MR3 is constantly evolving with new updates and features. Below is a partial list of planned updates and features of MR3. Developing an update or feature usually takes a few weeks to a few months, but it can take much longer (a year or two) if it involves research as well.
Support for Celeborn (in MR3 1.8)
MR3 can use Celeborn as remote shuffle service. Since intermediate data is stored on Celeborn worker nodes rather than on local disks. one of the key benefits of using Celeborn is that MR3 now needs only half as much space on local disks. The lower requirement on local disk storage is particularly important when running MR3 on public clouds.
Support for standalone mode (in MR3 1.7)
MR3 supports standalone mode in which the user manually executes DAGAppMaster and ContainerWorkers, rather than relying on the underlying resource manager such as Hadoop or Kubernetes. In standalone mode, installing Hive on MR3 is just as easy as installing Presto or Trino.
Support for Java 11 and higher (in MR3 1.7)
Java is evolving fast, but MR3 still requires Java 8. On Hadoop, it is not easy to migrate to a higher version such as Java 11 because of potential dependency problems. On Kubernetes, however, it suffices to check dependency problems in a local cluster. Thus we plan to upgrade MR3 to use Java 11 or higher, and experiment with it on Kubernetes. In particular, new garbage collectors available in recent versions of Java (such as Shenandoah and ZGC) may be able to instantly boost the performance of MR3 for free.
Integrating Hive on MR3 and Spark on MR3 (in MR3 1.5)
Hive and Spark can complement each other in data warehousing. For example, Hive lends itself well to serving concurrent requests from end users via HiveServer2, whereas Spark lends itself well to manipulating data in and out of the data warehouse in a flexible way. By configuring Hive on MR3 and Spark on MR3 to share Metastore in the same Kubernetes cluster, the user can exploit the strengths of both systems.
MapReduce on MR3 (in MR3 1.4)
MR3 is not designed specifically for Apache Hive. In fact, MR3 started its life as a general purpose execution engine and thus can easily execute MapReduce jobs by converting to DAGs with two Vertexes. As a new application of MR3, we have implemented MapReduce on MR3 which allows the execution legacy MapReduce code on Kubernetes as well as on Hadoop. All the strengths of MR3, such as concurrent DAGs, cross-DAG container reuse, fault tolerance, and autoscaling, are available when running MapReduce jobs.
Spark on MR3 (in MR3 1.3)
Spark on MR3 is an add-on to Spark which replaces the scheduler backend of Spark with MR3. It exploits TaskScheduler of MR3 to recycle YARN containers or Kubernetes Pods among multiple Spark drivers, and delegates the scheduling of individual tasks to MR3. Hence it can be useful when multiple Spark drivers share a common cluster. As Spark on MR3 is just an add-on, it requires no change to Spark.
Backend for AWS Fargate (in MR3 1.2)
Currently MR3 implements backends for Yarn and Kubernetes resource schedulers. Another resource scheduler under consideration is AWS Fargate. Since its unit of resource allocation is containers, AWS Fargate can make MR3 much less likely to suffer from over-provisioning of cluster resources than Yarn and Kubernetes. In conjunction with the support for autoscaling in MR3, the backend for AWS Fargate may enable MR3 to finish the execution of DAGs faster (just by creating more containers as needed) while reducing the overall cost (just by deleting idle containers as soon as possible).
Support for Prometheus (in MR3 1.2)
Currently MR3-UI enables users to watch the progress of individual DAGs, but MR3 does not provide a way to monitor the state of the cluster. We plan to extend MR3 so that users can use Prometheus to monitor the state of DAGAppMaster and ContainerWorkers.
Task scheduling to reduce the turnaround time (research underway)
TaskScheduler of MR3 exploits Task priorities and Vertex dependencies in order to maximize the throughput and minimize the turnaround time. The current implementation is the outcome of a research project, but we continue to investigate new ways of scheduling Tasks in order to reduce the turnaround time for DAGs in concurrent environments. While Task scheduling has always been an active research area, our problem differs from previous research in a significant way in that we assume 1) containers shared by concurrent DAGs, as opposed to containers dedicated to individual DAGs, and 2) containers capable of executing multiple Tasks concurrently, as opposed to containers executing one Task at a time.
Online pull
Like Hadoop MapReduce, MR3 uses the pull model for moving data from producers to consumers, in which a consumer requests, or pulls, its partition after a certain number of producers write their output to local disk. An alternative strategy is to use the push model in which a producer immediately passes, or pushes, its output to consumers. The push model is known to be much faster than the pull model because of its extensive use of memory for storing intermediate data, but makes it hard to implement fault tolerance reliably. (Ironically Presto is based on the push model and does not support fault tolerance for a good reason, but runs much slower than Hive on MR3 which uses the pull model!)
