1. Metastore fails to find a MySQL connector jar file in the classpath with ClassNotFoundException (on Kubernetes).
2020-07-18T04:03:14,856 ERROR [main] tools.HiveSchemaHelper: Unable to find driver class
java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
The classpath of Metastore includes the directories /opt/mr3-run/lib and /opt/mr3-run/host-lib
inside the Metastore Pod,
and the user can place a MySQL connector jar file in one of these two directories in three different ways.
-
When building a Docker image, set
HIVE_MYSQL_DRIVERinenv.sh(notKubernetes/env.sh) to the path of the jar file. Then the jar file is found in the directory/opt/mr3-run/libinside the Metastore Pod.bash-4.2$ ls /opt/mr3-run/lib mysql-connector-java-5.1.49.jarIn this case, the user should comment out the following lines in
kubernetes/yaml/metastore.yamlso that the directory/opt/mr3-run/libis not overriden by a subdirectory in the PersistentVolume.# - name: work-dir-volume # mountPath: /opt/mr3-run/lib # subPath: libWith Helm, the user should set
metastore.mountLibto false inkubernetes/helm/hive/values.yaml.metastore: mountLib: false -
If the Docker image is not built with the jar file, the user can copy it to the subdirectory
libin the PersistentVolume and use PersistentVolumeClaimwork-dir-volumeinkubernetes/yaml/metastore.yaml. Then the jar file is mounted in the directory/opt/mr3-run/libinside the Metastore Pod. See Copying a MySQL connector jar file to EFS in Creating a PersistentVolume using EFS for examples.- name: work-dir-volume mountPath: /opt/mr3-run/lib subPath: libWith Helm, the user should set
metastore.mountLibto true inkubernetes/helm/hive/values.yaml.metastore: mountLib: true -
If the Docker image is not built with the jar file and a PersistentVolume is not available (e.g., when using S3 instead of EFS on Amazon EKS), the user can mount it in the directory
/opt/mr3-run/host-libusing a hostPath volume. See Downloading a MySQL connector in Creating an EKS cluster for an example.With Helm,
kubernetes/helm/hive/values.yamlshould setmetastore.hostLibto true and setmetastore.hostLibDirto a common local directory containing the jar file on all worker nodes.hostLib: true hostLibDir: "/home/ec2-user/lib"
2. When running a query, ContainerWorker Pods never get launched and Beeline gets stuck.
Try adjusting the resource for DAGAppMaster and ContainerWorker Pods.
In kubernetes/conf/mr3-site.xml, the user can adjust the resource for the DAGAppMaster Pod.
<property>
<name>mr3.am.resource.memory.mb</name>
<value>16384</value>
</property>
<property>
<name>mr3.am.resource.cpu.cores</name>
<value>2</value>
</property>
In kubernetes/conf/hive-site.xml, the user can adjust the resource for ContainerWorker Pods (assuming that the configuration key hive.mr3.containergroup.scheme is set to all-in-one).
<property>
<name>hive.mr3.map.task.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>hive.mr3.map.task.vcores</name>
<value>1</value>
</property>
<property>
<name>hive.mr3.reduce.task.memory.mb</name>
<value>8192</value>
</property>
<property>
<name>hive.mr3.reduce.task.vcores</name>
<value>1</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.memory.mb</name>
<value>16384</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.vcores</name>
<value>2</value>
</property>
3. A query fails with a message No space available in any of the local directories (on Kubernetes).
A query may fail with the following error from Beeline:
ERROR : Terminating unsuccessfully: Vertex failed, vertex_2134_0000_1_01, Some(Task unsuccessful: Map 1, task_2134_0000_1_01_000000, java.lang.RuntimeException: org.apache.hadoop.util.DiskChecker$DiskErrorException: No space available in any of the local directories.
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:370)
...
Caused by: org.apache.hadoop.util.DiskChecker$DiskErrorException: No space available in any of the local directories.
In such a case, check if the configuration key mr3.k8s.pod.worker.hostpaths in kubernetes/conf/mr3-site.xml is properly set, e.g.:
<property>
<name>mr3.k8s.pod.worker.hostpaths</name>
<value>/data1/k8s,/data2/k8s,/data3/k8s,/data4/k8s,/data5/k8s,/data6/k8s</value>
</property>
In addition, check if the directories listed in mr3.k8s.pod.worker.hostpaths are writable to the user running Pods.
