In Apache Hive (and the initial version of MR3), fetchers are managed by individual LogicalInputs. A Task can have multiple LogicalInputs, each of which manages its own group of fetchers with an instance of ShuffleServer:
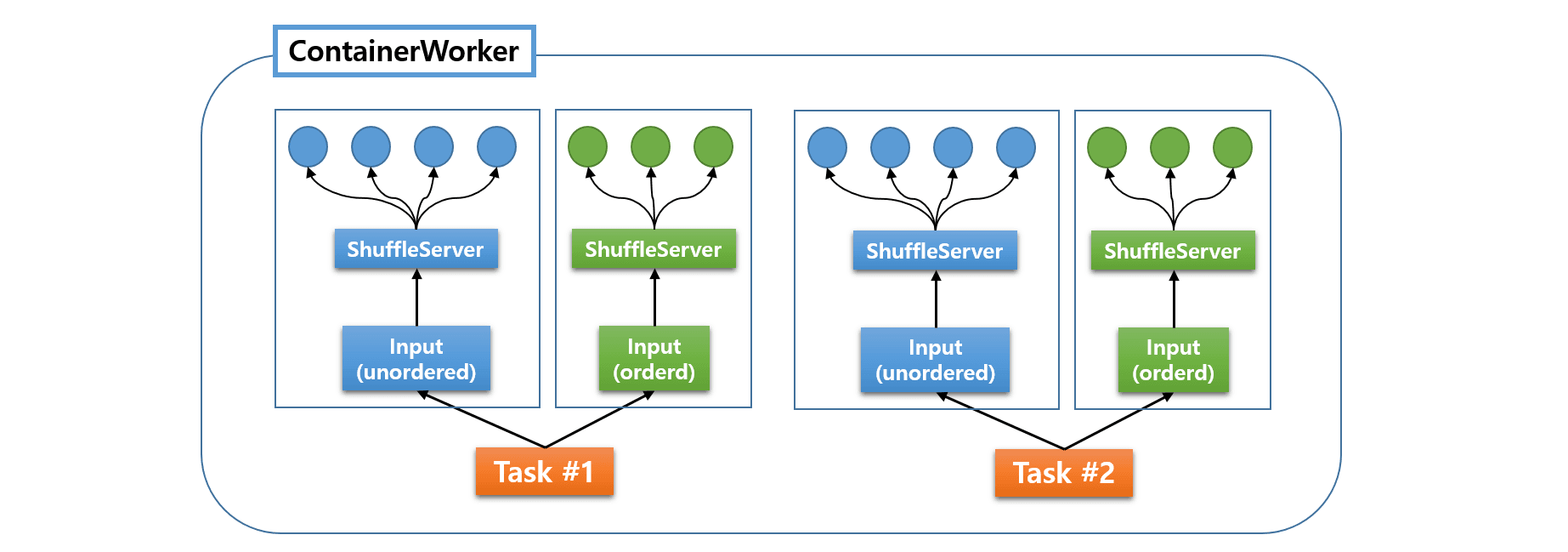
In the diagram shown above, blue circles represent fetchers for unordered data, and green circles represent fetchers for ordered data. Since we can set a limit only on the total of number of fetchers per LogicalInput, a ContainerWorker may create too many fetchers accidentally. As a result, the performance of fetchers is not always unstable and the chance of fetch delays also increases.
In contrast, the runtime system of MR3 uses an advanced architecture which centralizes the management of all fetchers under a common ShuffleServer.
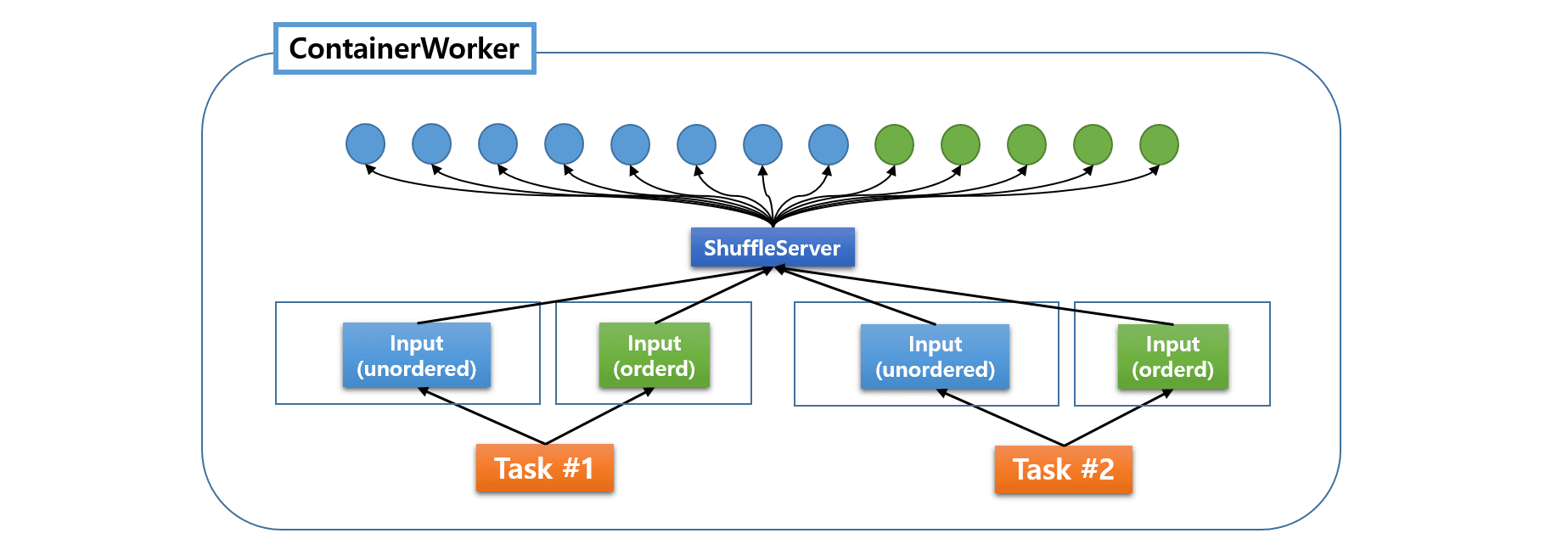
All fetchers, for both ordered and unordered data, are created and managed by a single ShuffleServer. The ShuffleServer is implemented as a DaemonTask and is unique in each ContainerWorker. Now we can specify not only the maximum number of concurrent fetchers that an individual LogicalInput can request, but also the total number of concurrent fetchers running inside a ContainerWorker. As a result, the performance of fetchers is generally more stable and the (non-negligible) overhead of creating and destroying ShuffleServers for individual LogicalInputs is now gone.
In tez-site.xml,
the configuration key tez.runtime.shuffle.parallel.copies specifies
the maximum number of concurrent fetchers that an individual LogicalInput can request,
and the configuration key tez.runtime.shuffle.total.parallel.copies specifies
the total number of fetchers running inside a ContainerWorker.
