This page shows how to operate Hive on MR3 in a non-secure Hortonworks HDP cluster without Kerberos. An ordinary user (not an administrator of the Hadoop cluster) will run HiveServer2. For Metastore, we will use the instance already running on HDP. By following the instruction, the user will learn:
- how to install and configure Hive on MR3 in a non-secure HDP cluster without Kerberos
- how to start and stop HiveServer2
- how to create Beeline connections
This scenario has the following prerequisites:
- Java 8 or Java 17 is available. Java 17 should be installed in the same directory on every node.
- A non-secure HDP cluster is available.
- The user has administrator access to Ambari of HDP.
- The user has administrator access to HDFS.
- The user has access to the home directory and
/tmpdirectory on HDFS.
This scenario should take less than 30 minutes to complete, not including the time for downloading an MR3 release. The user can apply the instruction to operate Hive on MR3 in any Hadoop cluster where Metastore is already running.
For asking any questions, please visit MR3 Google Group or join MR3 Slack.
Installation
From Hive on MR3 1.8, Metastore of HDP is not completely compatible with Hive on MR3 because different versions of Kryo are used (Kryo 3 in Metastore of HDP and Kryo 4 in Hive on MR3). Hence some functions may fail with error messages like:
Error: Error while compiling statement: FAILED: SemanticException MetaException(message:Encountered unregistered class ID: 112 Serialization trace: typeInfo (org.apache.hadoop.hive.ql.plan.ExprNodeGenericFuncDesc) chidren (org.apache.hadoop.hive.ql.plan.ExprNodeGenericFuncDesc)) (state=42000,code=40000)The user can either:
- run Metatore in Hive on MR3 (using the same Metastore database of HDP), or
- rebuild Hive on MR3 built with Kryo 3.
In our example, we use an ordinary user gla for installing and running HiveServer2.
Download a pre-built MR3 release compatible with Metastore of HDP on a node where the command yarn is available.
We choose the pre-built MR3 release based on Hive 3.1.3.
Rename the new directory to mr3-run and change the working directory.
Renaming the new directory is not strictly necessary,
but it is recommended because the sample configuration file hive-site.xml included in the MR3 release uses the same directory name.
A pre-built MR3 release is intended for evaluating Hive on MR3 with a limit on the aggregate capacity of MR3 workers. For running Hive on MR3 in production, contact us.
$ wget https://github.com/mr3project/mr3-release/releases/download/v1.11/hivemr3-1.11-hive3.1.3-k8s.tar.gz
$ gunzip -c hivemr3-1.11-hive3.1.3-k8s.tar.gz| tar xvf -;
$ mv hivemr3-1.11-hive3.1.3-k8s/ mr3-run
$ cd mr3-run/
$ wget https://github.com/mr3project/mr3-release/releases/download/v1.11/hivemr3-1.11-java17-hive3.1.3-k8s.tar.gz
$ gunzip -c hivemr3-1.11-java17-hive3.1.3-k8s.tar.gz| tar xvf -;
$ mv hivemr3-1.11-java17-hive3.1.3-k8s/ mr3-run
$ cd mr3-run/
Configuring Java and Hadoop
Open env.sh and set JAVA_HOME and PATH if necessary.
Set HADOOP_HOME to the Hadoop installation directory.
$ vi env.sh
export JAVA_HOME=/usr/jdk64/jdk1.8 # Java 8
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/hdp/3.1.4.0-315/hadoop
USE_JAVA_17=false
$ vi env.sh
export JAVA_HOME=/usr/jdk64/jdk17 # Java 17
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/hdp/3.1.4.0-315/hadoop
USE_JAVA_17=true
For Java 8 only
Update the configuration keys mr3.am.launch.cmd-opts and mr3.container.launch.cmd-opts
in conf/tpcds/mr3/mr3-site.xml.
- add
-XX:+AggressiveOptsfor performance. - remove
--add-opens java.base/java.net=ALL-UNNAMED --add-opens java.base/java.util=ALL-UNNAMED --add-opens java.base/java.time=ALL-UNNAMED --add-opens java.base/java.util.concurrent.atomic=ALL-UNNAMED --add-opens java.base/java.io=ALL-UNNAMED ...(which are Java 17 options).