4. A query accessing S3 fails with SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
A query accessing S3 may fail with an error message SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool.
This can happen in DAGAppMaster when running InputInitializer,
in which case the Beeline and the DAGAppMaster Pod generate such errors as:
### from Beeline
ERROR : FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Terminating unsuccessfully: Vertex failed, vertex_22169_0000_1_02, Some(RootInput web_sales failed on Vertex Map 1: com.datamonad.mr3.api.common.AMInputInitializerException: web_sales)Map 1 1 task 2922266 milliseconds: Failed
### from the DAGAppMaster Pod
Caused by: java.lang.RuntimeException: ORC split generation failed with exception: java.io.InterruptedIOException: Failed to open s3a://hivemr3-partitioned-2-orc/web_sales/ws_sold_date_sk=2451932/000001_0 at 14083 on s3a://hivemr3-partitioned-2-orc/web_sales/ws_sold_date_sk=2451932/000001_0: com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
This can also happen in ContainerWorkers, in which case ContainerWorker Pods generate such errors as:
...... com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
at org.apache.hadoop.hive.ql.exec.FileSinkOperator$FSPaths.closeWriters(FileSinkOperator.java:202) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.closeOp(FileSinkOperator.java:1276) ~[hive-exec-3.1.2.jar:3.1.2]
...
...... com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
at org.apache.hadoop.fs.s3a.S3AUtils.translateInterruptedException(S3AUtils.java:340) ~[hadoop-aws-3.1.2.jar:?]
...
Caused by: com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
Depending on the settings for S3 buckets and the properties of datasets,
the user may have to change the values for the following configuration keys in kubernetes/conf/core-site.xml.
- increase the value for
fs.s3a.connection.maximum(e.g., to 2000 or higher) - increase the value for
fs.s3a.threads.max - increase the value for
fs.s3a.threads.core - set
fs.s3a.blocking.executor.enabledto false - set
fs.s3a.connection.ssl.enabledto false
For more details, see Basic Performance Tuning.
5. A query accessing S3 makes no progress because Map vertexes get stuck in the state of Initializing.
If DAGAppMaster fails to resolve host names, the execution of a query may get stuck in the following state:
 In such a case, check if the configuration key
In such a case, check if the configuration key mr3.k8s.host.aliases is set properly in kubernetes/conf/mr3-site.xml.
For example, if the user sets the environment variable HIVE_DATABASE_HOST in env.sh to the host name (instead of the address) of the MySQL server,
its address should be specified in mr3.k8s.host.aliases.
HIVE_DATABASE_HOST=orange0
<property>
<name>mr3.k8s.host.aliases</name>
<value>orange0=11.11.11.11</value>
</property>
Internally the class AmazonS3Client (running inside InputInitializer of MR3) throws an exception java.net.UnknownHostException,
which, however, is swallowed and never propagated to DAGAppMaster.
As a consequence, no error is reported to Beeline and the query gets stuck.
6. DAGAppMaster Pod does not start because mr3-conf.properties does not exist.
MR3 generates a property file mr3-conf.properties from ConfigMap mr3conf-configmap-master
and mounts it inside DAGAppMaster Pod.
If DAGAppMaster Pod fails with the following message,
it means that either ConfigMap mr3conf-configmap-master is corrupt or mr3-conf.properties has not been generated.
2020-05-15T10:35:10,255 ERROR [main] DAGAppMaster: Error in starting DAGAppMasterjava.lang.IllegalArgumentException: requirement failed: Properties file mr3-conf.properties does not exist
In such a case, try again after manually deleting ConfigMap mr3conf-configmap-master
so that Hive on MR3 on Kubernetes can start without a ConfigMap of the same name.
7. Metastore fails with Version information not found in metastore
The following error occurs if the MySQL database for Metastore has not been initialized.
MetaException(message:Version information not found in metastore. )
...
Caused by: MetaException(message:Version information not found in metastore. )
at org.apache.hadoop.hive.metastore.ObjectStore.checkSchema(ObjectStore.java:7564)
...
