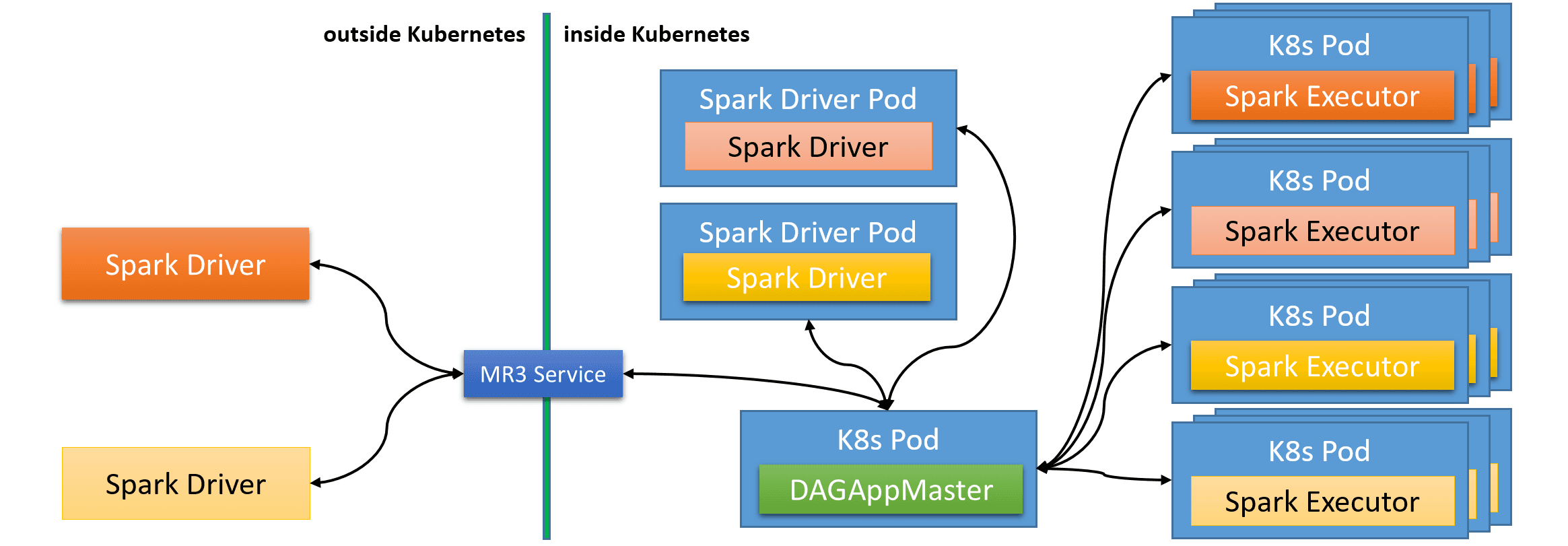
After following the instruction in Configuring Spark on MR3, the user can create a Kubernetes cluster for running Spark on MR3. Multiple Spark drivers can run either outside Kubernetes or in Kubernetes Pods while sharing a common DAGAppMaster Pod.
A running Kubernetes cluster should be available and the user should be able to execute the command kubectl.
Before trying to run Spark on MR3 on Kubernetes, check if swap space is disabled in the Kubernetes cluster.
Configuring the Kubernetes client
For running a Spark driver outside Kubernetes, the following configuration keys should be set.
For running a Spark driver inside Kubernetes, the user should comment out these configuration keys in mr3-site.xml
so that their default values are used.
mr3.k8s.api.server.urlspecifies the URL for the Kubernetes API server (e.g.,https://10.1.90.9:6443).mr3.k8s.client.config.filespecifies the configuration file (kubeconfig file) for creating a Kubernetes client (e.g.,~/.kube/config).mr3.k8s.service.account.use.token.ca.cert.pathshould be set to false.mr3.k8s.am.service.hostandmr3.k8s.am.service.portshould match the address specified inkubernetes/spark-yaml/mr3-service.yaml.
If the user plans to mix Spark drivers running inside and outside Kubernetes,
it is recommended to execute the first Spark driver inside Kubernetes with the above configuration keys commented out in mr3-site.xml.
This is because the first Spark driver creates a ConfigMap out of the directory kubernetes/spark/conf
and all Spark drivers running inside Kubernetes reuse this ConfigMap.
For a Spark driver running outside Kubernetes,
mr3-site.xml on the local node can be updated without affecting existing or future Spark drivers.
