After getting up and running Hive on MR3, the user may wish to improve its performance by changing configuration parameters. Because of the sheer number of configuration parameters in Hive, Tez, and MR3, however, it is out of the question to write a definitive guide to finding an optimal set of configuration parameters. As a consequence, the user should usually embark on a long journey to find a set of configuration parameters suitable for his or her workloads. Still we can identify a relatively small number of configuration parameters that usually have a major and immediate impact on the performance for typical workloads. Below we describe such configuration parameters in the order of importance.
This page is work in progress and may be expanded in the future.
For running Hive on MR3 on Hadoop, use the option--tpcds(not--cluster) which uses configuration files under the directoryconf/tpcdswhich have been tuned with the TPC-DS benchmark. In particular, the option--tpcdsuses the MR3 Shuffle Handler in Hive on MR3 instead of an external shuffle service.
Resources for Metastore, HiveServer2, and DAGAppMaster
To serve concurrent requests from multiple users, the three main components should be allocated enough resources. In particular, failing to allocate enough resources to any of these components can slow down all queries without reporting errors. In production environments with up to 20 concurrent connections, the user can use the following settings as a baseline, and adjust later as necessary.
$ vi kubernetes/env.sh
HIVE_SERVER2_HEAPSIZE=16384
HIVE_METASTORE_HEAPSIZE=16384
$ vi kubernetes/yaml/hive.yaml
resources:
requests:
cpu: 8
memory: 16Gi
limits:
cpu: 8
memory: 16Gi
$ vi kubernetes/yaml/metastore.yaml
resources:
requests:
cpu: 8
memory: 16Gi
limits:
cpu: 8
memory: 16Gi
$ vi kubernetes/conf/mr3-site.xml
<property>
<name>mr3.am.resource.memory.mb</name>
<value>32768</value>
</property>
<property>
<name>mr3.am.resource.cpu.cores</name>
<value>16</value>
</property>
If HiveServer2 becomes a performance bottleneck, the user can create multiple instances of HiveServer2, e.g.:
$ vi kubernetes/yaml/hive.yaml
spec:
replicas: 2
Resources for mappers (Map Tasks), reducers (Reduce Tasks), and ContainerWorkers
The following configuration keys in hive-site.xml specify resources (in terms of memory in MB and number of cores)
to be allocated to each mapper, reducer, and ContainerWorker:
hive.mr3.map.task.memory.mbandhive.mr3.map.task.vcores: memory in MB and number of cores to be allocated to each mapperhive.mr3.reduce.task.memory.mbandhive.mr3.reduce.task.vcores: memory in MB and number of cores to be allocated to each mapperhive.mr3.all-in-one.containergroup.memory.mbandhive.mr3.all-in-one.containergroup.vcores(for all-in-one ContainerGroup scheme): memory in MB and number of cores to be allocated to each ContainerWorker under all-in-one schemehive.mr3.resource.vcores.divisor: divisor for the number of cores
hive.mr3.map.task.memory.mb and hive.mr3.reduce.task.memory.mb should be sufficiently large for the size of the dataset.
Otherwise queries may fail with OutOfMemoryError or MapJoinMemoryExhaustionError.
The performance of Hive on MR3 usually improves if multiple mappers and reducers can run in a ContainerWorker concurrently.
Moreover queries are less likely to fail with OutOfMemoryError or MapJoinMemoryExhaustionError
because a mapper or reducer can use more memory than specified by hive.mr3.map.task.memory.mb or hive.mr3.reduce.task.memory.mb.
With too many mappers and reducers in a ContainerWorker, however, the performance may deteriorate
because of the increased overhead of memory allocation and garbage collection.
We strongly recommendhive.mr3.all-in-one.containergroup.memory.mbset to a multiple ofhive.mr3.map.task.memory.mbandhive.mr3.reduce.task.memory.mb. This is especially important ifmr3.container.task.failure.num.sleepsis set to a non-zero value and TaskAttempts often fail.
We recommend no more than 24 concurrent mappers/reducers in a single ContainerWorker. We recommend at least 1 core for each mapper/reducer.
In the following example, we allocate 4GB and 1 core to each mapper and reducer. For a ContainerWorker, we allocate 40GB and 10 cores so that 10 mappers and reducers can run concurrently.
$ vi kubernetes/conf/hive-site.xml
<property>
<name>hive.mr3.resource.vcores.divisor</name>
<value>1</value>
</property>
<property>
<name>hive.mr3.map.task.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>hive.mr3.map.task.vcores</name>
<value>1</value>
</property>
<property>
<name>hive.mr3.reduce.task.memory.mb</name>
<value>4096</value>
</property>
<property>
<name>hive.mr3.reduce.task.vcores</name>
<value>1</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.memory.mb</name>
<value>40960</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.vcores</name>
<value>10</value>
</property>
The user can configure Hive on MR3 so that
the default values for mappers and reducers can be overridden for each individual query inside Beeline connections.
