Fetch delays
Fetch delays are a phenomenon in which shuffling intermediate data between ContainerWorkers gets stuck for a long time (but eventually completes) after TCP listen queues fail to process bursty connection requests. They can occur in any application program that opens TCP listen queues for data transmission, such Hadoop DataNode daemons, Hadoop shuffle servers, and MR3 shuffle handlers. In the context of MR3, fetch delays give rise to stragglers which usually delay the completion of DAGs in the order of hundreds of seconds and sometimes in the order of thousands of seconds.
The following example shows fetch delays and resultant stragglers
when running query 4 of the TPC-DS benchmark with a scale factor of 1TB in a cluster of 42 nodes (each with 96GB of memory).
In a normal case, the query completes in much less than 100 seconds,
but even at 124 seconds, four Tasks of Map 7 are still running:
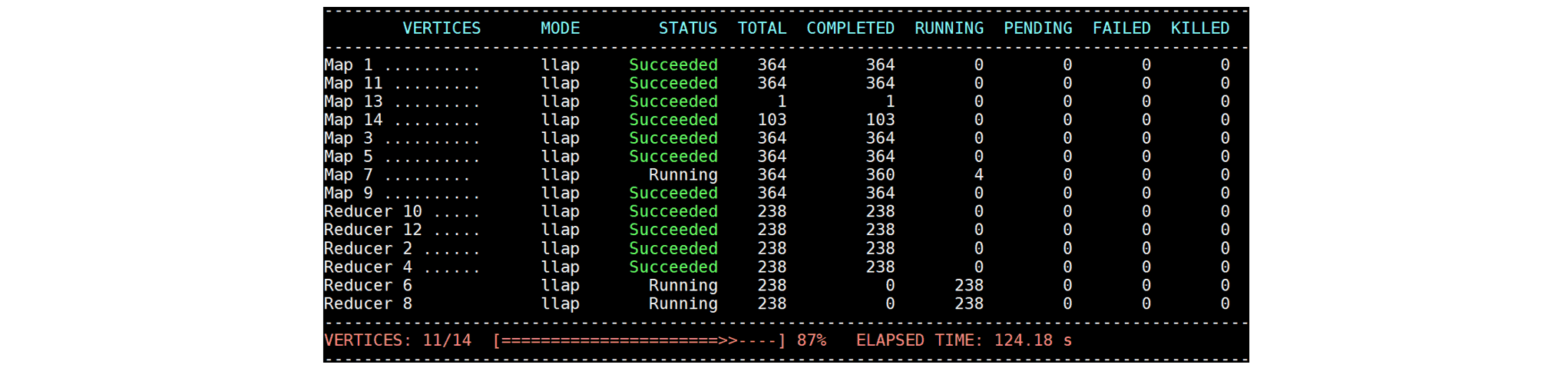 These four Tasks make no progress for the next 1400 seconds and stall the progress of the whole query:
These four Tasks make no progress for the next 1400 seconds and stall the progress of the whole query:
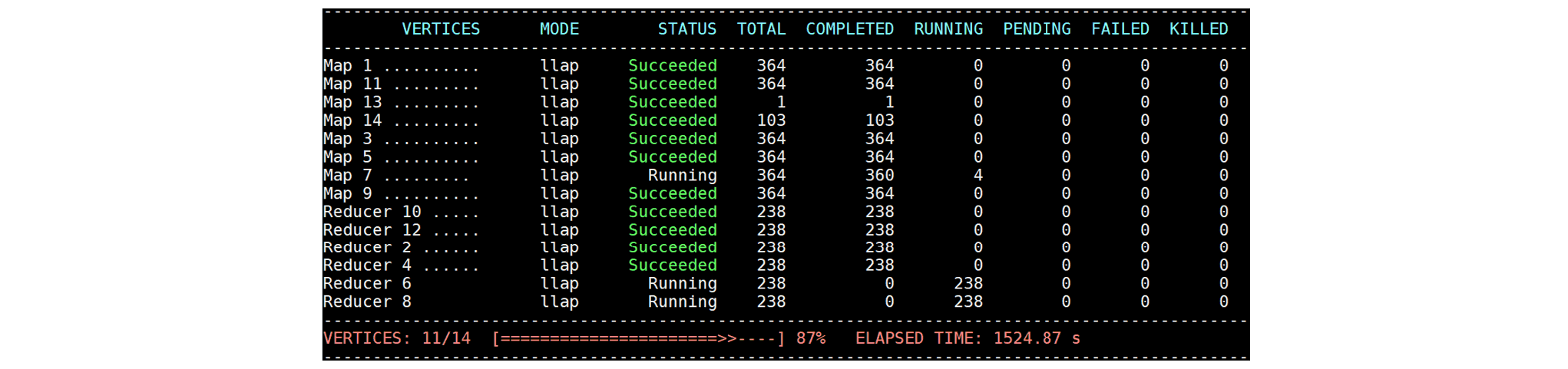 Until these stragglers resume,
every node in the cluster stays idle because data transmission from Map 13 and Map 14 is the bottleneck.
