DaemonTask for LLAP I/O
Hive 2.x and later running on top of MR3 support LLAP (Low Latency Analytical Processing) I/O.
If a ContainerWorker starts with LLAP I/O enabled, it wraps every HiveInputFormat object with an LlapInputFormat object so as to cache all data read via HiveInputFormat.
In conjunction with the ability to execute multiple TaskAttempts concurrently inside a single ContainerWorker,
the support for LLAP I/O makes Hive on MR3 functionally equivalent to Hive-LLAP.
By virtue of DaemonTasks already available in MR3, it is easy to implement LLAP I/O in Hive on MR3. If LLAP I/O is enabled, a ContainerGroup creates an MR3 DaemonTask that is responsible for managing LLAP I/O. When a ContainerWorker starts, a DaemonTaskAttempt is created to initialize the LLAP I/O module. Once initialized, the LLAP I/O module works in the background to serve requests from ordinary TaskAttempts.
LLAP I/O on Kubernetes
While Hive on MR3 on Kubernetes can exploit LLAP I/O precisely in the same way as on Hadoop, its use of LLAP I/O deserves special attention because the separation of compute and storage makes it highly desirable to enable LLAP I/O. Note that if the data source is co-located with compute nodes, the use of LLAP I/O does not always result in a decrease in the execution time for two reasons:
- The cache allocated for LLAP I/O is useful only for Map Vertexes and irrelevant to Reduce Vertexes. Hence, for those queries that read a small amount of input data and spend most of the execution time in Reduce Vertexes, the cache is underutilized. For such queries, repurposing the cache for running Reduce Tasks would be a much better choice.
