Fault tolerance of MR3
MR3 is a fault-tolerant system which is capable of recovering from TaskAttempt failures and continuing its intended operation. There are four cases in which MR3 makes a decision on whether or not to recover from TaskAttempt failures:
- A TaskAttempt fails with a recoverable exception such as IOException.
- A TaskAttempt fails with a fatal error such as OutOfMemoryError and MapJoinMemoryExhaustionError in Hive on MR3.
- A TaskAttempt is killed.
- A TaskAttempt operates normally, but it fails to read the output of a source TaskAttempt due to fetch-failures (in which a consumer ‘fails’ to ‘fetch’ the output of a producer from a remote node).
In every case, MR3 decides either to fail the corresponding Task (and its Vertex and eventually the entire DAG), or to continue by rescheduling a new TaskAttempt.
For each Task,
MR3 keeps track of the total number of TaskAttempts that should be regarded as valid tries,
and makes sure that it never exceeds a threshold specified by the configuration key mr3.am.task.max.failed.attempts (with a default value of 3).
For example, with mr3.am.task.max.failed.attempts set to 3, a Task can try up to 3 independent TaskAttempts.
In case 1, MR3 simply reschedules a new TaskAttempt and continues.
In case 2, the behavior of MR3 depends on the values set for the configuration keys mr3.am.task.no.retry.errors and mr3.am.task.retry.on.fatal.error.
If the error is found in the list specified by mr3.am.task.no.retry.errors, MR3 fails the corresponding Task and consequently the entire DAG.
If not, MR3 checks the value set for mr3.am.task.retry.on.fatal.error.
If it is set to a default value of false, MR3 fails the corresponding Task and consequently the entire DAG.
If it is set to true, MR3 reschedules a new TaskAttempt and continues.
Continuing to execute the Task in case 2 can be useful in Hive on MR3 for completing those queries that would otherwise fail even with the mechanism of query re-execution available in Hive. That is, the user may be able to complete a query that fails even with query re-execution. This is because by retrying even on fatal errors, Hive may be able to collect more accurate statistics on input data. On the other hand, if the query succeeds with query re-execution, fast failing the Task reduces the total execution time.
In case 3, MR3 reschedules a new TaskAttempt, but does not count the previous TaskAttempt as a valid try. This is because TaskAttempts are killed either by MR3 itself (e.g., MR3 preempts running TaskAttempts in order to avoid deadlock between Vertexes), by the user (e.g., the user kills ContainerWorker processes), or by the underlying system (e.g., the OS kills ContainerWorker processes, or the node crashes). Essentially the TaskAttempt is killed not because of its own fault but because of external factors.
In case 4, MR3 reschedules a new source TaskAttempt in order to regenerate the output
while the TaskAttempt complaining about fetch-failures continues to run.
Since the Task of the previous source TaskAttempt has already completed successfully, its state usually transitions from Succeeded back to Running,
thus giving rise to a phenomenon called “Task rerun”.
If the Vertex of the previous source TaskAttempt has already completed successfully, we also observe a phenomenon called “Vertex rerun”.
Note that the new source TaskAttempt may also complain about fetch-failures,
in which case MR3 reschedules yet another wave of TaskAttempts.
Thus a single fetch-failure can trigger a cascade of Task/Vertex reruns, which commonly occurs when a node crashes.
Implementing Task/Vertex reruns
Due to the complexity in state transitions in Tasks and Vertexes when recovering from fetch-failures, Task/Vertex reruns in case 4 are the most challenging to implement faithfully. In fact, it turns out that not every execution engine commonly known to support fault tolerance fully implements the logic for recovering from fetch-failures. For example, the following issues are still pending in Spark and Tez (as of July 2019):
- SPARK-20178: https://issues.apache.org/jira/browse/SPARK-20178
- TEZ-3910: https://issues.apache.org/jira/browse/TEZ-3910
A correct implementation of Task/Vertex reruns is especially important for Kubernetes and cloud environments, in which logical nodes can spawn and retire frequently. For example, the user of public clouds may choose to run MR3 using spot instances which can be preempted at any time. If a node containing intermediate data of an active DAG retires, MR3 can complete the DAG successfully by virtue of its implementation of Task/Vertex reruns.
In the case of Hadoop, Task/Vertex reruns are much less likely to occur as physical nodes do not crash very often. In the case that ContainerWorker processes crash or get killed, we can also avoid fetch-failures by using the Hadoop shuffle service which is always ready on every node. If, however, MR3 runs with its own built-in shuffle handler, it should activate Task/vertex reruns in the event of fetch-failures.
The logic of TaskAttempts reporting fetch-failures to the DAGAppMaster is as follows.
If a TaskAttempt fails to connect to the Hadoop shuffle service or the built-in shuffle handler serving source TaskAttempts, it retries in 5 seconds
(as specified by UNIT_CONNECT_TIMEOUT in the class org.apache.tez.http.BaseHttpConnection)
while waiting up to the duration specified by the configuration key tez.runtime.shuffle.connect.timeout (in milliseconds).