The user can initialize schema when starting Metastore by updating kubernetes/yaml/metastore.yaml as follows:
args: ["start", "--init-schema"]
For more details, see Running Metastore.
8. HiveServer2 repeatedly prints an error message server.TThreadPoolServer: Error occurred during processing of message.
HiveServer2 may repeatedly print the same error message at a regular interval such as:
2020-08-13T05:28:47,351 ERROR [HiveServer2-Handler-Pool: Thread-27] server.TThreadPoolServer: Error occurred during processing of message.
java.lang.RuntimeException: org.apache.thrift.transport.TSaslTransportException: No data or no sasl data in the stream
at org.apache.thrift.transport.TSaslServerTransport$Factory.getTransport(TSaslServerTransport.java:219) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:269) ~[hive-exec-3.1.2.jar:3.1.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_252]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_252]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_252]
Caused by: org.apache.thrift.transport.TSaslTransportException: No data or no sasl data in the stream
...
2020-08-13T04:51:23,697 ERROR [HiveServer2-Handler-Pool: Thread-27] server.TThreadPoolServer: Error occurred during processing of message.
java.lang.RuntimeException: org.apache.thrift.transport.TTransportException: javax.net.ssl.SSLHandshakeException: Remote host closed connection during handshake
at org.apache.thrift.transport.TSaslServerTransport$Factory.getTransport(TSaslServerTransport.java:219) ~[hive-exec-3.1.2.jar:3.1.2]
at org.apache.thrift.server.TThreadPoolServer$WorkerProcess.run(TThreadPoolServer.java:269) ~[hive-exec-3.1.2.jar:3.1.2]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_232]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_232]
at java.lang.Thread.run(Thread.java:748) [?:1.8.0_232]
Caused by: org.apache.thrift.transport.TTransportException: javax.net.ssl.SSLHandshakeException: Remote host closed connection during handshake
...
Caused by: javax.net.ssl.SSLHandshakeException: Remote host closed connection during handshake
...
Caused by: java.io.EOFException: SSL peer shut down incorrectly
...
This error message is printed when readiness and liveness probes contact HiveServer2, or when the LoadBalancer sends ping signals to HiveServer2 to check its health. Hence it does not indicate an error and can be ignored. For the user who wants to suppress such error messages, the following workaround is available.
-
Download
TThreadPoolServer.javafrom the Thrift source repository (https://github.com/apache/thrift/) and copy it to a new directoryql/src/java/org/apache/thrift/server/in the source code of Hive for MR3.$ wget https://raw.githubusercontent.com/apache/thrift/0.9.3.1/lib/java/src/org/apache/thrift/server/TThreadPoolServer.java $ mkdir -p ql/src/java/org/apache/thrift/server/ $ cp TThreadPoolServer.java ql/src/java/org/apache/thrift/server/ -
Locate the line that prints the error message.
} catch (Exception x) { LOGGER.error("Error occurred during processing of message.", x); } finally {Then modify the line to suppress the error message or the stack trace. For example, the user can suppress the stack trace as follows:
} catch (Exception x) { LOGGER.error("Error occurred during processing of message: " + x.getClass().getName()); } finally { -
Rebuild Hive for MR3 and create a new Docker image.
9. A query accessing HDFS fails with org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block.
A query accessing HDFS may fail with an error like:
java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: java.io.IOException: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1848301428-10.1.90.9-1589952347981:blk_1078550925_4810302 file=/tmp/tpcds-generate/9999/catalog_returns/data-m-08342
...
Caused by: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1848301428-10.1.90.9-1589952347981:blk_1078550925_4810302 file=/tmp/tpcds-generate/9999/catalog_returns/data-m-08342
at org.apache.hadoop.hdfs.DFSInputStream.refetchLocations(DFSInputStream.java:875)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:858)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:837)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:566)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:756)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:825)
at java.io.DataInputStream.read(DataInputStream.java:149)
...