Update the configuration keys mr3.am.launch.env and mr3.container.launch.env
in conf/tpcds/mr3/mr3-site.xml.
- remove
JAVA_HOME=/home/hive/jdk17/.
For Java 17 only
Update the configuration keys mr3.am.launch.env and mr3.container.launch.env
in conf/tpcds/mr3/mr3-site.xml.
- set
JAVA_HOME=/home/hive/jdk17/to point to the installation directory of Java 17 on every worker node.
In order to execute Metastore and HiveServer2 with Java 17,
JAVA_HOME in hadoop-env.sh in the Hadoop configuration directory
should also be set to point to the installation directory of Java 17.
$ vi /etc/hadoop/conf/hadoop-env.sh
JAVA_HOME=/home/hive/jdk17/
Configuring Hive on MR3
Open env.sh and
set the following environment variables to adjust the memory size (in MB) to be allocated to each component:
HIVE_SERVER2_HEAPSIZEspecifies the memory size for HiveServer2.HIVE_CLIENT_HEAPSIZEspecifies the memory size of Beeline (beelinecommand).MR3_AM_HEAPSIZEspecifies the memory size of MR3 DAGAppMaster.
$ vi env.sh
HIVE_SERVER2_HEAPSIZE=16384
HIVE_CLIENT_HEAPSIZE=1024
MR3_AM_HEAPSIZE=10240
Open the Ambari webpage as the administrator user and find the information on Metastore:
Database Name, Database Username, Database URL, Hive Database Type, JDBC Driver Class, Database Password,
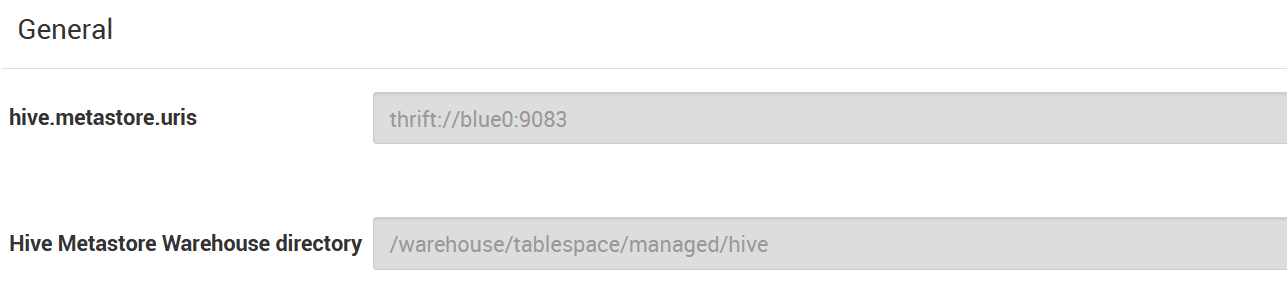
hive.metastore.uris, and Hive Metastore Warehouse directory.