Setting host aliases
Since Kubernetes Pods may use a different DNS,
the user should set the configuration key mr3.k8s.host.aliases in mr3-site.xml if necessary.
- For running a Spark driver outside Kubernetes,
it should include a mapping for the node where the Spark driver is to run
so that Spark executors (which run in ContainerWorker Pods) can reach the Spark driver.
If the Spark driver cannot be reached, Spark executors fail after throwing an exception
java.net.UnknownHostException. For example, if the Spark driver runs on a nodegold0at IP address 10.1.90.9,mr3.k8s.host.aliasescan be set as follows.$ vi kubernetes/spark/conf/mr3-site.xml <property> <name>mr3.k8s.host.aliases</name> <value>gold0=10.1.90.9</value> </property> - For accessing HDFS, it should include a mapping for the HDFS NameNode.
- In order to exploit location hints provided by HDFS when running a Spark driver inside Kubernetes, it should include mappings for HDFS DataNodes. This is because location hints provided by HDFS can be host names that are not resolved to IP addresses inside Kubernetes. (See Performance Tuning for Kubernetes for the same problem when running Hive on MR3 on Kubernetes.) If a Spark driver runs outside Kubernetes, such mappings are unnecessary as long as the Spark driver can resolve location hints provided by HDFS.
Configuring ContainerWorker Pods to create shuffle handler processes
By default, Spark on MR3 sets spark.shuffle.service.enabled to true in spark-defaults.conf
along with mr3.use.daemon.shufflehandler set to 0 in mr3-site.xml.
Every ContainerWorker Pod creates a separate process for running shuffle handlers
which is regarded as external shuffle service by Spark on MR3.
The user can find the command for executing the process in kubernetes/spark/spark/run-worker.sh.
if [ "$runShuffleHandlerProcess" = "true" ]; then
export SPARK_CONF_DIR=$BASE_DIR/conf
SPARK_SHUFFLE_CLASS=org.apache.spark.deploy.ExternalShuffleService
$JAVA -cp "$BASE_DIR/spark/jars/*" -Dspark.local.dir=/tmp -Dscala.usejavacp=true -Xmx1g $SPARK_SHUFFLE_CLASS &
The default setting is recommended because shuffle handler processes continue to serve shuffle requests even after ContainerWorkers are recycled.
If spark.shuffle.service.enabled is set to false
along with mr3.use.daemon.shufflehandler set to a number larger than zero (e.g., 1),
Spark on MR3 uses built-in shuffle handlers included in Spark executors.
In this case,
when a ContainerWorker is recycled, a new Spark executor is created
and the output produced by the previous Spark executor (inside the same ContainerWorker) is all lost.
Creating a PersistentVolume (Optional)
There is a case in which the user should create a PersistentVolume before running a Spark driver.
- MR3 enables DAG recovery by setting the configuration key
mr3.dag.recovery.enabledto true inkubernetes/spark/conf/mr3-site.xml. By default,mr3.dag.recovery.enabledis set to false and DAG recovery is disabled in MR3. As a result, if a DAGAppMaster Pod crashes, all running DAGs are lost and not recovered by a new DAGAppMaster Pod. Normally, however, this is not a practical problem because the Spark driver automatically retries those stages corresponding to lost DAGs.
In order to create a PersistentVolume,
first update kubernetes/spark-yaml/workdir-pv.yaml and kubernetes/spark-yaml/workdir-pvc.yaml.
workdir-pv.yaml creates a PersistentVolume.
The user should update it in order to use a desired type of PersistentVolume.
workdir-pvc.yaml creates a PersistentVolumeClaim which references the PersistentVolume created by workdir-pv.yaml.
The user should specify the size of the storage:
storage: 10Gi
Then set CREATE_PERSISTENT_VOLUME to true in kubernetes/spark/env.sh so as to read workdir-pv.yaml and workdir-pvc.yaml.
$ vi kubernetes/spark/env.sh
CREATE_PERSISTENT_VOLUME=true
If the Spark driver runs inside Kubernetes, update kubernetes/spark-yaml/spark-run.yaml to mount the PersistentVolume.
Then the Spark driver can access resources under the mount point /opt/mr3-run/work-dir.
$ vi kubernetes/spark-yaml/spark-run.yaml
- name: work-dir-volume
mountPath: /opt/mr3-run/work-dir
- name: work-dir-volume
persistentVolumeClaim:
claimName: workdir-pvc
For mounting the PersistentVolume inside a DAGAppMaster Pod (e.g., when DAG recovery is enabled), update kubernetes/spark/env.sh.
