.release.millis= 17500tez.runtime.shuffle.max.speculative.fetch.attempts= 2
Memory-to-memory merging vs disk-based merging for ordered records
By default, Hive on MR3 performs memory-to-memory merging to merge ordered records shuffled from upstream vertices.
vi tez-site.xml
<property>
<name>tez.runtime.shuffle.memory-to-memory.enable</name>
<value>true</value>
</property>
If the number of ordered records to be merged in each reducer is huge,
disk-based merging can be more effective.
To switch to disk-based merging, set tez.runtime.shuffle.memory-to-memory.enable to false.
Configuring kernel parameters
A common solution to reduce the chance of fetch delays is to adjust a few kernel parameters to prevent packet drops. For example, the user can adjust the following kernel parameters on every node in the cluster:
- increase the value of
net.core.somaxconn(e.g., from the default value of 128 to 16384) - optionally increase the value of
net.ipv4.tcp_max_syn_backlog(e.g., to 65536) - optionally decrease the value of
net.ipv4.tcp_fin_timeout(e.g., to 30)
Unfortunately configuring kernel parameters is only a partial solution which does not eliminate fetch delays completely. This is because if the application program is slow in processing connection requests, TCP listen queues eventually become full and fetch delays ensue. In other words, without optimizing the application program itself, we can never eliminate fetch delays by adjusting kernel parameters alone.
Configuring network interfaces
The node configuration for network interfaces also affects the chance of fetch delays. For example, frequent fetch delays due to packet loss may occur if the scatter-gather feature is enabled on network interfaces on worker nodes.
ethtool -k p1p1
...
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
In such a case, the user can disable relevant features on network interfaces.
ethtool -K p1p1 sg off
Preventing fetch delays
In MR3, fetch delays are usually prevented by enabling speculative fetching. If fetch delays persist despite speculative fetching, the user can try two features of MR3: running multiple shuffle handlers in a ContainerWorker and speculative execution.
To check for fetch delays,
disable the query results cache by setting
the configuration key hive.query.results.cache.enabled to false,
and run a shuffle-heavy query many times.
If the execution time is unstable and fluctuates significantly, fetch delays are likely the cause.
To enable speculative execution,
set the configuration key hive.mr3.am.task.concurrent.run.threshold.percent in hive-site.xml to the percentage of completed Tasks
before starting to watch TaskAttempts for speculative execution.
The user should also set the configuration key hive.mr3.am.task.max.failed.attempts to the maximum number of TaskAttempts for the same Task.
In the following example,
a ContainerWorker waits until 99 percent of Tasks complete before starting to watch TaskAttempts,
and create up to 3 TaskAttempts for the same Task.
vi conf/hive-site.xml
<property>
<name>hive.mr3.am.task.concurrent.run.threshold.percent</name>
<value>99.0</value>
</property>
<property>
<name>hive.mr3.am.task.max.failed.attempts</name>
<value>3</value>
</property>
Configuring connection timeout
The configuration key tez.runtime.shuffle.connect.timeout in tez-site.xml specifies
the maximum time (in milliseconds) for trying to connect to an external shuffle service
or built-in shuffle handlers before reporting fetch-failures.
Specifically
the logic of TaskAttempts reporting fetch-failures to the DAGAppMaster is as follows.
If a TaskAttempt fails to connect to an external shuffle service or built-in shuffle handlers serving source TaskAttempts, it retries in 5 seconds
(as specified by UNIT_CONNECT_TIMEOUT in the class org.apache.tez.http.BaseHttpConnection)
while waiting up to the duration specified by tez.runtime.shuffle.connect.timeout.
Here are a few examples:
- If
tez.runtime.shuffle.connect.timeoutis set to 2500, it never retries and reports fetch-failures immediately. - If
tez.runtime.shuffle.connect.timeoutis set to 7500, it retries only once after waiting for 5 seconds. - If
tez.runtime.shuffle.connect.timeoutis set to 12500, it retries up to twice, each after waiting for 5 seconds. - If
tez.runtime.shuffle.connect.timeoutis set to the default value of 27500, it retries up to five times, each after waiting for 5 seconds.
If an error occurs after successfully connecting to the shuffle service or the built-in shuffle handler, the TaskAttempt reports a fetch-failure immediately. Here are a few cases of such errors:
- The node running the Hadoop shuffle service for source TaskAttempts suddenly crashes.
- The ContainerWorker process holding the output of source TaskAttempts suddenly terminates.
- The output of source TaskAttempts gets corrupted or deleted.
If the connection fails too often
because of the contention for disk access or network congestion,
using a large value for tez.runtime.shuffle.connect.timeout may be a good decision
because it leads to more retries, thus decreasing the chance of fetch-failures.
(If the connection fails because of hardware problems,
fetch-failures are eventually reported regardless of the value of tez.runtime.shuffle.connect.timeout.)
On the other hand, using too large a value may delay reports of fetch-failures much longer than Task/Vertex reruns take, thus significantly increasing the execution time of the query. Hence the user should choose an appropriate value that triggers Task/Vertex reruns reasonably fast.