- Depending on the underlying hardware, reading input data from local disks and transferring over internal network (e.g., reading from NVMe SSDs and transferring over InfiniBand) may be not considerably slower than reading directly from the cache for LLAP I/O.
Thus the memory overhead for LLAP I/O should be traded off against its advantage only when network and disk access is relatively slow, which is usually the case when running Hive on MR3 on Kubernetes. In essence, the separation of compute and storage enables us to make the best use of LLAP I/O.
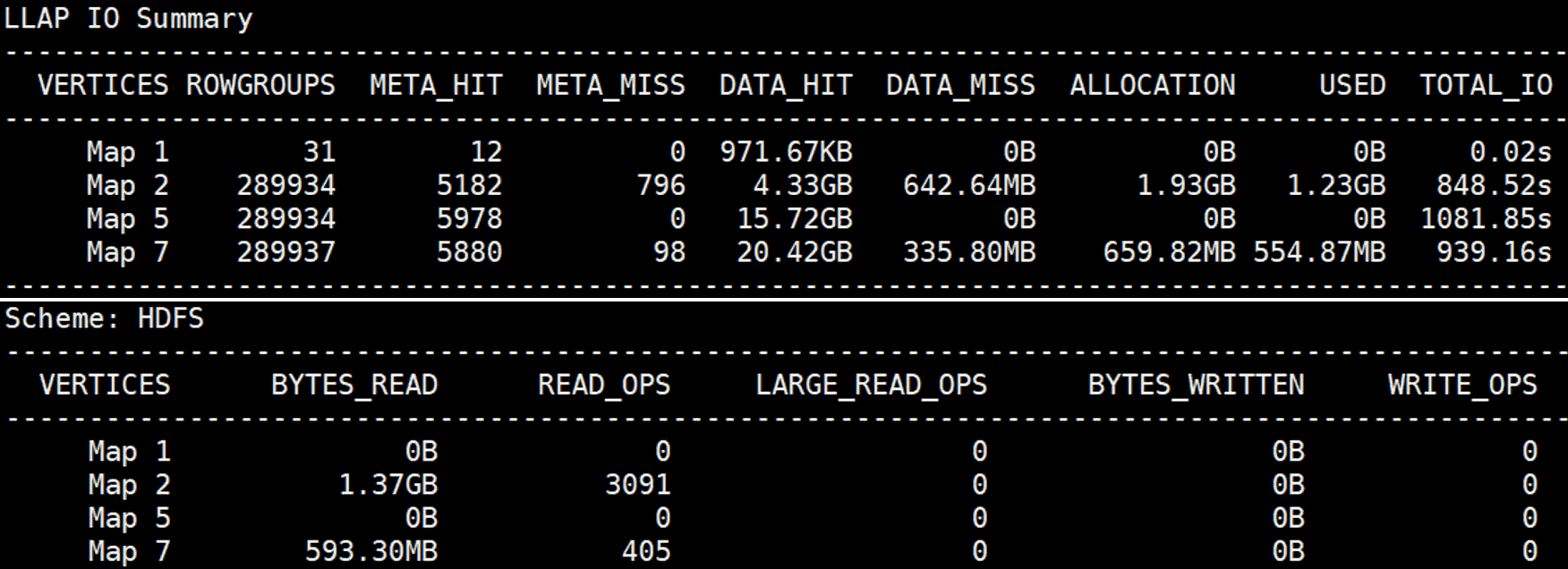
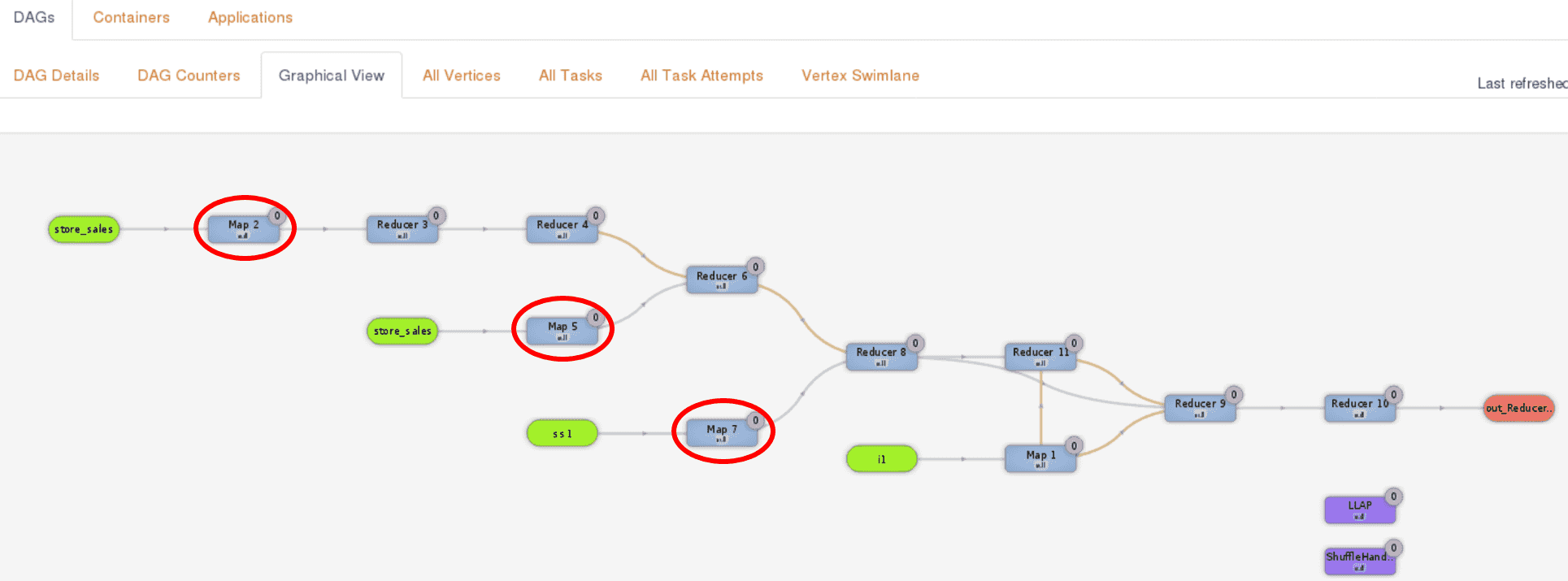
To illustrate the benefit of using LLAP I/O for Hive on MR3 on Kubernetes, we show the result of running query 44 of the TPC-DS benchmark on a dataset of 1TB. We use two separate clusters connected over 10 Gigabit network: a compute cluster for running Kubernetes and a storage cluster for hosting HDFS. Query 44 spends most of its execution time on three Map Vertexes (Map 2, Map 5, and Map 7 in red circles in the following screenshot from MR3-UI):
In the first run, the cache for LLAP I/O is empty, and the three Map Vertexes read 80.3GB of data from HDFS (BYTES_READ in Scheme: HDFS),
which is all read from local disks in the storage cluster and then transferred over network to the compute cluster.