(Map 7 reads not only from HDFS but also intermediate data produced by Map 13 and Map 14.)
Eventually the query completes at 1577 seconds, but after causing the entire cluster to come to a halt for more than 1400 seconds.
Until these stragglers resume,
every node in the cluster stays idle because data transmission from Map 13 and Map 14 is the bottleneck.
(Map 7 reads not only from HDFS but also intermediate data produced by Map 13 and Map 14.)
Eventually the query completes at 1577 seconds, but after causing the entire cluster to come to a halt for more than 1400 seconds.
Ironically fetch delays occur more frequently 1) on small datasets than large datasets and 2) in large clusters than small clusters for the size of the dataset. Intuitively a large cluster can accommodate more Tasks and a small dataset allows Tasks to complete faster. As a result, many Tasks can simultaneously generate bursty connection requests to a common source of data, thus increasing the chance of fetch delays. In our experiment, for example, query 4 suffers from fetch delays very often on the dataset of 1TB, but never on the dataset of 10TB. The structure of the DAG (e.g., the result of compiling a query in Hive on MR3) also affects the chance of fetch delays. In our experiment, for example, only query 4 in the TPC-DS benchmark produces fetch delays.
Configuring kernel parameters
A common solution to reduce the chance of fetch delays is to adjust a few kernel parameters to prevent packet drops. For example, the user can adjust the following kernel parameters:
- increase the value of
net.core.somaxconn(e.g., from the default value of 128 to 16384) - optionally increase the value of
net.ipv4.tcp_max_syn_backlog(e.g., to 65536) - optionally decrease the value of
net.ipv4.tcp_fin_timeout(e.g., to 30)
Unfortunately configuring kernel parameters is only a partial solution that does not eliminate fetch delays completely. This is because if the application program is slow in processing connection requests, TCP listen queues eventually become full and fetch delays ensue. In other words, without optimizing the application program itself, we can never eliminate fetch delays by adjusting kernel parameters alone.
Configuring network interfaces
The node configuration for network interfaces also affects the chance of fetch delays. For example, frequent fetch delays due to packet loss may occur if the scatter-gather feature is enabled on network interfaces on worker nodes.
$ ethtool -k p1p1
...
scatter-gather: on
tx-scatter-gather: on
tx-scatter-gather-fraglist: off [fixed]
In such a case, the user can disable relevant features on network interfaces, e.g.:
$ ethtool -K p1p1 sg off
Eliminating fetch delays in MR3
For those cases where configuring kernel parameters and network interfaces does not help or is not feasible, we combine two features of MR3 to solve the problem of fetch delays:
- We run multiple shuffle handlers in a ContainerWorker in order to reduce the chance of fetch delays
(see Using the MR3 Shuffle Handler).
We may think of using multiple shuffle handlers as implementing a simple form of load balancing.
Note that running multiple shuffle handlers is different from running multiple worker threads in a single shuffle handler
by adjusting the configuration parameter
tez.shuffle.max.threadsintez-site.xml. - In order to mitigate the effect of stragglers when fetch delays occur, we use speculative execution (see Speculative Execution). That is, when MR3 detects a straggler, it creates another TaskAttempt with the hope that the new TaskAttempt will not suffer from fetch delays. If the new TaskAttempt is later judged to be a straggler as well, MR3 creates yet another TaskAttempt, and so on.
Below we demonstrate how MR3 eliminates fetch delays. We consecutively run query 4 of the TPC-DS benchmark a total of 100 times in the same setting described above, and report the execution time of every run. In the experiment, we use Hive 4 on MR3.
-
If we 1) deploy a single large ContainerWorker on each node, 2) create a single shuffle handler in each ContainerWorker, and 3) do not use speculative execution, fetch delays occur frequently. In this scenario, there is only one shuffle handler running on each node. The graph shows the run number in the x-axis and the execution time in seconds in the y-axis.
