Restrictions and assumptions
For Hive on MR3, running on Amazon EKS is similar to running on Kubernetes, but has the following restrictions:
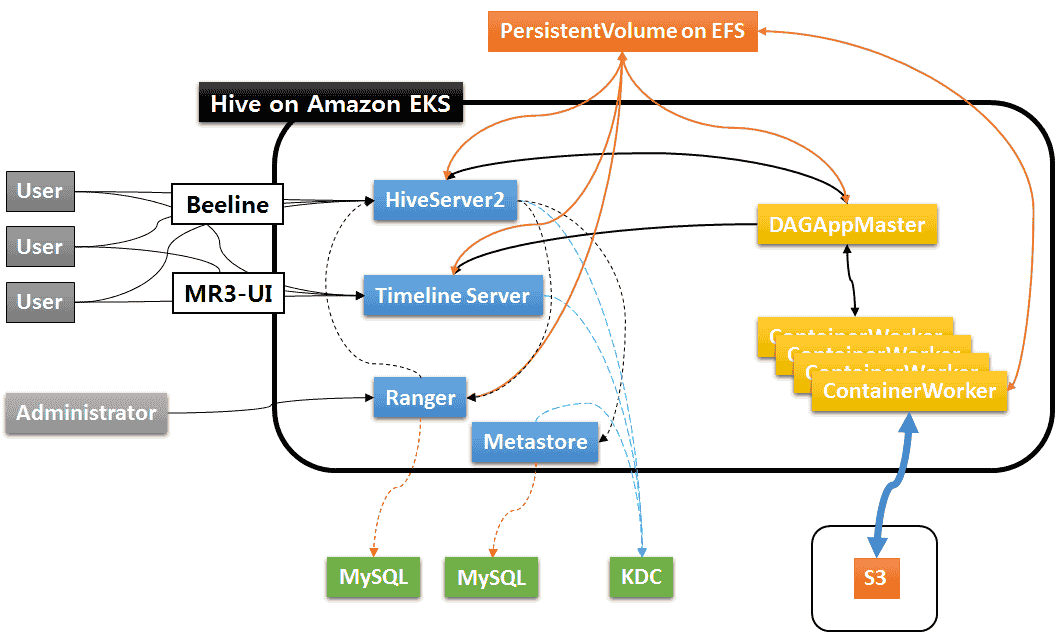
- If containers need to share files across multiple Availability Zones, the user should create a PersistentVolumeClaim using Amazon EFS (Elastic File System), not EBS (Elastic Block Store), Alternatively the user may use S3 without creating a PersistentVolumeClaim.
- We assume that the data source is on S3 (Simple Storage Service).
- For local disks for writing intermediate data in ContainerWorkers, the user should be able to either create EC2 instances with instance stores (i.e., local disks physically attached to host machines) or mount EBS volumes to EC2 instances. The user may choose to use the root partition for a local disk, but it runs the risk of running out of disk space in the middle of running a query.
We assume that the administrator user provides the following external components. For the database for Metastore and Ranger, Postgres and MS SQL are also okay.
- MySQL database for Metastore
- MySQL database for Ranger (which can be the same MySQL database for Metastore)
- KDC (Key Distribution Center) for managing Kerberos tickets
As we do not use HDFS, we do not require KMS (Key Management Server) for managing impersonation and delegation tokens. The cluster on Amazon EKS is depicted in the following diagram:
Cloning the executable scripts
This section gives details on how to create a cluster on Amazon EKS. We assume that the user has already created a Docker image by following the instruction in Installing on Kubernetes. Or the user can use a pre-built Docker image available at DockerHub, in which case it suffices to download an MR3 release containing the executable scripts.
A pre-built Docker image is intended for evaluating Hive on MR3 with a limit on the aggregate capacity of MR3 workers. For running Hive on MR3 in production, contact us.
$ git clone https://github.com/mr3project/mr3-run-k8s.git
Before proceeding, set RUN_AWS_EKS to true in kubernetes/env.sh.
$ cd mr3-run-k8s/kubernetes/
$ vi env.sh
RUN_AWS_EKS=true