First add relevant configuration keys to the list specified by the configuration key hive.security.authorization.sqlstd.confwhitelist.append
in hive-site.xml.
Note that regular expressions for the list are separated by |, not ,.
(We do not recommend to add hive.mr3.resource.vcores.divisor to the list because it implicitly affects hive.mr3.all-in-one.containergroup.vcores.)
$ vi kubernetes/conf/hive-site.xml
<property>
<name>hive.security.authorization.sqlstd.confwhitelist.append</name>
<value>hive\.querylog\.location.*|hive\.mr3\.map\.task.*|hive\.mr3\.reduce\.task.*</value>
</property>
After restarting Hive on MR3, the user can override the default values inside Beeline connections. In the following example, the first query allocates 8GB and 2 cores to each mapper and reducer whereas the second query allocates 2GB and 1 core to each mapper and reducer.
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.map.task.memory.mb=8192;
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.map.task.vcores=2;
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.reduce.task.memory.mb=8192;
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.reduce.task.vcores=2;
0: jdbc:hive2://192.168.10.1:9852/> !run /home/hive/sample1.sql
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.map.task.memory.mb=2048;
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.map.task.vcores=1;
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.reduce.task.memory.mb=2048;
0: jdbc:hive2://192.168.10.1:9852/> set hive.mr3.reduce.task.vcores=1;
0: jdbc:hive2://192.168.10.1:9852/> !run /home/hive/sample2.sql
Below we show examples of common mistakes in configuring resources.
We assume that hive.mr3.resource.vcores.divisor is set to 1.
1. Memory not fully utilized
hive.mr3.map.task.memory.mb= 1024,hive.mr3.map.task.vcores= 1hive.mr3.reduce.task.memory.mb= 1024,hive.mr3.reduce.task.vcores= 1hive.mr3.all-in-one.containergroup.memory.mb= 8192,hive.mr3.all-in-one.containergroup.vcores= 4
A ContainerWorker (with 4 cores) can accommodate 4 mappers and reducers (each requesting 1 core). Since every mapper or reducer requests only 1024MB, a ContainerWorker never uses the remaining 8192 - 4 * 1024 = 4096MB of memory. As a result, the average memory usage reported by DAGAppMaster never exceeds 50%.
2020-07-19T10:07:28,159 INFO [All-In-One] TaskScheduler: All-In-One average memory usage = 50.0% (4096MB / 8192MB)
2. Cores not fully utilized
hive.mr3.map.task.memory.mb= 1024,hive.mr3.map.task.vcores= 1hive.mr3.reduce.task.memory.mb= 1024,hive.mr3.reduce.task.vcores= 1hive.mr3.all-in-one.containergroup.memory.mb= 4096,hive.mr3.all-in-one.containergroup.vcores= 8
A ContainerWorker (with 4096MB) can accommodate 4 mappers and reducers (each requesting 1024MB). Since every mapper or reducer requests 1 core, 8 - 4 * 1 = 4 cores are never used.
3. Memory and cores not fully utilized
hive.mr3.map.task.memory.mb= 2048,hive.mr3.map.task.vcores= 2hive.mr3.reduce.task.memory.mb= 2048,hive.mr3.reduce.task.vcores= 2hive.mr3.all-in-one.containergroup.memory.mb= 9216,hive.mr3.all-in-one.containergroup.vcores= 9
After taking 4 mappers and reducers, a ContainerWorker does not use the remaining resources (1024MB of memory and 1 core).
4. Resources for ContainerWorkers too large
The resources to be assigned to each ContainerWorker should not exceed the maximum resources allowed by the underlying resource manager (which is Yarn in the case of Hadoop). The maximum resources are usually smaller than the physical resources available on a worker node. For example, a worker node with 16GB of physical memory and 4 physical cores may allow up to 14GB of memory and 3 cores for ContainerWorkers only.
In addition, if a ContainerWorker starts with LLAP I/O enabled, the user should take into consideration the memory allocated for LLAP I/O as well
(hive.mr3.llap.headroom.mb and hive.llap.io.memory.size).
For more details, see LLAP I/O.
Memory settings for Hive and Tez
The following configuration keys specify the threshold for triggering Map Join in Hive and the size of buffers in Tez.
hive.auto.convert.join.noconditionaltask.sizeinhive-site.xml. Arguably this is the most important configuration parameter for performance tuning, especially for running complex queries (like TPC-DS query 24). Unlike Apache Hive which internally applies an additional formula to adjust the value specified inhive-site.xml, Hive on MR3 uses the value with no adjustment. Hence the user is advised to choose a value much larger than recommended for Apache Hive.tez.runtime.io.sort.mbandtez.runtime.unordered.output.buffer.size-mbintez-site.xml
The following example shows sample values for these configuration keys.