$ vi kubernetes/spark/env.sh
WORK_DIR_PERSISTENT_VOLUME_CLAIM=workdir-pvc
WORK_DIR_PERSISTENT_VOLUME_CLAIM_MOUNT_DIR=/opt/mr3-run/work-dir
Creating PersistentVolumes is also necessary if the user wants to keep the log files of Spark drivers running inside Kubernetes. By default, Spark drivers running inside Kubernetes store their log files under the following directories:
/opt/mr3-run/spark/spark-shell-result/opt/mr3-run/spark/spark-submit-result
Since these directories are container-local directories, the log files are not accessible after Spark driver Pods terminate. In order to keep the log files, the user can mount PersistentVolumes under these directories.
Creating Kubernetes resources
Before running Spark on MR3, the user should create various Kubernetes resources by executing the script kubernetes/run-spark-setup.sh.
The script reads some of the YAML files in the directory kubernetes/spark-yaml.
For running a Spark driver outside Kubernetes,
the user should update mr3-service.yaml appropriately which creates a Service for exposing MR3 DAGAppMaster.
(If the Spark driver runs inside the Kubernetes cluster, updating mr3-service.yaml is unnecessary.)
The user should specify a public IP address with a valid host name and a port number for DAGAppMaster
so that Spark drivers can connect to it from the outside of the Kubernetes cluster.
$ vi kubernetes/spark-yaml/mr3-service.yaml
ports:
- protocol: TCP
port: 9862
targetPort: 8080
externalIPs:
- 10.1.90.10
Executing the script generates two environment variables CLIENT_TO_AM_TOKEN_KEY and MR3_APPLICATION_ID_TIMESTAMP.
$ kubernetes/run-spark-setup.sh
...
export CLIENT_TO_AM_TOKEN_KEY=e07c35ca-1a2c-4d97-9037-9fb84de5f7c4
export MR3_APPLICATION_ID_TIMESTAMP=29526
configmap/client-am-config created
service/mr3 created
The user should set these environment variables on every node where Spark on MR3 is to be launched so that all Spark drivers can share the same DAGAppMaster Pod (and consequently the same set of ContainerWorker Pods). If the environment variables are not set, each Spark driver creates its own DAGAppMaster Pod and no ContainerWorker Pods are shared.
$ export CLIENT_TO_AM_TOKEN_KEY=e07c35ca-1a2c-4d97-9037-9fb84de5f7c4
$ export MR3_APPLICATION_ID_TIMESTAMP=29526
Running Spark on MR3
Option 1. Running a Spark driver inside Kubernetes
To run a Spark driver inside Kubernetes,
edit kubernetes/spark-yaml/driver-service.yaml and kubernetes/spark-yaml/spark-run.yaml.
$ vi kubernetes/spark-yaml/driver-service.yaml
metadata:
name: spark1
spec:
selector:
sparkmr3_app: spark1
- The field
metadata/namespecifies the name of the Spark driver Pod. - The field
spec/selectorshould use the name of the Spark driver Pod.
$ vi kubernetes/spark-yaml/spark-run.yaml
metadata:
name: spark1
labels:
sparkmr3_app: spark1
spec:
hostAliases:
- ip: "10.1.90.9"
hostnames:
- "gold0"
containers:
- image: 10.1.90.9:5000/spark3:latest
env:
- name: DRIVER_NAME
value: "spark1"
- name: SPARK_DRIVER_CORES
value: '2'
- name: SPARK_DRIVER_MEMORY_MB
value: '13107'
resources:
requests:
cpu: 2
memory: 16Gi
limits:
cpu: 2
memory: 16Gi
volumeMounts:
- name: spark-hostpath-1
mountPath: /data1/k8s
volumes:
- name: spark-hostpath-1
hostPath:
path: /data1/k8s
type: Directory
- The field
metadata/namespecifies the name of the Spark driver Pod. - The field
metadata/labelsshould use the name of the Spark driver Pod. - The field
spec/template/spec/hostAliasesspecifies mappings for host names. - The field
spec/containers/imagespecifies the full name of the Docker image including a tag. - The environment variable
DRIVER_NAMEshould be set to the name of the Spark driver Pod. - The environment variables
SPARK_DRIVER_CORESandSPARK_DRIVER_MEMORY_MBspecify the arguments for the configuration keysspark.driver.coresandspark.driver.memory(in MB) for the Spark driver, respectively. - The
spec/containers/resources/requestsandspec/containers/resources/limitsfields specify the resources to to be allocated to the Spark driver Pod. As a particular case, if DAGAppMaster runs in LocalProcess mode (see the case 2 in Running MR3Client inside/outside Kubernetes), the resource for the Spark driver Pod should be large enough to accommodate both the Spark driver and DAGAppMaster. - The fields
spec/containers/volumeMountsandspec/volumesspecify the list of directories to which hostPath volumes point for the Spark driver. The list of directories should match the value forspark.local.dirinspark-defaults.conf.