Despite its inherent performance problem, the pull model has been considered as the only choice for an execution engine when fault tolerance is a must-have, as summarized in the following series of papers on Hadoop MapReduce:
- Pavlo et al. (A Comparison of Approaches to Large-scale Data Analysis, SIGMOD 2009) point out that Hadoop MapReduce has a serious performance problem related to the pull model.
- Dean and Ghemawat (MapReduce: A Flexible Data Processing Tool, Communications of the ACM, 2010) acknowledge that the pull model has a performance problem, but argue that the push model is inappropriate because of the requirement of fault tolerance.
- Stonebraker et al. (MapReduce and Parallel DBMSs: Friends or Foes?, Communications of the ACM, 2010) predict that the pull model is fundamental to fault tolerance and thus unlikely to be changed in Hadoop MapReduce.
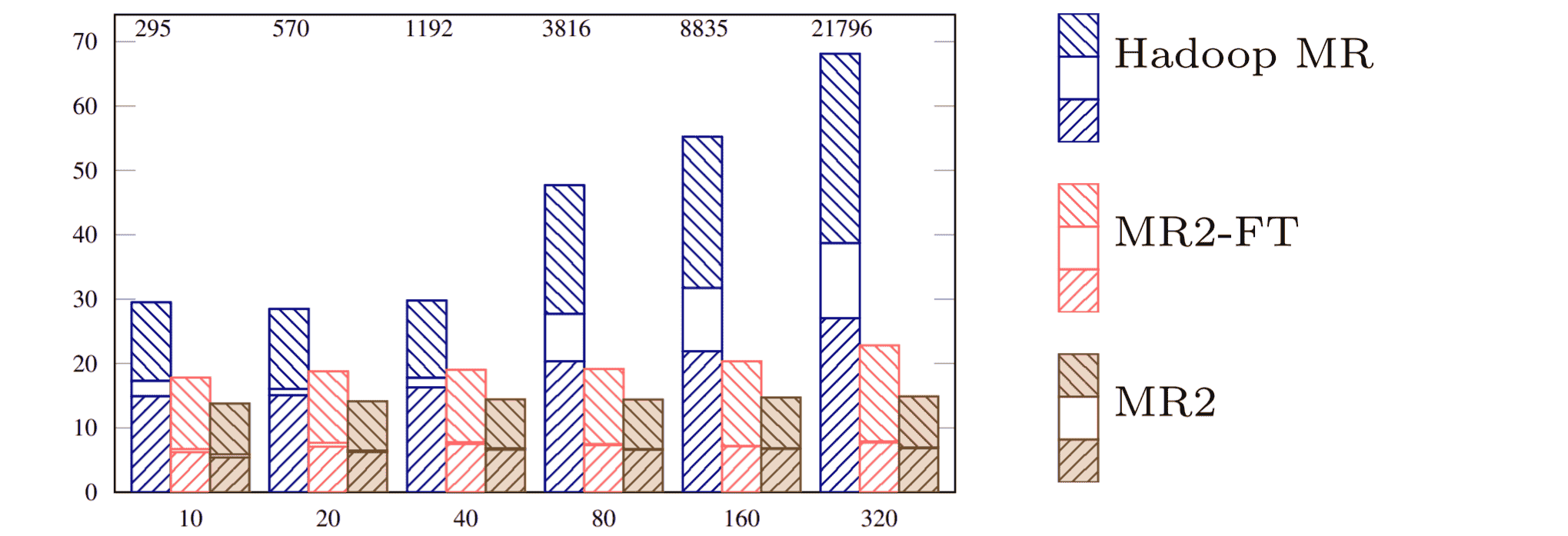
Online pull is a new way of shuffling data from mappers to reducers which extends the pull model by partially implementing the push model when plenty of memory is available. Thus it aims to achieve the best of two opposite worlds: fault tolerance of the pull model and fast speed of the push model. Our preliminary result (in the case of unordered shuffling) shows that online pull can significantly improve the performance of Hive on MR3 without compromising its support for fault tolerance.
The idea of online pull builds on our two-year experience of developing a prototype execution engine MR2 (a predecessor of MR3) and multi-year experience of developing MR3. The prototype execution engine MR2 implements the push model in its purest form. The following graph shows the result of running TeraSort 1) on Hadoop MapReduce and 2) on MR2 in a cluster of 90 nodes when varying the size of input data up to 320GB per node (with GB of input data per node in the x-axis and execution time per GB in the y-axis). In the course of developing MR3, we have also experimented with a new runtime called ASM which is based on the push model. Our ultimate goal is to bring the performance of MR3 to the next level with the speed and stability of the push model as evidenced by MR2.