$ vi kubernetes/conf/hive-site.xml
<property>
<name>hive.auto.convert.join.noconditionaltask.size</name>
<value>4000000000</value>
</property>
$ vi kubernetes/conf/tez-site.xml
<property>
<name>tez.runtime.io.sort.mb</name>
<value>1040</value>
</property>
<property>
<name>tez.runtime.unordered.output.buffer.size-mb</name>
<value>307</value>
</property>
The default values specified in hive-site.xml can be overridden for each individual query inside Beeline connections, as shown below.
0: jdbc:hive2://192.168.10.1:9852/> set hive.auto.convert.join.noconditionaltask.size=2000000000;
0: jdbc:hive2://192.168.10.1:9852/> set tez.runtime.io.sort.mb=2000;
0: jdbc:hive2://192.168.10.1:9852/> set tez.runtime.unordered.output.buffer.size-mb=600;
0: jdbc:hive2://192.168.10.1:9852/> !run /home/hive/sample.sql
Depending on the Java version and the type of the garbage collector in use,
setting runtime.io.sort to a large value may result in OutOfMemory:
Caused by: java.lang.OutOfMemoryError: Java heap space
...
org.apache.tez.runtime.library.common.sort.impl.PipelinedSorter.allocateSpace(PipelinedSorter.java:270)
In such a case, the user can try a smaller value for tez.runtime.io.sort.mb, or
set tez.runtime.pipelined.sorter.lazy-allocate.memory to true
(if it currently set to false), as in:
<property>
<name>tez.runtime.pipelined.sorter.lazy-allocate.memory</name>
<value>true</value>
</property>
Setting tez.runtime.pipelined.sorter.lazy-allocate.memory to true is useful for stabilizing the performance of Hive on MR3.
Configuring ShuffleServer
Hive on MR3 centralizes the management of all fetchers under a common ShuffleServer (see Managing Fetchers).
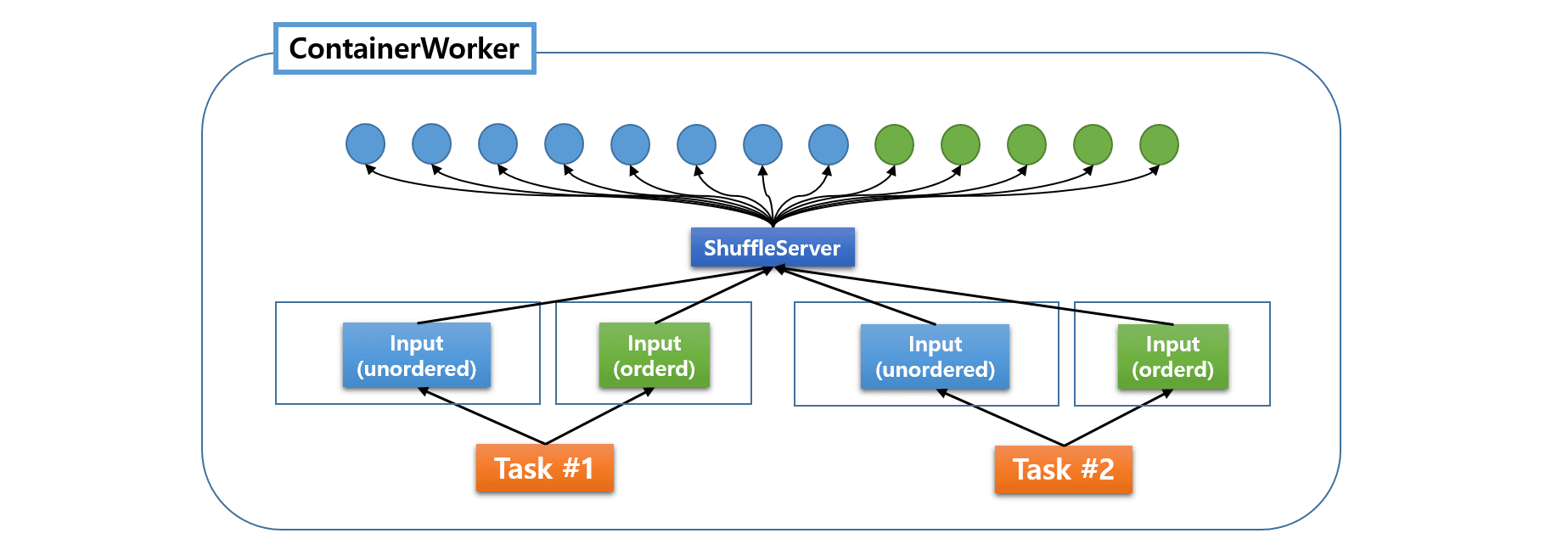
After choosing the resources for ContainerWorkers and the concurrency level,
the user should adjust two configuration keys in tez-site.xml:
tez.runtime.shuffle.parallel.copiesspecifies the maximum number of concurrent fetchers that an individual LogicalInput can request.tez.runtime.shuffle.total.parallel.copiesspecifies the total number of fetchers inside a ContainerWorker.