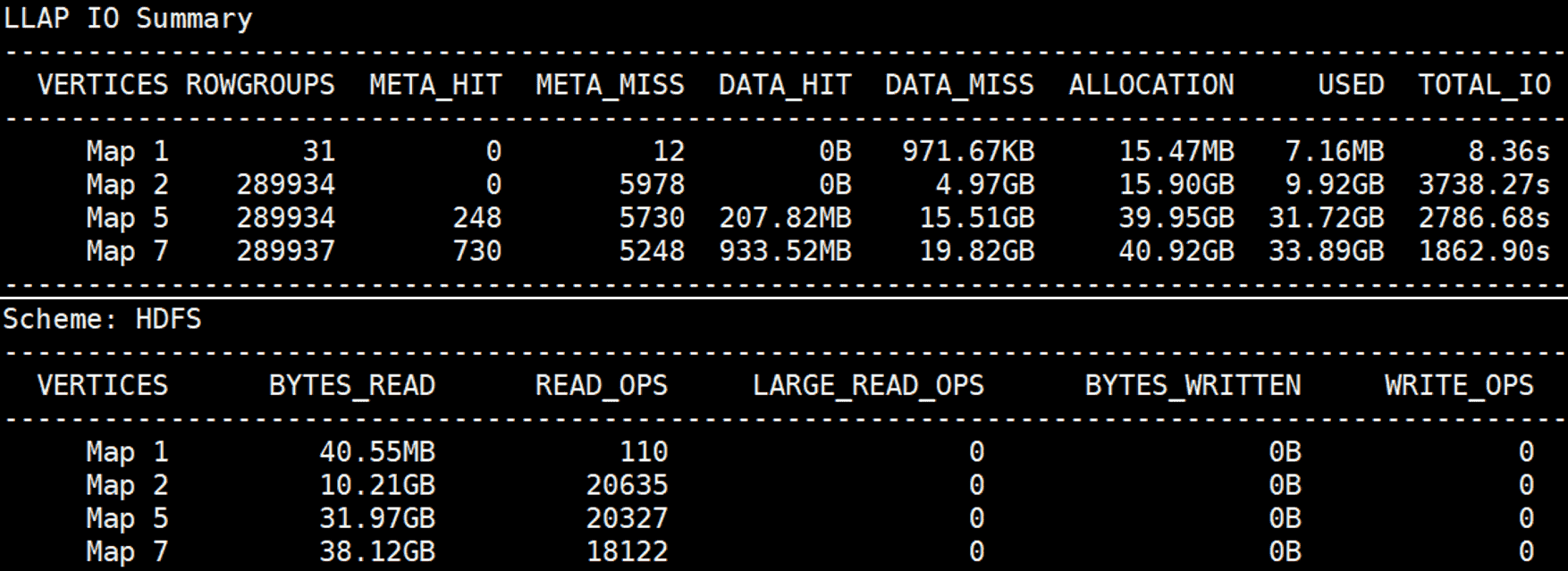
After a few runs, the cache is populated with input data, and the three Map Vertexes read only 1.96GB of data from HDFS (BYTES_READ in Scheme: HDFS)
while most of the input data is directly provided by LLAP I/O (DATA_HIT in LLAP IO Summary).
As a result, we observe a significant decrease in the execution time.