Apache Celeborn is a remote shuffle service which enables MR3 to store intermediate data generated by mappers on Celeborn worker nodes, rather than on local disks. Reducers directly request Celeborn workers for intermediate data, thus eliminating the need for the MR3 Shuffle Handler (or the Hadoop Shuffle Handler on Hadoop).
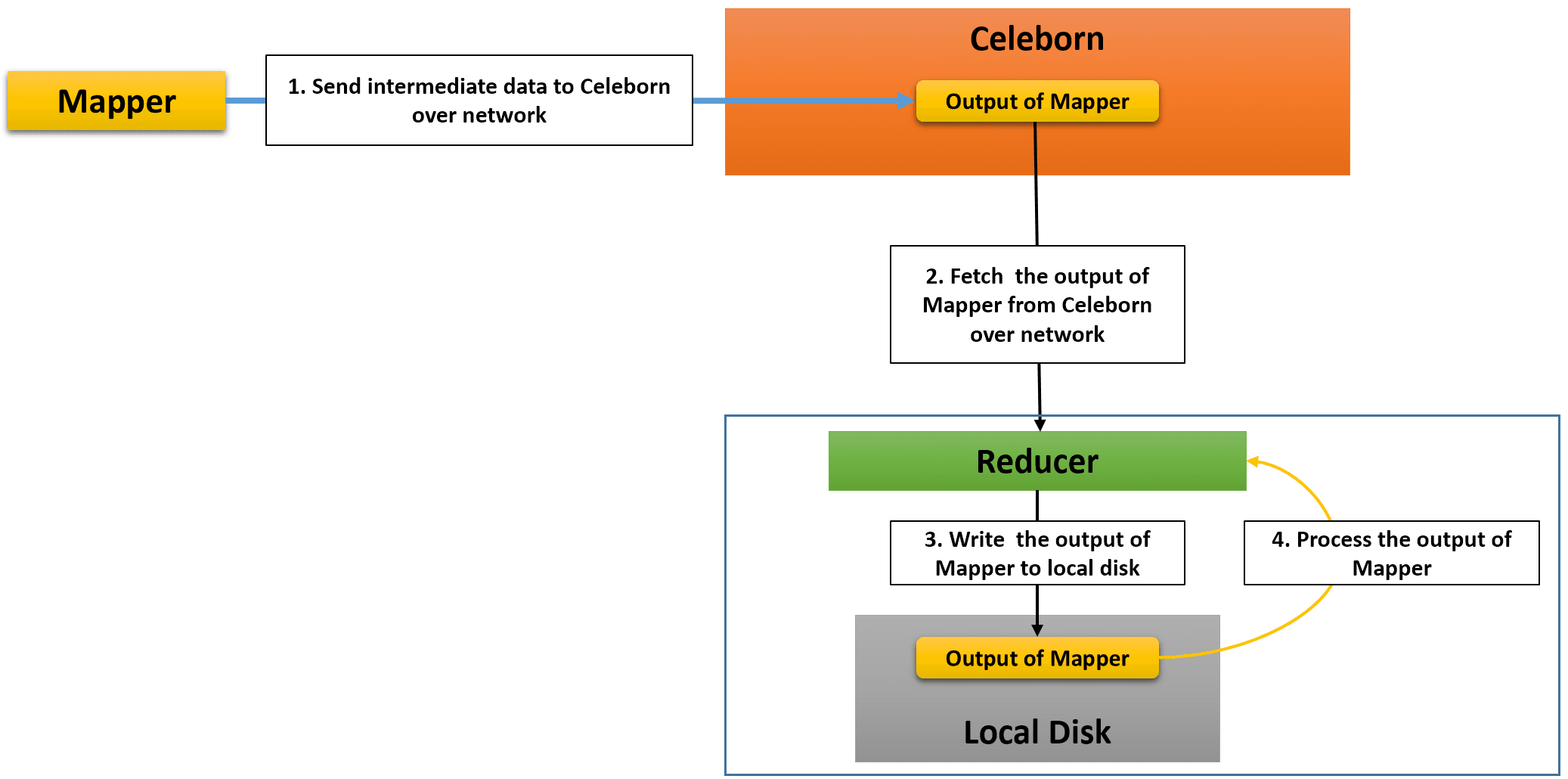
Since intermediate data is stored on Celeborn worker nodes instead of local disks, one of the key benefits of using Celeborn is that MR3 now needs only half as much space on local disks. Furthermore the use of Celeborn enables MR3 to directly process the output of mappers on the reducer side (skipping steps 3 and 4 in the above diagram), thus eliminating over 95% of writes to local disks when executing typical queries.