The user can start by setting as follows:
tez.runtime.shuffle.parallel.copiesto 10tez.runtime.shuffle.total.parallel.copiesto 20 * the total number of cores assigned to each ContainerWorker
Configuring shuffle handlers
The performance of Hive on MR3 is heavily affected by the configuration for shuffle handlers. See Using the MR3 Shuffle Handler in Hive on MR3 to use MR3 shuffle handlers.
To allow a ContainerWorker to run multiple MR3 shuffle handlers,
set the configuration key hive.mr3.use.daemon.shufflehandler in hive-site.xml to the number of shuffle handlers in each ContainerWorker.
By default (with the configuration key tez.shuffle.max.threads set to zero in tez-site.xml),
each shuffle handler creates twice as many threads as the number of cores.
The user may choose to limit the number of threads in each shuffle handler
by adjusting the value for tez.shuffle.max.threads.
For example,
with hive.mr3.use.daemon.shufflehandler set to 10
and tez.shuffle.max.threads set to 20,
a ContainerWorker creates a total of 10 x 20 = 200 threads for shuffle handlers.
The user can initially set hive.mr3.use.daemon.shufflehandler
to the number of concurrent tasks in a ContainerWorker
(with tez.shuffle.max.threads set to 20 in tez-site.xml)
and later adjust its value as necessary.
Preventing fetch delays
To prevent fetch delays,
the user should set the kernel parameter net.core.somaxconn to a sufficiently large value on every node in the cluster.
The user should also check the configuration for network interfaces on worker nodes.
If fetch delays still occur,
the user can try two features of MR3:
multiple shuffle handlers in a ContainerWorker and speculative execution.
To see if fetch delays occur,
disable the query results cache by setting
the configuration key hive.query.results.cache.enabled to false
and run a single query many times.
If the execution time is not stable and fluctuates quite a lot,
fetch delays are probably the culprit.
To enable speculative execution,
set the configuration key hive.mr3.am.task.concurrent.run.threshold.percent in hive-site.xml to the percentage of completed Tasks
before starting to watch TaskAttempts for speculative execution.
The user should also set the configuration key hive.mr3.am.task.max.failed.attempts to the maximum number of TaskAttempts for the same Task.
In the following example, a ContainerWorker runs 10 shuffle handlers each of which creates 20 threads, waits until 95 percent of Tasks complete before starting to watch TaskAttempts, and create up to 3 TaskAttempts for the same Task.
$ vi kubernetes/conf/hive-site.xml
<property>
<name>hive.mr3.use.daemon.shufflehandler</name>
<value>10</value>
</property>
<property>
<name>hive.mr3.am.task.concurrent.run.threshold.percent</name>
<value>95</value>
</property>
<property>
<name>hive.mr3.am.task.max.failed.attempts</name>
<value>3</value>
</property>
$ vi kubernetes/conf/tez-site.xml
<property>
<name>tez.shuffle.max.threads</name>
<value>20</value>
</property>
Running too many shuffle handlers or creating too many threads in each shuffle handler in a ContainerWorker with small resources can have an adverse effect on the performance.
The user can start performance tuning by creating a shuffle handler per core and setting tez.shuffle.max.threads to a small value (e.g., 20), which works well in practice.
Compressing intermediate data
Compressing intermediate data usually results in better performance,
and the user can compress intermediate data by setting the following two configuration keys in tez-site.xml.
tez.runtime.compressshould be set to true.tez.runtime.compress.codecshould be set to the codec for compressing intermediate data.
By default, tez.runtime.compress.codec is set to org.apache.hadoop.io.compress.SnappyCodec on Kubernetes and in standalone mode
(where the Snappy library is included in the distribution),
but to org.apache.hadoop.io.compress.GzipCodec on Hadoop
because it may be that the Snappy library is not installed on worker nodes.
We recommend the user to set it to org.apache.hadoop.io.compress.SnappyCodec on Hadoop
after installing the Snappy library,
or to org.apache.hadoop.io.compress.ZStandardCodec for using Zstandard compression.
Local disks
ContainerWorkers write intermediate data on local disks, so using fast storage for local disks (such as NVMe SSDs) always improves the performance, especially on shuffle-heavy queries. Using multiple local disks is also preferable to using just a single local disk because Hive on MR3 rotates local disks when creating files for storing intermediate data.
Auto parallelism
To fully enable auto parallelism,
the user should set
hive.tez.auto.reducer.parallelism to true in hive-site.xml
and
tez.shuffle-vertex-manager.enable.auto-parallel to true in tez-site.xml.