Then the user can use it to create a Spark driver Pod as follows:
$ kubectl create -f kubernetes/spark-yaml/driver-service.yaml
$ kubectl create -f kubernetes/spark-yaml/spark-run.yaml
The environment variables CLIENT_TO_AM_TOKEN_KEY and MR3_APPLICATION_ID_TIMESTAMP are set automatically
so that a common DAGAppMaster can be shared by Spark drivers.
After creating a Spark driver Pod,
the user can execute run-spark-shell.sh or run-spark-submit.sh inside the Pod
to start a Spark driver.
The scripts accept the following options.
--driver-java-options,--jars,--driver-class-path,--conf: These options with arguments are passed on tobin/spark-submitandbin/spark-shell.
For example, the user can execute Spark shell as follows:
$ kubectl exec -it -n sparkmr3 spark1 /bin/bash
spark@spark1:/opt/mr3-run/spark$ ./run-spark-shell.sh
Option 2. Running a Spark driver outside Kubernetes
Before running a Spark driver outside Kubernetes,
create a directory as specified by the configuration key mr3.am.staging-dir in mr3-site.xml.
$ mkdir -p /opt/mr3-run/work-dir
Spark on MR3 creates a new subdirectory (e.g., .mr3/application_16555_0000) which remains empty.
Then set environment variables SPARK_DRIVER_CORES and SPARK_DRIVER_MEMORY_MB to specify the arguments for the configuration keys spark.driver.cores and spark.driver.memory (in MB) for the Spark driver, respectively, e.g.:
$ export SPARK_DRIVER_CORES=2
$ export SPARK_DRIVER_MEMORY_MB=13107
Finally the user can execute kubernetes/spark/spark/run-spark-submit.sh or kubernetes/spark/spark/run-spark-shell.sh,
which in turn executes the script bin/spark-submit or bin/spark-shell under the directory of the Spark installation.
The scripts accept the following options.
--driver-java-options,--jars,--driver-class-path,--conf: These options with arguments are passed on tobin/spark-submitandbin/spark-shell.
The user should use a --conf spark.driver.host option to specify
the host name or address where the Spark driver runs.
In order to run multiple Spark drivers on the same node,
the user should also specify a unique port for each individual driver
with a --conf spark.driver.port option.
The user may provide additional options for Spark, e.g:
$ kubernetes/spark/spark/run-spark-submit.sh --conf spark.driver.host=gold0 --class com.datamonad.mr3.spark.tpcds.RunManyQueries /home/spark/mr3-run/spark/benchmarks/smb2/tpcds/target/scala-2.12/spark_mr3_tpcds_2.12-0.1.jar hdfs://gold0:8020/tmp/tpcds-generate/1000 /home/spark/mr3-run/hive/benchmarks/sparksql/ 19,42,52,55 1 false
$ kubernetes/spark/spark/run-spark-shell.sh --conf spark.driver.host=gold0
The first Spark driver creates a DAGAppMaster Pod.
If the environment variables CLIENT_TO_AM_TOKEN_KEY and MR3_APPLICATION_ID_TIMESTAMP are properly set,
all subsequent Spark drivers connect to the existing DAGAppMaster Pod without creating new ones.
Terminating Spark on MR3
Terminating a Spark driver does not delete the DAGAppMaster Pod.
Instead all the Kubernetes resources remain intact and continue to serve subsequent Spark drivers.
In order to delete the Kubernetes resources, the user should manually execute kubectl.
$ kubectl -n sparkmr3 delete deployments --all; kubectl -n sparkmr3 delete pod --all; kubectl -n sparkmr3 delete configmap --all; kubectl -n sparkmr3 delete svc --all; kubectl -n sparkmr3 delete secret --all; kubectl -n sparkmr3 delete serviceaccount spark-service-account; kubectl -n sparkmr3 delete role --all; kubectl -n sparkmr3 delete rolebinding --all; kubectl delete clusterrole node-reader; kubectl delete clusterrolebinding spark-clusterrole-binding; kubectl -n sparkmr3 delete persistentvolumeclaims workdir-pvc; kubectl delete persistentvolumes workdir-pv