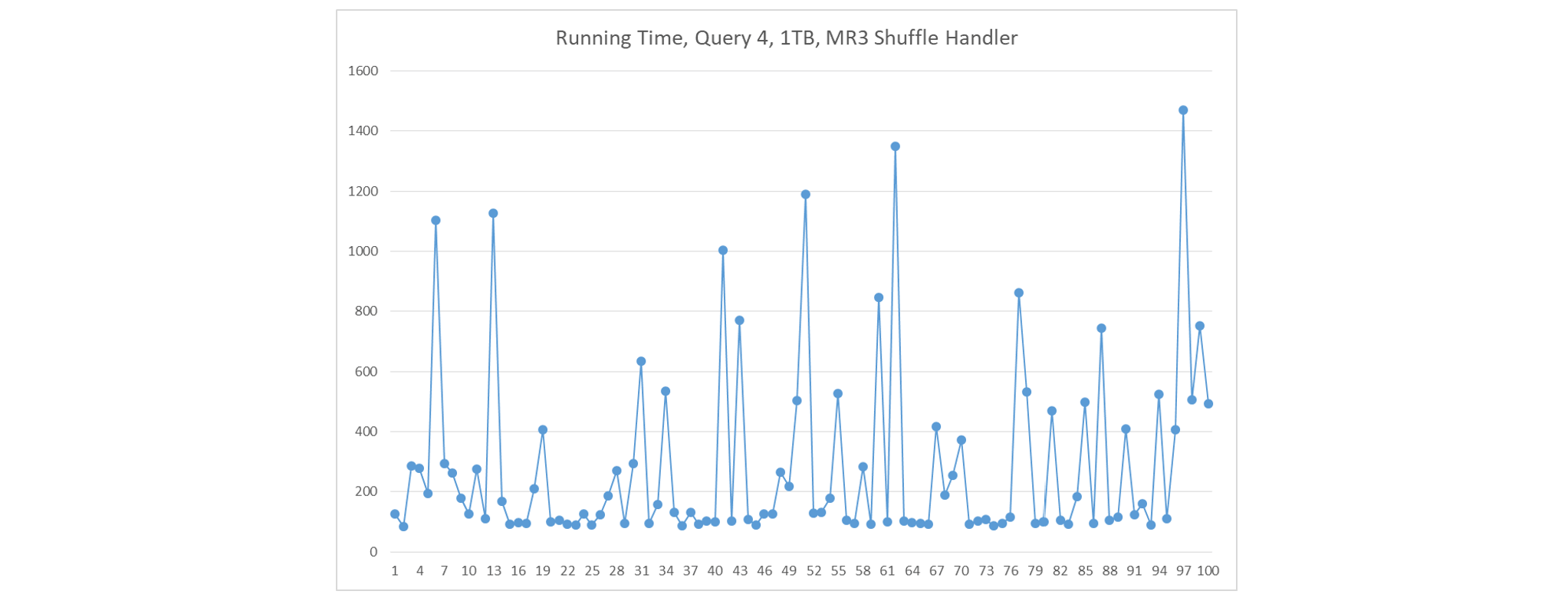
-
If we instead use Hadoop shuffle service which runs as an independent process on every node, fetch delays occur less frequently, but are still a serious problem.
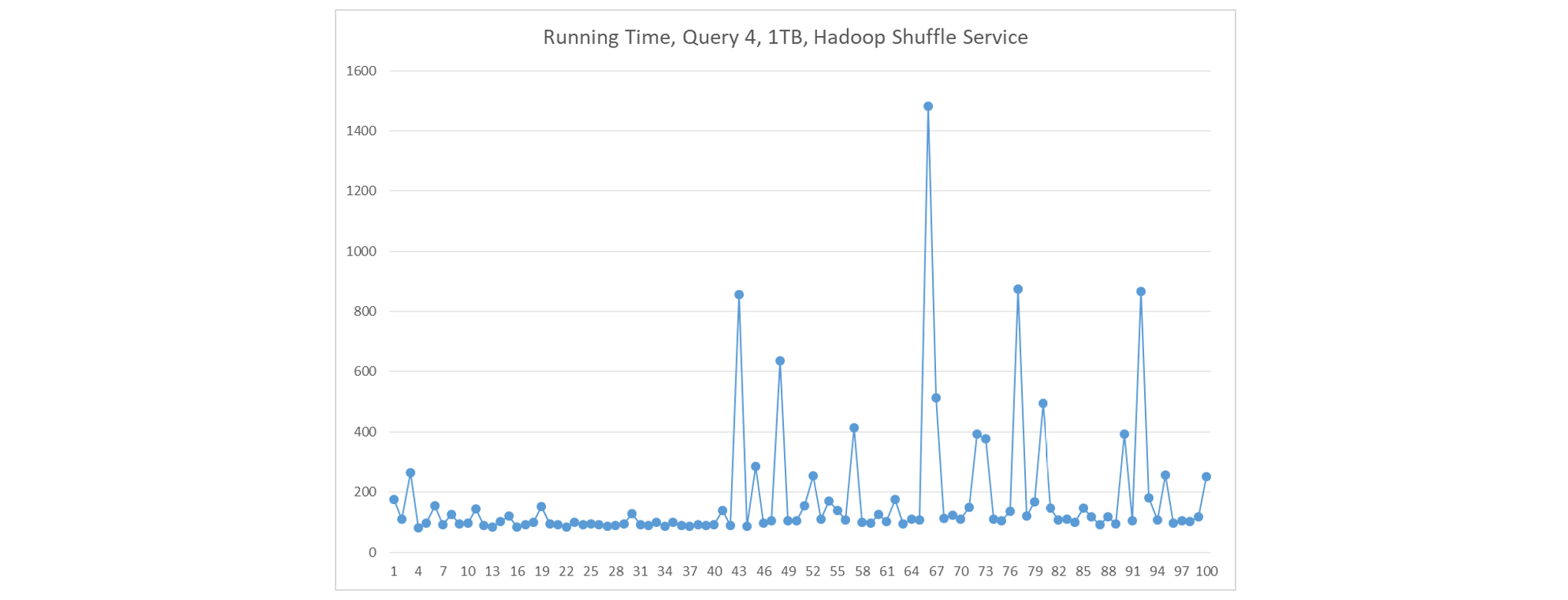
-