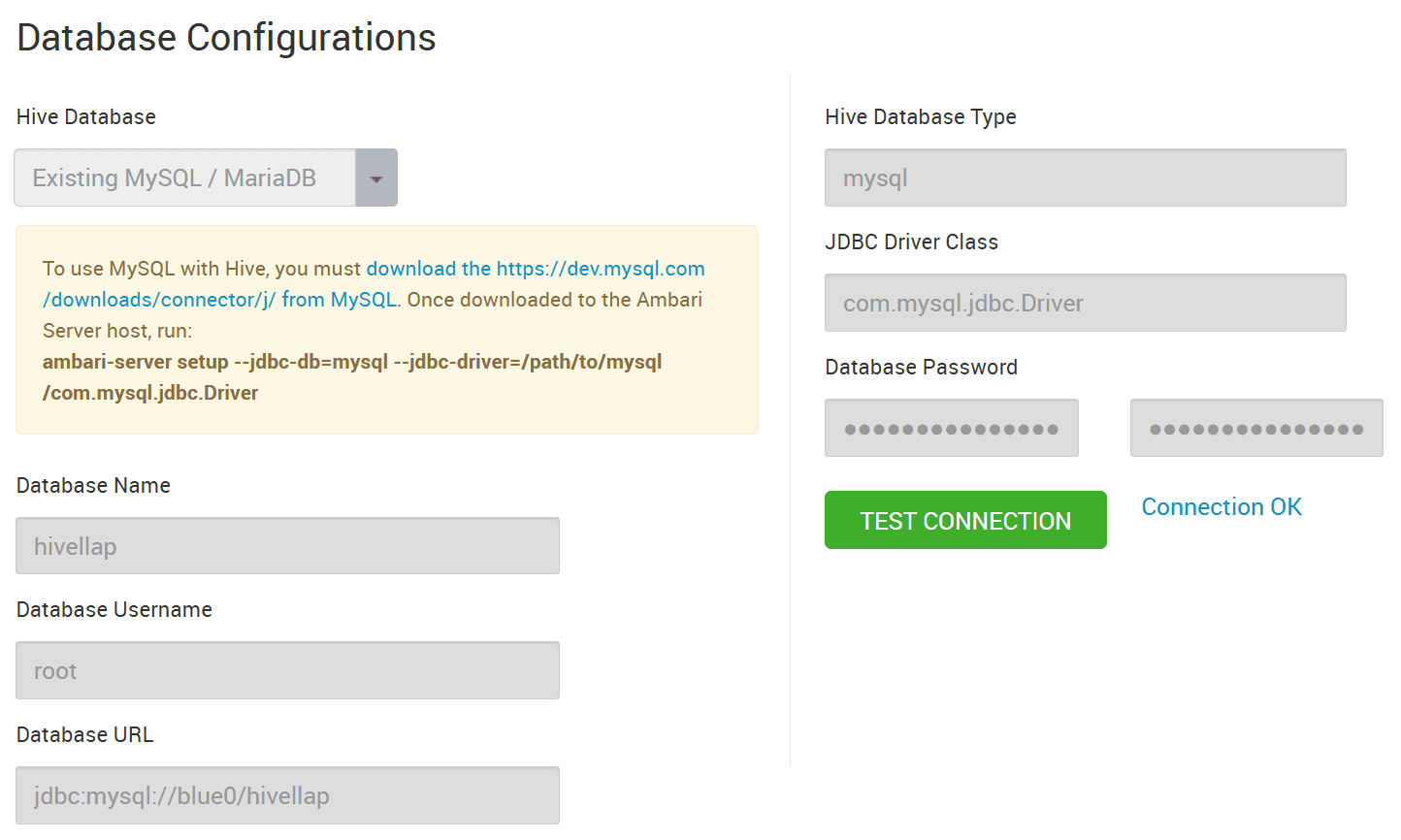
Set the following environment variables according to the information on Metastore.
Note the prefix HIVE3_ which corresponds to Hive 3 on MR3.
$ vi env.sh
HIVE3_DATABASE_HOST=blue0 # from Database URL
HIVE3_METASTORE_HOST=blue0 # from hive.metastore.uris
HIVE3_METASTORE_PORT=9083 # from hive.metastore.uris
HIVE3_METASTORE_LOCAL_PORT=9083
HIVE3_DATABASE_NAME=hivellap # from Database Name
HIVE3_HDFS_WAREHOUSE=/warehouse/tablespace/managed/hive # from Hive Metastore Warehouse directory
Set HIVE_MYSQL_DRIVER to specify the path to a MySQL connector jar file.
$ vi env.sh
HIVE_MYSQL_DRIVER=/usr/share/java/mysql-connector-java.jar
Set the following environment variables to indicate a non-secure HDP cluster.
$ vi env.sh
SECURE_MODE=false
TOKEN_RENEWAL_HDFS_ENABLED=false
TOKEN_RENEWAL_HIVE_ENABLED=false
HIVE_SERVER2_AUTHENTICATION=NONE
Configuring hive-site.xml
Open conf/tpcds/hive3/hive-site.xml and set the following configuration keys
according to the information on Metastore.