Enabling auto parallelism may cause individual queries to run slightly slower (because smaller resources are allocated),
but usually improves the throughput for concurrent queries, especially when the cluster is under heavy load.
Disabling auto parallelism usually reduces the response time of sequential queries. In order to disable auto parallelism, settez.shuffle-vertex-manager.auto-parallel.min.num.tasksintez-site.xmlto a value larger thanhive.exec.reducers.maxinhive-site.xml.
If tez.shuffle-vertex-manager.enable.auto-parallel is set to true,
the following configuration keys decide when to trigger auto parallelism and how to redistribute Tasks.
(The first two configuration keys are ignored for Vertexes with incoming edges of type SIMPLE_EDGE.)
tez.shuffle-vertex-manager.auto-parallel.min.num.taskstez.shuffle-vertex-manager.auto-parallel.max.reduction.percentagetez.shuffle-vertex-manager.use-stats-auto-parallelismtez.shuffle.vertex.manager.auto.parallelism.min.percent
The interpretation of the following example is:
- Vertexes with at least 40 Tasks are considered for auto parallelism.
- The number of Tasks can be reduced by up to 100 - 10 = 90 percent, thereby leaving 10 percent of Tasks. For example, a Vertex of 100 Tasks in the beginning may end up with 10 Tasks when auto parallelism is used.
- Vertexes analyze input statistics when applying auto parallelism.
- An input size of zero is normalized to 20 while the maximum input size is mapped to 100.
$ vi kubernetes/conf/tez-site.xml
<property>
<name>tez.shuffle-vertex-manager.enable.auto-parallel</name>
<value>true</value>
</property>
<property>
<name>tez.shuffle-vertex-manager.auto-parallel.min.num.tasks</name>
<value>40</value>
</property>
<property>
<name>tez.shuffle-vertex-manager.auto-parallel.max.reduction.percentage</name>
<value>10</value>
</property>
<property>
<name>tez.shuffle-vertex-manager.use-stats-auto-parallelism</name>
<value>true</value>
</property>
<property>
<name>tez.shuffle.vertex.manager.auto.parallelism.min.percent</name>
<value>20</value>
</property>
The aggressive use of auto parallelism increases the chance of fetch delays
if a single reducer is assigned too much data to fetch from upstream mappers.
In such a case,
the user can either disable auto parallelism completely
or use auto parallelism less aggressively,
e.g., by setting tez.shuffle-vertex-manager.auto-parallel.max.reduction.percentage to 50.
Using free memory to store shuffle input
Hive on MR3 attempts to utilize memory to store shuffle data transmitted from mappers to reducers. The following log of HiveServer2 shows that during the execution of a query, 689,693,191 bytes of shuffle data are stored in memory, with no data being written to local disks. (63,312,923 bytes of data are read directly from local disks because mappers and reducers are collocated.)
2023-12-15T06:59:16,028 INFO [HiveServer2-Background-Pool: Thread-84] mr3.MR3Task: SHUFFLE_BYTES_TO_MEM: 689693191
2023-12-15T06:59:16,028 INFO [HiveServer2-Background-Pool: Thread-84] mr3.MR3Task: SHUFFLE_BYTES_TO_DISK: 0
2023-12-15T06:59:16,028 INFO [HiveServer2-Background-Pool: Thread-84] mr3.MR3Task: SHUFFLE_BYTES_DISK_DIRECT: 63312923
Depending on the amount of shuffle data and the size of memory allocated to individual Tasks, Hive on MR3 may write shuffle data to local disks. In the following example, 10,475,065,599 bytes of shuffle data are written to local disks.
2023-12-15T07:09:57,472 INFO [HiveServer2-Background-Pool: Thread-99] mr3.MR3Task: SHUFFLE_BYTES_TO_MEM: 142177894794
2023-12-15T07:09:57,472 INFO [HiveServer2-Background-Pool: Thread-99] mr3.MR3Task: SHUFFLE_BYTES_TO_DISK: 10475065599
2023-12-15T07:09:57,472 INFO [HiveServer2-Background-Pool: Thread-99] mr3.MR3Task: SHUFFLE_BYTES_DISK_DIRECT: 13894557846
If a ContainerWorker runs multiple Tasks concurrently,
a Task may find free memory in the Java heap
even after exhausting the entire memory allocated to itself.
The configuration key tez.runtime.use.free.memory.fetched.input controls whether or not
to use such free memory to store shuffle data.
Setting it to true can reduce the execution time of a query significantly if:
- Multiple Tasks can run concurrently in a ContainerWorker (e.g., 12 Tasks in a single ContainerWorker).
- The query produces more shuffle data than can be accommodated in memory.
- Local disks use slow storage (such as HDDs).
hive.tez.llap.min.reducer.per.executor in hive-site.xml
When auto parallelism is enabled,
Hive on MR3 uses the configuration key hive.tez.llap.min.reducer.per.executor to decide the baseline for the number of reducers for each Reduce Vertex.
