Hive on MR3 on Kubernetes suffers from a performance penalty due to the use of Docker containers. This performance penalty is the price we pay for all the benefits of using Kubernetes such as easier deployment and higher security. Below we describe how to minimize the performance penalty when running Hive on MR3 on Kubernetes.
This page is work in progress and may be expanded in the future.
Page cache for Docker containers
The most significant change when migrating from Hadoop to Kubernetes is that page cache is now local to each Docker container. The user should consider this property of Docker containers before choosing 1) the memory limit of ContainerWorker Pods and 2) the size of Java heap of ContainerWorker processes.
In the case of Hadoop,
all ContainerWorkers running on the same node share page cache which is managed by the operating system.
Hence the size of Java heap
can be close to the size of the memory allocated to a ContainerWorker process,
as long as page cache can grow sufficiently large.
For example,
it may be okay to set the configuration key hive.mr3.container.max.java.heap.fraction
even to 0.9f in hive-site.xml.
This is no longer the case when ContainerWorkers run as Pods on Kubernetes.
The operating system maintains page cache for each ContainerWorker Pod,
but by consuming the memory allocated to the ContainerWorker Pod itself.
Since separate ContainerWorker Pods do not read common files very often,
we can think of each ContainerWorker Pod as managing its own page cache.
Hence, depending on the characteristics of the workload,
the configuration key hive.mr3.container.max.java.heap.fraction should be adjusted to
a sufficiently small value, like 0.7f or even 0.6f,
to guarantee sufficiently large page cache for each ContainerWorker Pod.
Otherwise the performance of Hive on MR3 can sometimes be noticeably slow because of thrashing.

Location hints when using HDFS
In a Kubernetes cluster collocated with HDFS, Hive on MR3 can take advantage of location hints provided by HDFS. Specifically, when scheduling a mapper that is about to read an HDFS block, MR3 can check the location hint provided by HDFS and try to assign it to a ContainerWorker Pod running on the same physical node where the HDFS block is stored.
In order to exploit this feature,
the user should set the configuration key mr3.k8s.host.aliases in mr3-site.xml
to mappings from host names to IP addresses.
As an example, suppose that
an HDFS DataNode and a ContainerWorker Pod (with logical IP address 10.1.1.1 assigned by Kubernetes) are running
on a node foo with physical IP address 192.168.100.1.

For every HDFS block stored on the node foo,
its location hint includes host name foo, but does not include IP address 192.168.100.1.
On the other hand,
the ContainerWorker Pod can retrieve its physical IP address 192.168.100.1 from Kubernetes,
but is not aware of the corresponding host name foo.
We can reconcile the mismatch
by setting mr3.k8s.host.aliases to foo=192.168.100.1.
Internally MR3 running on Kubernetes tries to convert all location hints to IP addresses. If IP addresses cannot be found, location hints are discarded because ContainerWorker Pods are aware only of their logical and physical IP addresses. In order to make the best use of location hints, MR3Client (such as HiveServer2 and Spark driver) running outside Kubernetes should provide IP addresses as location hints because host names that are resolved to IP addresses outside Kubernetes may not be resolved inside Kubernetes.
Running shuffle handlers in a separate process
Depending on resources allocated to each mapper, reducer, and ContainerWorker, it may help to run shuffle handlers in a separate process inside the ContainerWorker Pod. For more details, see MR3 Shuffle Handler and Using the MR3 Shuffle Handler.
Deleting Vertex-local directories
By default, ContainerWorkers delete intermediate data after the completion of the query. The default behavior is acceptable when running Hive on MR3 on Hadoop, but it may affect the stability of Hive on MR3 on Kubernetes. For example, a ContainerWorker Pod may not have enough space for local directories where intermediate data is written, especially when running a query that produces a huge amount of intermediate data. Since intermediate data produced by early stage Vertexes may linger on page cache without being accessed again, the default behavior may negatively affect the utilization of page cache as well.
In order to deal with the potential problem of the default behavior, MR3 allows the user to delete intermediate data produced by a Vertex as soon as all its consumer Vertexes are completed. For example, Map 1 and Map2 in the following diagram can delete their intermediate data right after Reduce 1 gets completed.
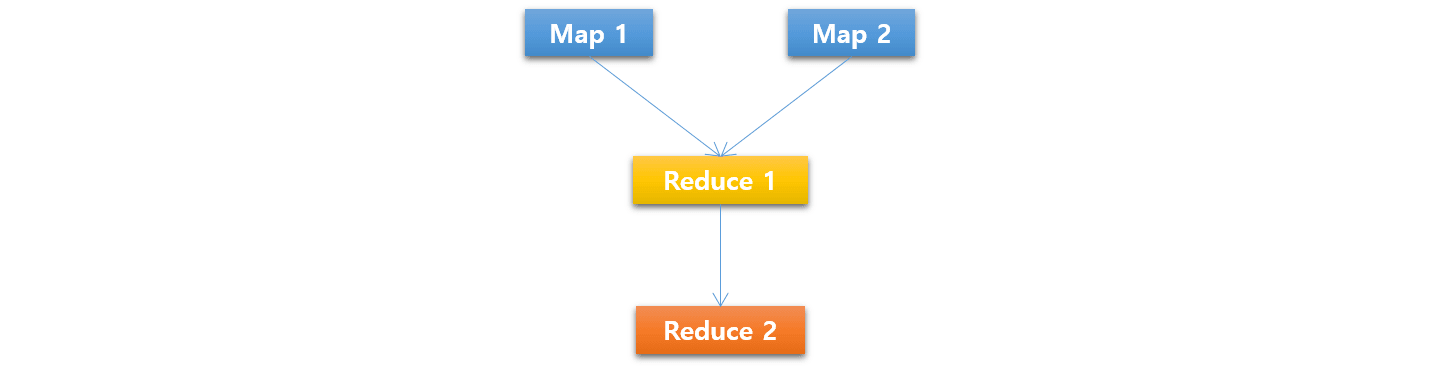
For running Hive on MR3,
the user can set the configuration key hive.mr3.delete.vertex.local.directory to true,
either in Beeline before submitting a query
or in hive-site.xml before starting HiveServer2.
Then HiveServer2 internally sets the MR3 configuration key mr3.am.notify.destination.vertex.complete to true
and ContainerWorkers are notified of the completion of all consumer Vertexes for each individual Vertex.
Note that if the configuration key hive.mr3.delete.vertex.local.directory is set to true,
fetch-failures may give rise to a cascade of Vertex reruns all the way up to leaf Vertexs.
In the above diagram,
suppose that after Reduce 1 finishes all its Tasks,
a TaskAttempt of Reduce 2 reports a fetch-failure.
Then a Vertex rerun occurs and Reduce 1 creates a new TaskAttempt.
The new TaskAttempt, however, finds that no input data is available
because both Map 1 and Map 2 have already deleted their intermediate data.
As a consequence, Map 1 and Map 2 re-executes all their Tasks,
which in turn cause Vertex reruns in their ancestors.
Hence the user should set the configuration key hive.mr3.delete.vertex.local.directory to true with caution
only if 1) a ContainerWorker Pod does not have enough space for local directories,
or 2) fetch-failures rarely occur.