The lower requirement on local disk storage is particularly important when running MR3 on public clouds where 1) the total capacity of local disks attached to each node is limited and 2) attaching local disks is expensive.
Celeborn officially supports Spark and Flink. We have extended the runtime system of MR3 to use Celeborn 0.3.1 as remote shuffle service.
Configuring MR3 with Celeborn
The user can configure MR3 to use Celeborn
by setting the following configuration keys in tez-site.xml.
Internally a configuration key of the form tez.celeborn.XXX.YYY
is converted to celeborn.XXX.YYY and passed to the Celeborn client.
tez.celeborn.enabledshould be set to true.tez.celeborn.master.endpointsshould be set to Celeborn master endpoints.tez.celeborn.client.shuffle.compression.codecshould be set tononeso that intermediate data is not compressed by Celeborn. Setting it to true is okay, but unnecessary because we recommend the use of Tez for compressing intermediate data (withtez.runtime.compressset to true).
In addition,
the user should set the following configuration keys in mr3-site.xml.
-
mr3.dag.vertex.schedule.by.stageshould be set to true. Then a Vertex creates Tasks only after all source Vertexes are completed, in compliance with the execution model assumed by Celeborn. (If it is set to false for some reason, the configuration keymr3.taskattempt.queue.schemeshould be set tospark.) -
mr3.dag.route.event.after.source.vertexshould be set to true. Then a Vertex receives events only after all source Vertexes are completed. As a small optimization, events from unsuccessful attempts are automatically blocked.
Below we explain three configuration keys in tez-site.xml
for adjusting the behavior of fetchers running inside reducers
(which request Celeborn workers for intermediate data).
To illustrate the usage of these configuration keys,
we assume the following scenario.
We remark that a similar case actually occurs
when running Hive on MR3 on the TPC-DS benchmark with a scale factor of 10TB.
- A source Vertex creates 1000 mappers, each of which generates 70MB of intermediate data for a certain partition.
- Every mapper succeeds at its first attempt.
- Thus the total amount of intermediate data generated by mappers for the given partition is 1000 * 7MB = 70GB.
tez.runtime.celeborn.fetch.split.threshold
This configuration key specifies the maximum size of data
that a fetcher can receive from Celeborn workers.
Celeborn allows a single fetcher
to receive the entire intermediate data destined to a reducer.
In the above scenario, however,
such a fetcher can easily become a performance bottleneck
because a single spill file of 70GB is created by sequentially fetching from Celeborn workers.
By adjusting tez.runtime.celeborn.fetch.split.threshold,
the user can create multiple fetchers
which can concurrently fetch from Celeborn workers.
The default value is 1024 * 1024 * 1024 (1GB).
In the above scenario, the default value results in at least 70 fetchers.
tez.runtime.celeborn.shuffle.parallel.copies
This configuration key specifies the maximum number of fetchers
that can be simultaneously active in a reducer.
In the above scenario (where we use the default value for tez.runtime.celeborn.fetch.split.threshold),
setting this configuration key to 7 creates 10 waves of 7 fetchers each.
The default values is 4. With more resources allocated to each Task, increasing the value for this configuration key may result in better performance. Using too large a value, however, may affect the performance negatively.
tez.runtime.celeborn.unordered.fetch.spill.enabled
By default, this configuration key is set to true,
which means that reducers first write the output of mappers on local disks
before processing.