This error can occur even when the HDFS block is actually available. It is usually the result of using too small values for a few configuration keys. For example, the user can try adjusting the following configuration keys.
hive.exec.max.dynamic.partitions.pernode(e.g., from the default value of 1000 to 100000)hive.exec.max.dynamic.partitions(e.g., from the default value of 100 to 100000)hive.exec.max.created.files(e.g., from the default value of 100000 to 1000000)
10. A query fails with too many fetch failures.
A query may fail with an error like after fetch failures:
Caused by: java.io.IOException: Map_1: Shuffle failed with too many fetch failures and insufficient progress! failureCounts=1, pendingInputs=1, fetcherHealthy=false, reducerProgressedEnough=true, reducerStalled=true
In the following example of loading 10TB TPC-DS datasets,
Map 1 initially succeeds, but later reruns its Tasks because Reducer 2 experiences many fetch failures.
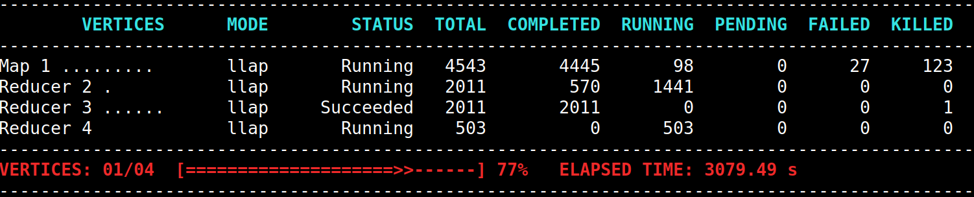
In such a case, the user can try to reduce the chance of fetch failures or recover from fetch failures as follows:
- Decrease the value for the configuration key
tez.runtime.shuffle.total.parallel.copiesintez-site.xml(e.g., from 360 to 180) to reduce the total number of concurrent fetchers in each ContainerWorker. - Decrease the value for the configuration key
tez.runtime.shuffle.parallel.copiesintez-site.xml(e.g., from 20 to 10) to reduce the number of fetchers per LogicalInput (all of which run in parallel). This has the effect of reducing the load on the side of shuffle handlers because fewer requests are simultaneously made from reducers. - Increase the value for the configuration key
hive.mr3.am.task.max.failed.attempts(e.g., to 5). This has the effect of allowing each reducer to make more attempts to fetch input data. See Fault Tolerance for more details. - Increase the value for the configuration key
tez.runtime.shuffle.connect.timeoutintez-site.xml(e.g., to 17500). See Basic Performance Tuning for more details.
11. Metastore and Ranger do not start normally when using MySQL databases (on Kubernetes).
From MR3 release 1.4,
the Docker images for Metastore and Ranger from DockerHub
download a MySQL Connector from
https://cdn.mysql.com/Downloads/Connector-J/mysql-connector-java-8.0.28.tar.gz.
To use MySQL databases, the user should check the compatibility with MySQL Connector 8.0.28.
For example, Ranger may generate an error if it uses an incompatible MySQL database.
2022-05-10 10:38:12,937 [E] Ranger all admins default password change request failed
Starting Apache Ranger Admin Service
Apache Ranger Admin Service with pid 2061 has started.
12. When executing a query calling UDFs or using JdbcStorageHandler, it fails with ClassNotFoundException.
By default, the configuration key mr3.am.permit.custom.user.class is set to false for security reasons,
which means that
InputInitializer, VertexManager, or OutputCommiter running in DAGAppMaster may not use custom Java classes.
Hence
executing a query calling UDFs or using JdbcStorageHandler may try to load custom Java classes and generate ClassNotFoundException, as in:
# add jar hdfs:///user/hive/custom-udf.jar;
# create temporary function json_array_explode as 'com.hive.udf.JsonArrayExplode';
# --- while executing a query calling json_array_explode
Caused by: java.lang.ClassNotFoundException: come.hive.udf.JsonArrayExplode
# --- while executing a query using JdbcStorageHandler
Caused by: java.lang.ClassNotFoundException: org.apache.hive.storage.jdbc.JdbcInputFormat
To prevent ClassNotFoundException in such a case,
set mr3.am.permit.custom.user.class to true in mr3-site.xml.
13. When using Kerberized HDFS, executing a query with no input files fails with AccessControlException.
If Kerberized HDFS is used, creating a fresh table or inserting values to an existing table may fail, while executing queries only reading data works okay.