$ vi conf/tpcds/hive3/hive-site.xml
<property>
<name>hive.metastore.db.type</name>
<value>MYSQL</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
</property>
Set the following configuration keys
according to the current user name gla (instead of the default user hive) and the working directory (instead of the default directory /home/hive).
$ vi conf/tpcds/hive3/hive-site.xml
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/gla</value>
</property>
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/tmp/gla/operation_logs</value>
</property>
<property>
<name>hive.aux.jars.path</name>
<value>/home/gla/mr3-run/hive/hivejar/apache-hive-3.1.3-bin/lib/hive-llap-common-3.1.3.jar,/home/gla/mr3-run/hive/hivejar/apache-hive-3.1.3-bin/lib/hive-llap-server-3.1.3.jar,/home/gla/mr3-run/hive/hivejar/apache-hive-3.1.3-bin/lib/hive-llap-tez-3.1.3.jar</value>
</property>
The following configuration keys specify resources to be allocated to a Map Task, a Reduce Task, and a ContainerWorker. By default, we allocate 4GB and a single core to a Map Task and a Reduce Task. A single ContainerWorker can accommodate 10 concurrent Tasks.
$ vi conf/tpcds/hive3/hive-site.xml
<property>
<name>hive.mr3.map.task.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>hive.mr3.map.task.vcores</name>
<value>1</value>
</property>
<property>
<name>hive.mr3.reduce.task.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>hive.mr3.reduce.task.vcores</name>
<value>1</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.memory.mb</name>
<value>40960</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.vcores</name>
<value>10</value>
</property>
By default, we enable impersonation by setting hive.server2.enable.doAs to true.
$ vi conf/tpcds/hive3/hive-site.xml
<property>
<name>hive.server2.enable.doAs</name>
<value>true</value>
</property>
Creating directories on HDFS
The administrator user (e.g., hdfs) should create a directory for user gla.
# execute as the administrator user
$ hdfs dfs -mkdir /user/gla/
$ hdfs dfs -chown gla /user/gla/
The administrator user should also check that /tmp/gla
(corresponding to the configuration key hive.exec.scratchdir in hive-site.xml) does not exist on HDFS.
If the directory already exists (e.g., when running Hive on MR3 for the second time), make sure that its permission is set to 733.
HiveServer2 automatically creates a new directory with permission 733 if it does not exist.
# execute as the administrator user
$ hdfs dfs -ls /tmp/gla
ls: `/tmp/gla': No such file or directory
Then the user gla should create a directory for storing MR3 and Tez jar files.
$ printenv | grep USER
USER=gla
$ hdfs dfs -mkdir -p /user/gla/lib/
Load MR3 jar files.
$ mr3/upload-hdfslib-mr3.sh
Load Tez jar files.
$ tez/upload-hdfslib-tez.sh
Creating temporary directories
Optionally the user can create a new directory specified by hive.server2.logging.operation.log.location before starting HiveServer2.
$ ls -alt /tmp/gla/operation_logs
ls: cannot access /tmp/gla/operation_logs: No such file or directory
$ mkdir -p /tmp/gla/operation_logs
Updating core-site.xml of HDP
Open the Ambari webpage as the administrator user and set two new configuration keys
hadoop.proxyuser.gla.groups and hadoop.proxyuser.gla.hosts in core-site.xml.
Then restart HDFS, Yarn, and Metastore.