Here are a few examples:
- If
tez.runtime.shuffle.connect.timeoutis set to 2500, it never retries and reports fetch-failures immediately. - If
tez.runtime.shuffle.connect.timeoutis set to 7500, it retries only once after waiting for 5 seconds. - If
tez.runtime.shuffle.connect.timeoutis set to 12500, it retries only twice, each after waiting for 5 seconds. - If
tez.runtime.shuffle.connect.timeoutis set to 17500, it retries only three times, each after waiting for 5 seconds.
If an error occurs after successfully connecting to the shuffle service or the built-in shuffle handler, the TaskAttempt reports a fetch-failure immediately. Here are a few cases of such errors:
- The node running the Hadoop shuffle service for source TaskAttempts suddenly crashes.
- The ContainerWorker process holding the output of source TaskAttempts suddenly terminates.
- The output of source TaskAttempts gets corrupted or deleted.
Example
The following example demonstrates the fault tolerance property of MR3 when it runs on a Hadoop cluster without using the Hadoop shuffle service.
At 33 seconds, we see that all Map Vertexes have succeeded:
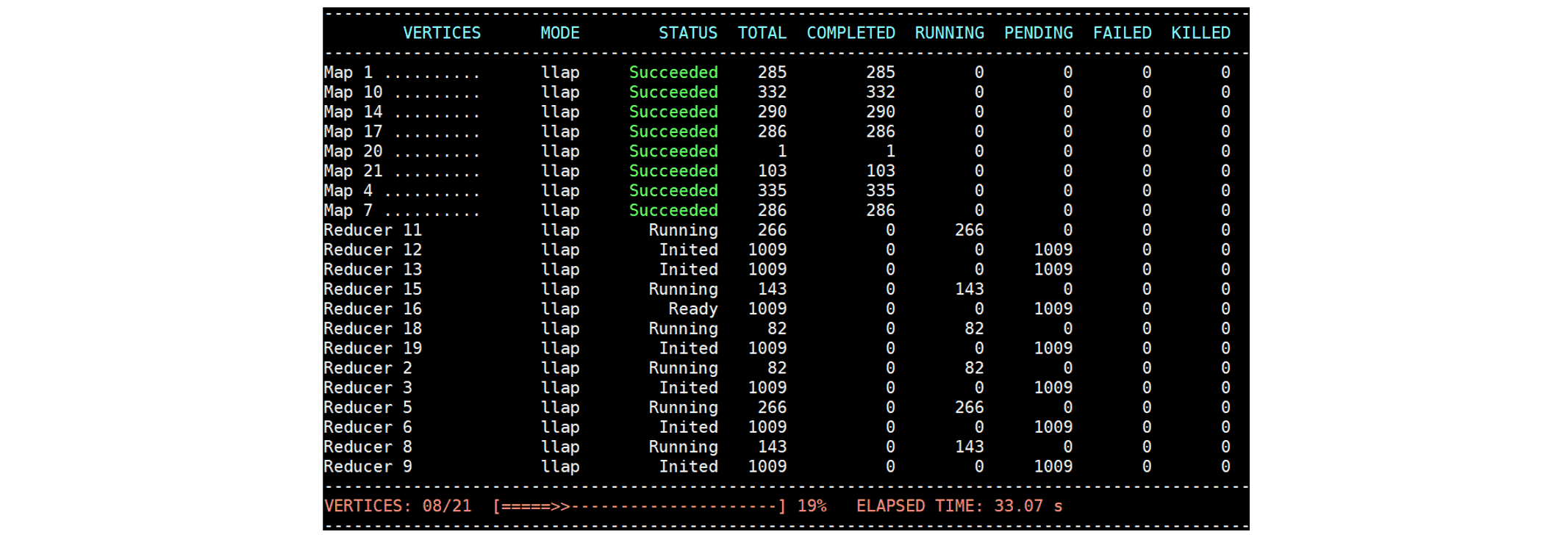 Then we kill a ContainerWorker out of a total of 10 ContainerWorkers.
