After installing Hive on MR3 on Kubernetes by following the instruction in Installing on Kubernetes, the user can create a Kubernetes cluster in which Hive on MR3 runs in conjunction with additional components for managing data security and user interface. A Kubernetes cluster created with Hive on MR3 consists of the following components:
- Key components of Hive on MR3 – Metastore, HiveServer2, DAGAppMaster, and ContainerWorkers
- Apache Timeline Server for preserving history logs
- Apache Ranger for managing data security
Prerequisites for running Hive on MR3 on Kubernetes
In order to run Hive on MR3 on Kubernetes, the following requirements should be met.
-
A running Kubernetes cluster should be available and the user should be able to execute the command
kubectl. -
A data source, such as HDFS or Amazon S3 (Simple Storage Service), should be available.
-
A PersistentVolume can be created for storing transient data such as the result of running queries and history logs created by Timeline Server. For example, we use a PersistentVolume to pass the result of running queries from ContainerWorkers to HiveServer2. Note that a PersistentVolume stores only transient data that becomes obsolete once the Kubernetes cluster is destroyed. Thus it does not serve as a remote data source for storing Hive tables.
The PersistentVolume should be writable to 1) the user with the same UID in
kubernetes/hive/Dockerfile(UID 1000 for userhiveby default), and 2) user nobody (corresponding to root user) if Ranger is to be used for authorization.The user can also use HDFS or Amazon S3 instead of a PersistentVolume. For details, see Using HDFS instead of PersistentVolumes or Using Amazon S3 instead of PersistentVolumes.
-
In order to run Metastore as a Pod, a MySQL database (or a compatible database such as PostgresSQL) for Metastore should be accessible. An existing Metastore can also be used.
-
Optionally a MySQL database for Ranger should be accessible. It is okay to reuse the MySQL database for Metastore.
Before trying to run Hive on MR3 on Kubernetes, check if swap space is disabled in the Kubernetes cluster.
hostPath volumes created from local directories
Usually Hive on MR3 requires three types of storage:
- Data source such as HDFS or Amazon S3
- PersistentVolume for storing transient data
- hostPath volumes for storing intermediate data in ContainerWorker Pods
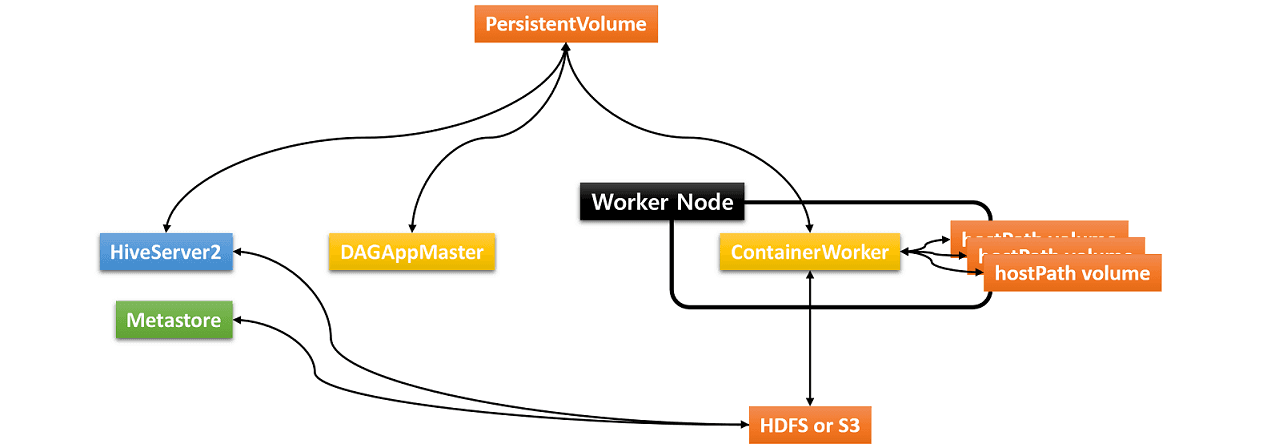
The hostPath volumes are created and mounted by MR3 at runtime for each ContainerWorker Pod.
These hostPath volumes hold intermediate data to be shuffled (by shuffle handlers) between ContainerWorker Pods.
In order to be able to create the same set of hostPath volumes for every ContainerWorker Pod,
an identical set of local directories should be ready in all worker nodes (where ContainerWorker Pods are created).
Since ContainerWorkers run as the user specified in kubernetes/hive/Dockerfile,
the same user should have write permission on these local directories.
For example,
if every worker node has three local directories /data1/k8s, /data2/k8s, and /data3/k8s for hostPath volumes,
the configuration key mr3.k8s.pod.worker.hostpaths in kubernetes/conf/mr3-site.xml should be set to /data1/k8s,/data2/k8s,/data3/k8s.
(For more details, see Configuring Pods.)
The local directories should be writable to the user with the same UID in kubernetes/hive/Dockerfile
(UID 1000 for user hive by default).
If the user does not have proper write permission, a query usually fails with a message No space available in any of the local directories.
For updating the ownership or permission when ContainerWorker Pods start,
see Running as a Non-root User.
For the sake of performance, all local directories on a worker node should reside on different local disks. That is, it does not improve the performance to use multiple local directories residing on the same local disk. The user should make sure that the local disks have enough space during the execution of Hive on MR3. For using emptyDir volumes instead of hostPath volumes, see Configuring Pods.
Using Kerberos (Optional)
For using Kerberos for authentication, the following requirements should be met.
- KDC (Key Distribution Center) for managing Kerberos tickets should be set up by the administrator user.