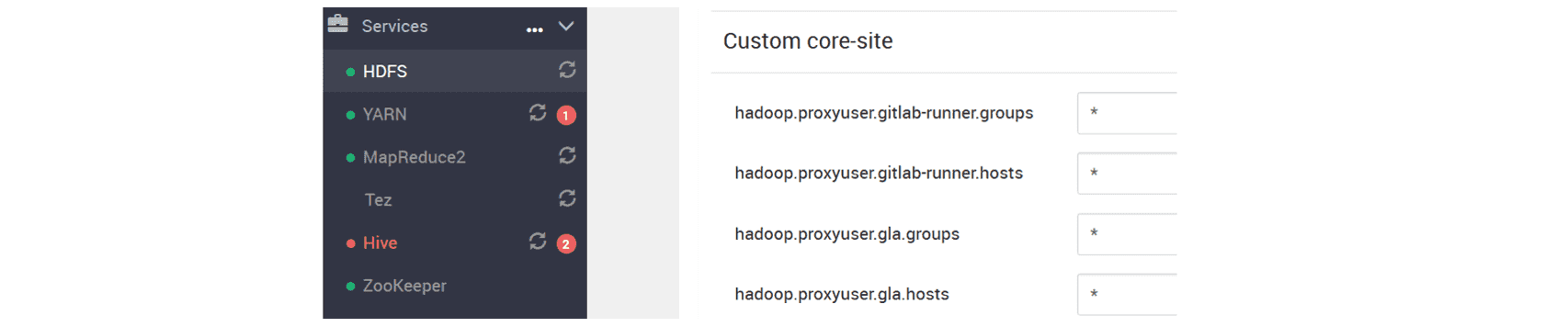
Without this step, HiveServer2 may fail to start with the following error (which is related to HIVE-19740).
2023-06-18T15:21:00,154 WARN [main] metastore.RetryingMetaStoreClient: MetaStoreClient lost connection. Attempting to reconnect (1 of 24) after 5s. getCurrentNotificationEventId
org.apache.thrift.TApplicationException: Internal error processing get_current_notificationEventId
Running HiveServer2
Run HiveServer2 using --tpcds option.
In order to use LocalProcess mode for MR3 DAGAppMaster, use --amprocess option.
$ hive/hiveserver2-service.sh start --tpcds
After a while, check if HiveServer2 has successfully started by inspecting its log file.
$ tail -f /data2/gla/mr3-run/hive/hiveserver2-service-result/hive-mr3--2023-06-19-00-28-16-8db63259/hive-logs/hive.log
...
2023-06-18T15:28:39,389 INFO [main] server.Server: Started @13972ms
2023-06-18T15:28:39,390 INFO [main] server.HiveServer2: Web UI has started on port 10502
2023-06-18T15:28:39,390 INFO [main] server.HiveServer2: HS2 interactive HA not enabled. Starting sessions..
2023-06-18T15:28:39,390 INFO [main] http.HttpServer: Started HttpServer[hiveserver2] on port 10502
The user can find a new Yarn application of type mr3 submitted by the user gla.
$ yarn application -list
...
application_1660836356025_0002 a91f2aae-6efe-43dc-87d2-1e4ac1b50b78 mr3 gla default RUNNING UNDEFINED 0% N/A
Running Beeline
Run Beeline using --tpcds option.
$ hive/run-beeline.sh --tpcds
# Running Beeline using Hive-MR3 (3.1.3) #
...
Connecting to jdbc:hive2://blue0:9832/;;
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.3 by Apache Hive
0: jdbc:hive2://blue0:9832/>
The user can find all databases registered to Metastore of HDP.
0: jdbc:hive2://blue0:9832/> show databases;
...
+----------------------------------+
| database_name |
+----------------------------------+
| default |
| information_schema |
| sys |
| tpcds_bin_partitioned_orc_10000 |
| tpcds_text_1000 |
| tpcds_text_10000 |
+----------------------------------+
6 rows selected (1.652 seconds)
Another user can also run Beeline to connect to the same HiveServer2.
In the following example, another ordinary user gitlab-runner runs Beeline
(where we assume that the directory hive/run-beeline-result/ is writable to user gitlab-runner).
$ printenv | grep USER
USER=gitlab-runner
$ pwd
/home/gla/mr3-run
$ hive/run-beeline.sh --tpcds
# Running Beeline using Hive-MR3 (3.1.3) #
...
Connecting to jdbc:hive2://blue0:9832/;;
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.3 by Apache Hive
0: jdbc:hive2://blue0:9832/>
Stopping HiveServer2
Stop HiveServer2 as user gla.
$ hive/hiveserver2-service.sh stop --tpcds