For example, if the entire set of ContainerWorkers can run 100 reducers concurrently and
hive.tez.llap.min.reducer.per.executor is set to 0.2,
the query optimizer tries to assign at most 100 * 0.2 = 20 reducers to each Reduce Vertex.
In this way, the configuration key hive.tez.llap.min.reducer.per.executor affects the running time of queries.
For typical workloads, the default value of 0.2 is acceptable, but depending on the characteristics of the cluster (e.g., number of ContainerWorkers, concurrency level, size of the dataset, resources for mappers and reducers, and so on), a different value may result in an improvement (or a degradation) in performance.
If the number of reducers is too small, the user can try a larger value for the configuration key hive.tez.llap.min.reducer.per.executor
(inside Beeline connections without having to restart HiveServer2).
Note that a larger value increases the initial number of reducers before auto parallelism kicks in,
but it does not guarantee an increase in the final number of reducers after adjustment by auto parallelism.
If the final number of reduces still does not change,
the user can reduce the resources to be allocated to each reducer
by updating hive.mr3.reduce.task.memory.mb and hive.mr3.reduce.task.vcores so that ContainerWorkers can accommodate more reduces.
Here is an example of trying to increase the final number of reducers in a Beeline session (where we set hive.mr3.reduce.task.vcores to 0 and ignore the number of cores).
hive.tez.llap.min.reducer.per.executor= 0.2,hive.mr3.reduce.task.memory.mb= 6144.
ContainerWorkers can accommodate 432 reducers. The initial number of reducers = 432 * 0.2 = 87. Auto parallelism has no effect and the final number of reducers is also 87.hive.tez.llap.min.reducer.per.executor= 1.0.
The initial number of reducers increases to 432 * 1.0 = 432. Auto parallelism decreases the number of reducers to 432 / 5 = 87, so the final number of reducers after adjustment by auto parallelism is still the same.hive.tez.llap.min.reducer.per.executor= 2.0.
The initial number of reducers increases to 432 * 2.0 = 864. The final number of reducers is still 864 / 10 = 87.hive.mr3.reduce.task.memory.mb= 4096.
The initial number of reducers increase to 1009 which is the maximum set by the configuration keyhive.exec.reducers.max. The final number of reducers is 1009 / 10 = 101.
hive.stats.fetch.bitvector
The logic of calculating column statistics in Metastore depends on
the configuration key hive.stats.fetch.bitvector in hive-site.xml.
In general,
Metastore provides more accurate column statistics when it is set to true,
albeit at slightly higher costs
due to additional queries sent to the database for Metastore.
For long-running queries that involve multiple join operators on various tables,
the value of hive.stats.fetch.bitvector can significantly impact the execution time.
In our experiment,
with a scale factor of 10TB on the TPC-DS benchmark,
the execution time of query 23 and query 24 varies as follows:
- With
hive.stats.fetch.bitvectorset to false,- the total execution time: 1418 seconds
- query 23: 274 seconds, 346 seconds
- query 24: 336 seconds, 462 seconds
- the total execution time: 1418 seconds
- With
hive.stats.fetch.bitvectorset to true- the total execution time: 805 seconds
- query 23: 199 seconds, 231 seconds
- query 24: 90 seconds, 285 seconds
- the total execution time: 805 seconds
hive.stats.fetch.bitvector is set to true by default in the MR3 distribution.
The user can set it to false if the overhead in Metastore is too high
(e.g., when the connection to the database for Metastore is very slow).
Compute column statistics
Computing column statistics is crucial for generating efficient query plans.
The user can compute column statistics by executing analyze table command
and then check the result by inspecting the property COLUMN_STATS_ACCURATE.
Note that
even when the configuration key hive.stats.column.autogather is set to true,
manually computing column statistics is recommended in order to obtain more accurate statistics.
0: jdbc:hive2://blue0:9854/> analyze table store_sales compute statistics for columns;
...
0: jdbc:hive2://blue0:9854/> describe formatted store_returns sr_customer_sk;
...
+------------------------+---------------------------------------------------+
| column_property | value |
+------------------------+---------------------------------------------------+
...
| COLUMN_STATS_ACCURATE | {\"COLUMN_STATS\":{\"sr_customer_sk\":\"true\"}} |
+------------------------+---------------------------------------------------+
Soft references in Tez
In a cluster with plenty of memory for the workload,
using soft references for ByteBuffers allocated in PipelinedSorter in Tez can make a noticeable difference.
To be specific,
setting the configuration key tez.runtime.pipelined.sorter.use.soft.reference to true in tez-site.xml
creates soft references for ByteBuffers allocated in PipelinedSorter
and allows these references to be reused across all TaskAttempts running in the same ContainerWorker,
thus relieving pressure on the garbage collector.