... org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
...
This error occurs if the configuration key hive.mr3.dag.additional.credentials.source
is not set in hive-site.xml.
See Accessing Secure HDFS for details.
A similar error can occur inside DAGAppMaster while generating splits. (The log of DAGAppMaster reports credentials associated with each DAG.)
2023-08-31 15:24:19,402 [main] INFO ContainerWorker [] - Credentials for Y@container_1694103365516_0016_01_000004: SecretKeys = 0, Tokens = 2: List(HDFS_DELEGATION_TOKEN, mr3.job)
2023-08-31 16:19:08,183 [DAG1-Input-4-3] WARN org.apache.hadoop.ipc.Client [] - Exception encountered while connecting to the server : org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
2023-08-31 16:19:08,195 [DAG1-Map 1] ERROR Vertex [] - RootInput order_detail failed on Vertex Map 1
com.datamonad.mr3.api.common.AMInputInitializerException: order_detail
at
...
Caused by: java.io.IOException: org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
...
In such a case,
check if the configuration key dfs.encryption.key.provider.uri
or hadoop.security.key.provider.path is set in core-site.xml.
See Accessing Secure HDFS for details.
14. The execution fails with OutOfMemoryError from PipelinedSorter.allocateSpace().
This usually happens when the value for the configuration key tez.runtime.io.sort.mb
is too large for the amount of available memory
and the type of the garbage collector in use.
The user can try a smaller value for tez.runtime.io.sort.mb or
set tez.runtime.pipelined.sorter.lazy-allocate.memory to false.
See Performance Tuning
for more details.
15. Loading a table fails with FileAlreadyExistsException.
Loading a table may fail with FileAlreadyExistsException, e.g.:
Caused by: org.apache.hadoop.fs.FileAlreadyExistsException: Failed to rename s3a://hivemr3/warehouse/tpcds_bin_partitioned_orc_1004.db/.hive-staging_hive_2023-05-17_07-37-59_392_7290354321306036074-2/-ext-10002/000000_0/delta_0000001_0000001_0000/bucket_00000 to s3a://hivemr3/warehouse/tpcds_bin_partitioned_orc_1004.db/web_site/delta_0000001_0000001_0000/bucket_00000; destination file exists
This usually happens when speculative executing is enabled.
The user can disable speculative execution by setting the configuration key hive.mr3.am.task.concurrent.run.threshold.percent to 100 in hive-site.xml.
16. The first query executed after starting Hive on MR3 runs very slow.
This usually occurs when mr3.am.min.cluster.resource.memory.mb and mr3.am.min.cluster.resource.cpu.cores are set to too small values.
Before creating ContainerWorkers, MR3 estimates the amount of cluster resources available
with these two configuration parameters.
If their values are too small,
MR3 creates only a small number of mappers for reading input data,
thus considerably delaying their completion.
17. Hive on MR3 runs slow when using Parquet.
Hive on MR3 provides better support for ORC than Parquet, so the user should prefer ORC to Parquet for performance. Parquet may result in slower performance especially if it uses DATE, DECIMAL, TIMESTAMP.
18. Metastore does not collect all statistics even with both hive.stats.autogather and hive.stats.column.autogather set to true
The user should manually execute the analyze table command.
18. java.lang.OutOfMemoryError
There is no universal solution to the problem of OutOfMemoryError.
Here is a list of suggestions for reducing memory pressure in MR3.
- Set
runtime.io.sortto a smaller value intez-site.xml. See Basic Performance Tuning. - Set
tez.runtime.use.free.memory.fetched.inputto false intez-site.xml. See Basic Performance Tuning. - If
OutOfMemoryErroroccurs during ordered shuffle, try a smaller value fortez.runtime.shuffle.merge.percentintez-site.xml. - For executing batch queries, set
mr3.container.task.failure.num.sleepsto a non-zero value inmr3-site.xml. See Basic Performance Tuning.
19. Compaction jobs get stuck in the state of ready for cleaning.
20. Creating Iceberg tables fails.
This can happen when speculative executing is enabled.
The user can disable speculative execution by setting the configuration key hive.mr3.am.task.concurrent.run.threshold.percent to 100 in hive-site.xml.