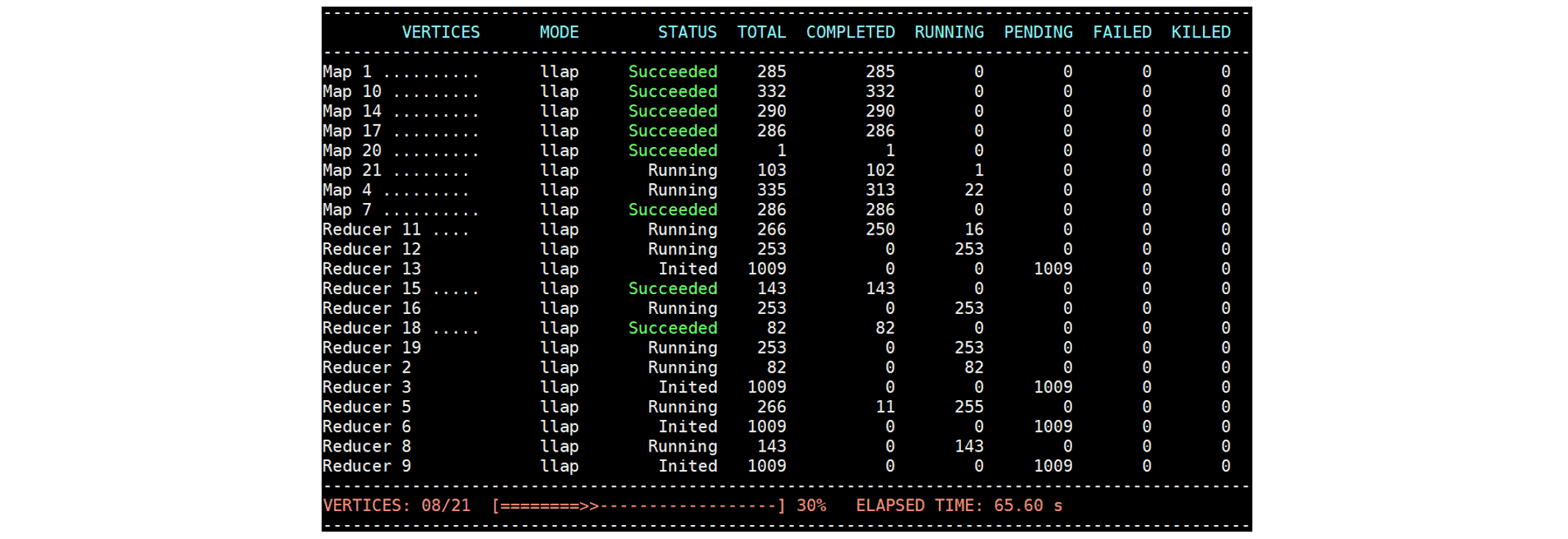
We observe that two Map Vertexes (Map 21 and Map 4) transition back to
Then we kill a ContainerWorker out of a total of 10 ContainerWorkers.
We observe that two Map Vertexes (Map 21 and Map 4) transition back to Running:
 We also observe that running TaskAttempts of Reducer 5 and Reducer 11 are killed in order to prevent deadlock:
We also observe that running TaskAttempts of Reducer 5 and Reducer 11 are killed in order to prevent deadlock:
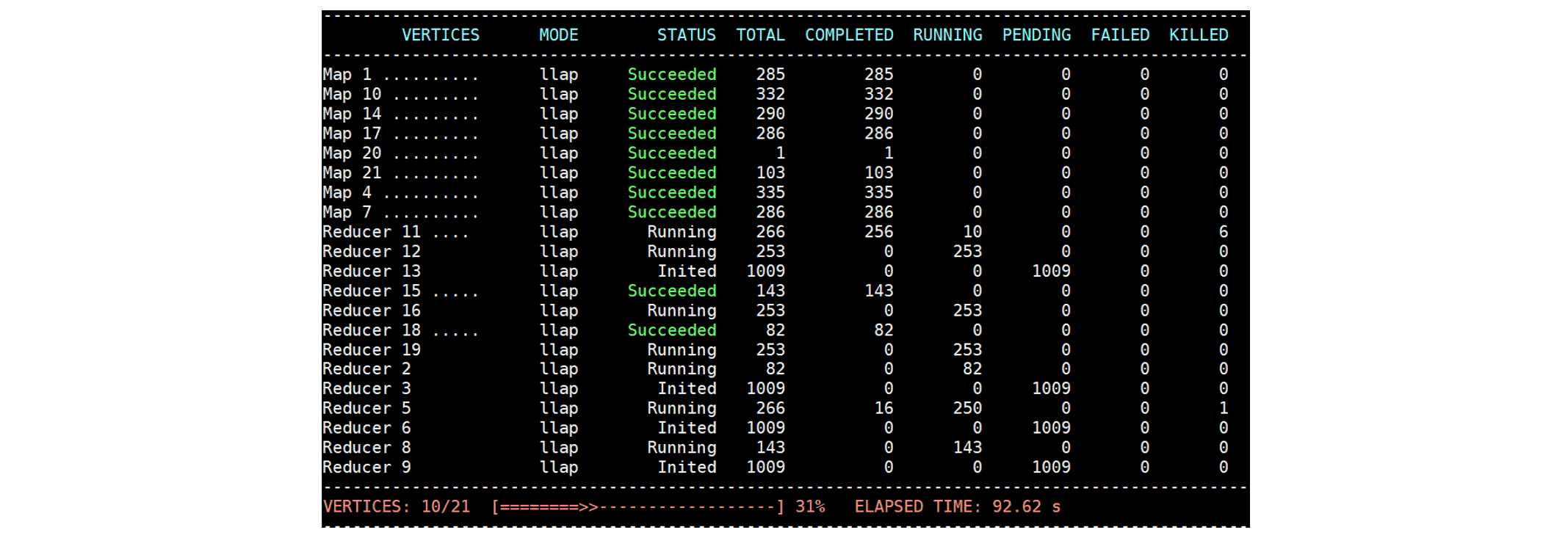 Eventually the DAG completes successfully.
Eventually the DAG completes successfully.