When the size of memory allocated to each ContainerWorker is small, however,
using soft references is less likely to improve the performance.
$ vi kubernetes/conf/tez-site.xml
<property>
<name>tez.runtime.pipelined.sorter.use.soft.reference</name>
<value>true</value>
</property>
In the case of using soft references,
the user should append a Java VM option SoftRefLRUPolicyMSPerMB (in milliseconds) for the configuration key mr3.container.launch.cmd-opts
in mr3-site.xml.
Otherwise ContainerWorkers use the default value of 1000 for SoftRefLRUPolicyMSPerMB.
In the following example, we set SoftRefLRUPolicyMSPerMB to 25 milliseconds:
$ vi kubernetes/conf/mr3-site.xml
<property>
<name>mr3.container.launch.cmd-opts</name>
<value>-XX:+AlwaysPreTouch -Xss512k -XX:+UseG1GC -XX:+ResizeTLAB -XX:+UseNUMA -XX:InitiatingHeapOccupancyPercent=40 -XX:G1ReservePercent=20 -XX:MaxGCPauseMillis=200 -XX:MetaspaceSize=1024m -server -Djava.net.preferIPv4Stack=true -XX:NewRatio=8 -XX:+UseStringDeduplication -Dlog4j.configurationFile=k8s-mr3-container-log4j2.properties -Djavax.net.ssl.trustStore=/opt/mr3-run/key/hivemr3-ssl-certificate.jks -Djavax.net.ssl.trustStoreType=jks -XX:SoftRefLRUPolicyMSPerMB=25</value>
</property>
mr3.container.task.failure.num.sleeps in mr3-site.xml
The configuration key mr3.container.task.failure.num.sleeps specifies the number of times to sleep (15 seconds each)
in a ContainerWorker thread after a TaskAttempt fails.
Setting it to 1 or higher greatly helps Hive on MR3 to avoid successive query failures due to OutOfMemoryError,
especially in a cluster with small memory for the workload.
This is because after the failure of a TaskAttempt,
a ContainerWorker tries to trigger garbage collection (by allocating an array of 1GB)
and temporarily suspends the thread running the TaskAttempt,
thus making subsequent TaskAttempts much less susceptible to OutOfMemoryError.
As an example, consider an experiment in which we submit query 14 to 18 of the TPC-DS benchmark 12 times on a dataset of 10TB. We execute a total of 6 * 12 = 72 queries because query 14 consists of two sub-queries. To each mapper and reducer, we allocate 4GB which is too small for the scale factor of the dataset.
- If the configuration key
mr3.container.task.failure.num.sleepsis set to zero, query 16 and query 18 fail many times, even with the mechanism of query re-execution of Hive 3. In the end, only 46 queries out of 72 queries succeed. - In contrast, if it is set to 2, query 16 and query 18 seldom fail. In the end, 71 queries succeed where only query 18 fails once.
Setting the configuration key mr3.container.task.failure.num.sleeps to 1 or higher has a drawback that
executing a query may take longer if some of its TaskAttempts fail.
Two common cases are 1) when the mechanism of query re-execution is triggered and 2) when the mechanism of fault tolerance is triggered.
- Query re-execution: while the second DAG is running after the failure of the first DAG, some threads in ContainerWorkers stay idle, thus delaying the completion of the query.
- Fault tolerance: if a running TaskAttempt is killed in order to avoid deadlock between Vertexes, its ContainerWorker resumes accepting new TaskAttempts only after its thread finishes sleeping.
In a cluster with small memory for the workload,
the higher stability far outweighs the occasional penalty of slower execution,
so we recommend setting mr3.container.task.failure.num.sleeps to 1 or higher.
In a cluster with plenty of memory for the workload,
setting mr3.container.task.failure.num.sleeps to 0 is usually okay.
The default value is 0.
If mr3.container.task.failure.num.sleeps is set to 1 or higher with autoscaling enabled,
the user may see DAGAppMaster creating more ContainerWorker Pods than necessary when TaskAttempts fail.
This is because after a TaskAttempt fails, the ContainerWorker does not become free immediately
and DAGAppMaster tries to reschedule another TaskAttempt by creating a new ContainerWorker Pod.
tez.runtime.shuffle.connect.timeout in tez-site.xml
The configuration key tez.runtime.shuffle.connect.timeout specifies
the maximum time (in milliseconds) for trying to connect to the shuffle service
or the built-in shuffle handler before reporting fetch-failures.
(See Fault Tolerance for a few examples.)
With the default value of 12500,
a TaskAttempt retries up to twice following the first attempt, each after waiting for 5 seconds.
If the connection fails too often
because of the contention for disk access or network congestion,
using a large value for tez.runtime.shuffle.connect.timeout may be a good decision
because it leads to more retries, thus decreasing the chance of fetch-failures.