If it is set to false,
reducers directly process the output of mappers fetched via unordered edges
without writing to local disks.
Since typical queries generate a lot more unordered edges than ordered edges
(e.g., due to the use of order by),
the user can eliminate most of writes to local disks.
In the case of the TPC-DS benchmark,
over 95% of writes to local disks are eliminated.
Note that even when this configuration key is set to false, MR3 still needs local disks for ordered edges:
- Mappers store spill files on local disks before merging and sending to Celeborn workers.
- Reducers store the output of mappers on local disks.
If this configuration key is set to false,
the previous two configuration keys
tez.runtime.celeborn.shuffle.parallel.copies and
tez.runtime.celeborn.fetch.split.threshold become irrelevant to unordered edges.
Operating MR3 with Celeborn
Here are a few comments on operating MR3 with Celeborn.
- When using Celeborn, MR3 does not use Task/Vertex reruns
and relies on Celeborn for fault tolerance.
Thus it is safe to
set
hive.mr3.delete.vertex.local.directoryto true inhive-site.xml(ormr3.am.notify.destination.vertex.completeto true inmr3-site.xml) so that intermediate data produced by a Vertex can get deleted as soon as all its consumer Vertexes are completed. In this way, we can further lower the requirement on local disk storage. - Speculative execution works okay with Celeborn and can be effective in eliminating fetch delays.
- When running Hive on MR3,
if
OutOfMemoryErroroccurs mainly because of the use of too many fetchers, includingOutOfMemoryErrorin the value formr3.am.task.no.retry.errorsis not recommended because re-executing a query is likely to end up with the sameOutOfMemoryError. In such a case, try to use a smaller value fortez.runtime.celeborn.shuffle.parallel.copies. - Auto parallelism works okay with Celeborn, but the optimization of shuffling for auto parallelism is irrelevant to Celeborn.
When MR3 cannot use Celeborn
MR3 can use Celeborn only when DAGAppMaster and ContainerWorkers are all created as individual Java processes. Specifically MR3 cannot use Celeborn under the following conditions:
- DAGAppMaster runs in LocalThread mode.
- ContainerWorker runs in Local mode.
Even when using Celeborn,
MR3 may have to use its own Shuffle Handler or the Hadoop Shuffle Handler
if Celeborn refuses to accept shuffle requests
(e.g., when MR3 exceeds the quota allocated to it
after consuming too much disk space in Celeborn workers).
In such a case,
MR3 resorts to either the MR3 Shuffle Handler or the Hadoop Shuffle Handler,
depending on the value of the configuration key tez.am.shuffle.auxiliary-service.id
in tez-site.xml.
Assuming that such cases rarely occur,
we recommend the following settings:
- When running Hive on MR3 on Hadoop,
set
tez.am.shuffle.auxiliary-service.idtomapreduce_shuffleintez-site.xmlandhive.mr3.use.daemon.shufflehandlerto 0 inhive-site.xmlin order not to create unnecessary shuffle handlers inside ContainerWorkers. - When running Hive on MR3 on Kubernetes or in standalone mode,
set
tez.am.shuffle.auxiliary-service.idtotez_shuffleintez-site.xmlandhive.mr3.use.daemon.shufflehandlerto 1 inhive-site.xmlso as to minimize memory consumption by shuffle handlers.
Limitation
Currently MR3 relies on data replication by Celeborn for fault tolerance. We do not implement the mechanism of Task/Vertex rerun for Celeborn for two reasons.
- Celeborn does not return the identity of the mapper task whose output has been lost.
- The failure of a single Celeborn worker usually invalidates the output of every edge
(unless
celeborn.master.slot.assign.maxWorkersis set to a very small value).
As a result, when MR3 tries to recompute partial results, all the Vertexes up to the root Vertex are eventually rerun in a cascading manner, thus defeating the purpose of Task/Vertex rerun.
Until Celeborn is extended to provide the support for recomputing partial results on the execution engine side, we will rely on data replication by Celeborn for fault tolerance.