- If Metastore runs in a secure mode, its service keytab file should be copied to the directory
kubernetes/key. - If HiveServer2 uses Kerberos-based authentication, its service keytab file should be copied to the directory
kubernetes/key. - In order to renew HDFS and Hive tokens in DAGAppMaster (for
mr3.keytabinmr3-site.xml) and ContainerWorkers (formr3.k8s.keytab.mount.fileinmr3-site.xml), a keytab file should be copied to the directorykubernetes/key. The keytab file is unnecessary if HDFS is not used. - For using secure (Kerberized) HDFS as a remote data source, KMS (Key Management Server) should be set up for managing impersonation and delegation tokens. If secure HDFS is part of a secure Hadoop cluster, the administrator user can reuse the existing KMS server.
In general, we need two service keytab files and an ordinary keytab file to be specified by three environment variables in kubernetes/env.sh:

In practice, it is okay to use a common service keytab file for both Metastore and HiveServer2. Furthermore it is also okay to use the same service keytab file for renewing HDFS and Hive tokens. Thus the user can use a single service keytab file for running Hive on Kubernetes.
Kubernetes cluster with Hive on MR3
The following diagram depicts a Kubernetes cluster created with Hive on MR3 along with external components for a typical production environment.
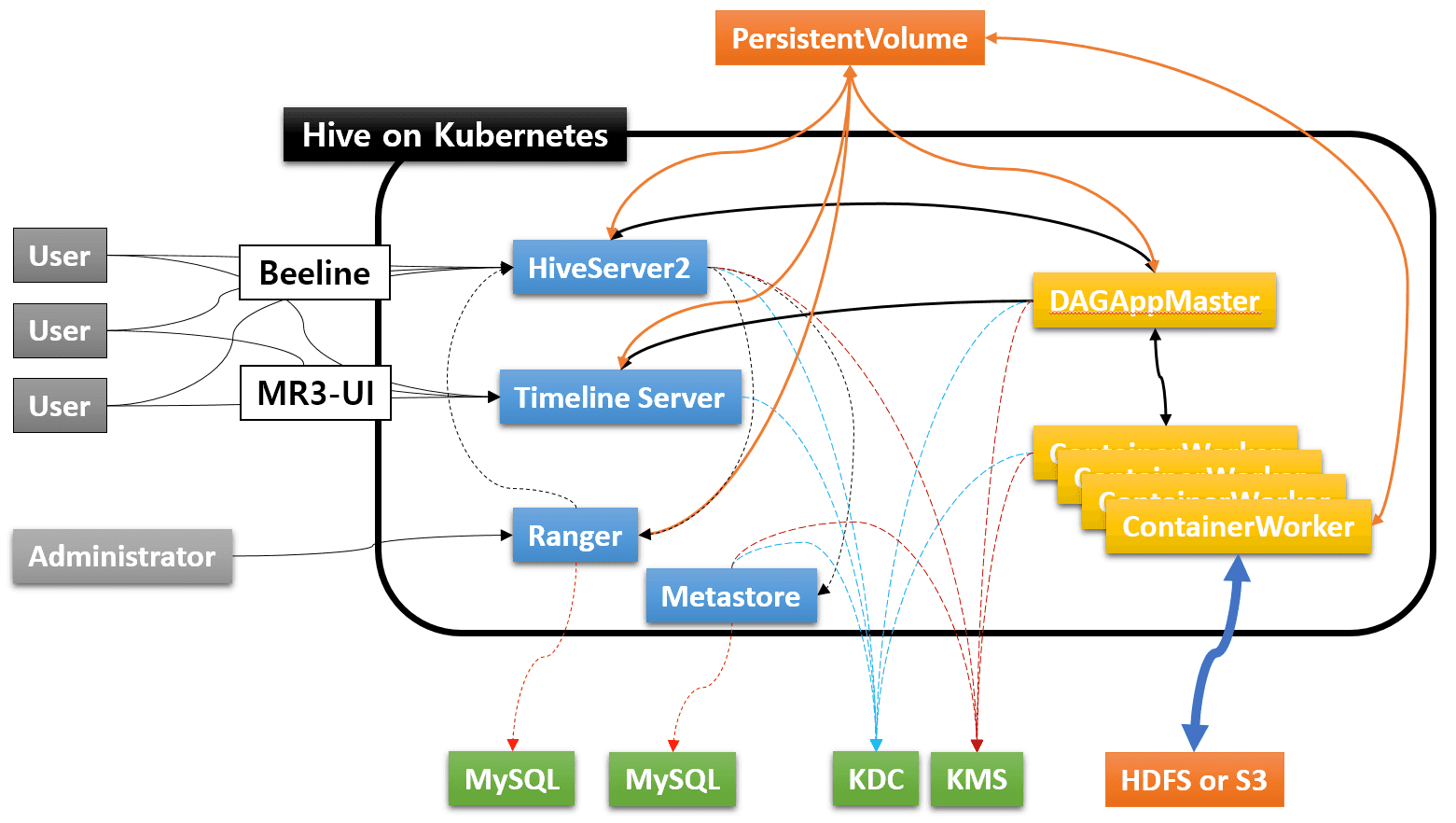
An ordinary user can run Beeline to submit queries to HiveServer2, and check the status of queries on the web browser via MR3-UI. The administrator user can connect to Ranger to manage data security. The administrator user can also log on directly to the HiveServer2 Pod in order to manage running DAGs (e.g., kill DAGs).
The rest of this section gives details on how to create a Kubernetes cluster based on the above setting and a few variations thereof. We assume some familiarity with key concepts in Kubernetes such as Pods, Containers, Volumes, ConfigMaps, and Secrets.