(If the connection fails because of hardware problems,
fetch-failures are eventually reported regardless of the value for tez.runtime.shuffle.connect.timeout.)
On the other hand,
using too large a value may delay reports of fetch-failures much longer than Task/Vertex reruns take,
thus significantly increasing the execution time of the query.
Hence the user should choose an appropriate value that
triggers Task/Vertex reruns reasonably fast.
Accessing S3-compatible storage
There are a few configuration keys that heavily affect the performance
when accessing S3-compatible storage.
We recommend the user to set at least the following configuration keys
in kubernetes/conf/core-site.xml and kubernetes/conf/hive-site.xml:
$ vi kubernetes/conf/core-site.xml
<!-- S3 read and write -->
<property>
<name>fs.s3a.connection.maximum</name>
<value>2000</value>
</property>
<property>
<name>fs.s3.maxConnections</name>
<value>2000</value>
</property>
<property>
<name>fs.s3a.threads.max</name>
<value>100</value>
</property>
<property>
<name>fs.s3a.threads.core</name>
<value>100</value>
</property>
<!-- S3 write -->
<property>
<name>hive.mv.files.thread</name>
<value>15</value>
</property>
<property>
<name>fs.s3a.max.total.tasks</name>
<value>5</value>
</property>
<property>
<name>fs.s3a.blocking.executor.enabled</name>
<value>false</value>
</property>
<!-- S3 input listing -->
<property>
<name>mapreduce.input.fileinputformat.list-status.num-threads</name>
<value>50</value>
</property>
$ vi kubernetes/conf/hive-site.xml
<!-- S3 input listing -->
<property>
<name>hive.exec.input.listing.max.threads</name>
<value>50</value>
</property>
<!-- MSCK (Metastore Check) -->
<property>
<name>hive.metastore.fshandler.threads</name>
<value>30</value>
</property>
<property>
<name>hive.msck.repair.batch.size</name>
<value>3000</value>
</property>
<!-- dynamic partition query -->
<property>
<name>hive.load.dynamic.partitions.thread</name>
<value>25</value>
</property>
If a Map Vertex gets stuck in the state of Initializing for a long time
while generating InputSplits in DAGAppMaster,
the user can try the following approaches:
- Increase values for
mapreduce.input.fileinputformat.list-status.num-threadsandhive.exec.input.listing.max.threads(either inside Beeline connections or by restarting HiveServer2). Here we assume that DAGAppMaster is allocated enough CPU resources. - Set
hive.exec.orc.split.strategytoBIand adjust the value forfs.s3a.block.size. - Merge input files if there are many small input files.
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 llap Initializing -1 0 0 -1 0 0
Reducer 2 llap New 4 0 0 4 0 0
Reducer 3 llap New 1 0 0 1 0 0
Tuning garbage collection
In most cases, it is not worth the time and effort
(and the user should not try)
to rigorously tune those parameters governing garbage collection
because Java VM is already good at choosing suitable values based on the number of processors and the heap size.
In certain environments (e.g., CDH 5.15), however,
Java VM makes a wrong assumption about the number of processors
(e.g., because of the cgroup enablement with Java 1.8 update 191 or later),
and as a consequence, the performance noticeably deteriorates as the memory allocated to an individual ContainerWorker increases.
In such a case,
the user should check if Runtime.getRuntime().availableProcessors() returns a correct value,
and manually configure the garbage collector if necessary.
As an example,
consider the output of the G1 garbage collector (with -XX:+UseG1GC)
on a machine with 36 processors (with hyper-threading enabled):
2019-10-15T20:17:50.278+0900: [GC pause (G1 Evacuation Pause) (young), 0.0216146 secs]
[Parallel Time: 4.7 ms, GC Workers: 2]
The garbage collector creates only two worker threads because Runtime.getRuntime().availableProcessors() returns 2.
Usually the garbage collector creates at least half as many worker threads as the number of processors.
For example, the following output shows that 18 worker threads are running on a machine with 24 processors.
2019-12-17T17:51:12.129+0900: [GC pause (G1 Evacuation Pause) (young), 0.0135165 secs]
[Parallel Time: 10.4 ms, GC Workers: 18]
If the garbage collector is not working normally, the user should provide additional parameters to Java VM
(with configuration keys mr3.am.launch.cmd-opts and mr3.container.launch.cmd-opts in mr3-site.xml).
An example of specifying the number of worker threads for the G1 garbage collector is:
-XX:ParallelGCThreads=8 -XX:ConcGCThreads=2
If Runtime.getRuntime().availableProcessors() returns a wrong value,
the user may also have to set the configuration key tez.shuffle.max.threads manually
because with the default value of 0, it is set to double the number returned by Runtime.getRuntime().availableProcessors().
For more details, see Using the MR3 Shuffle Handler.