If we 1) deploy 5 small ContainerWorkers on each node, 2) create a single shuffle handler in each ContainerWorker, and 3) do not use speculative execution, fetch delays occur much less frequently. The result is better than in the first scenario because every node runs 5 shuffle handlers.
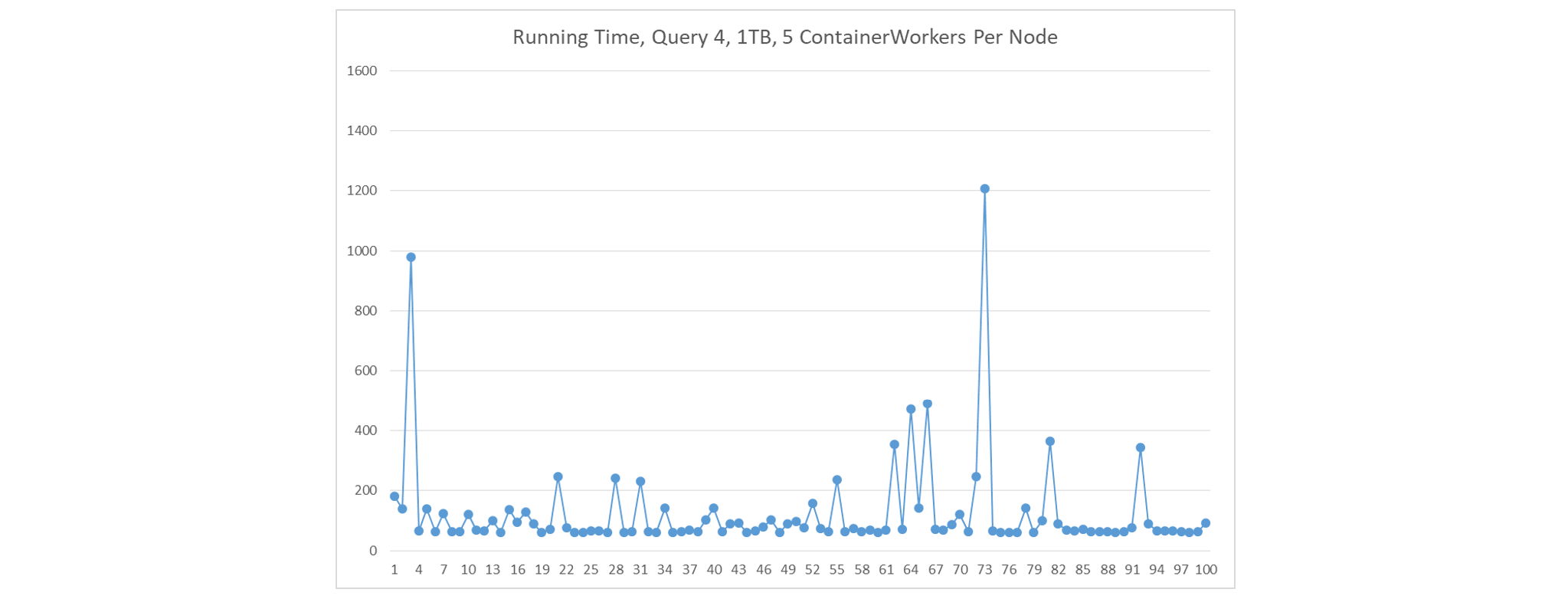
-
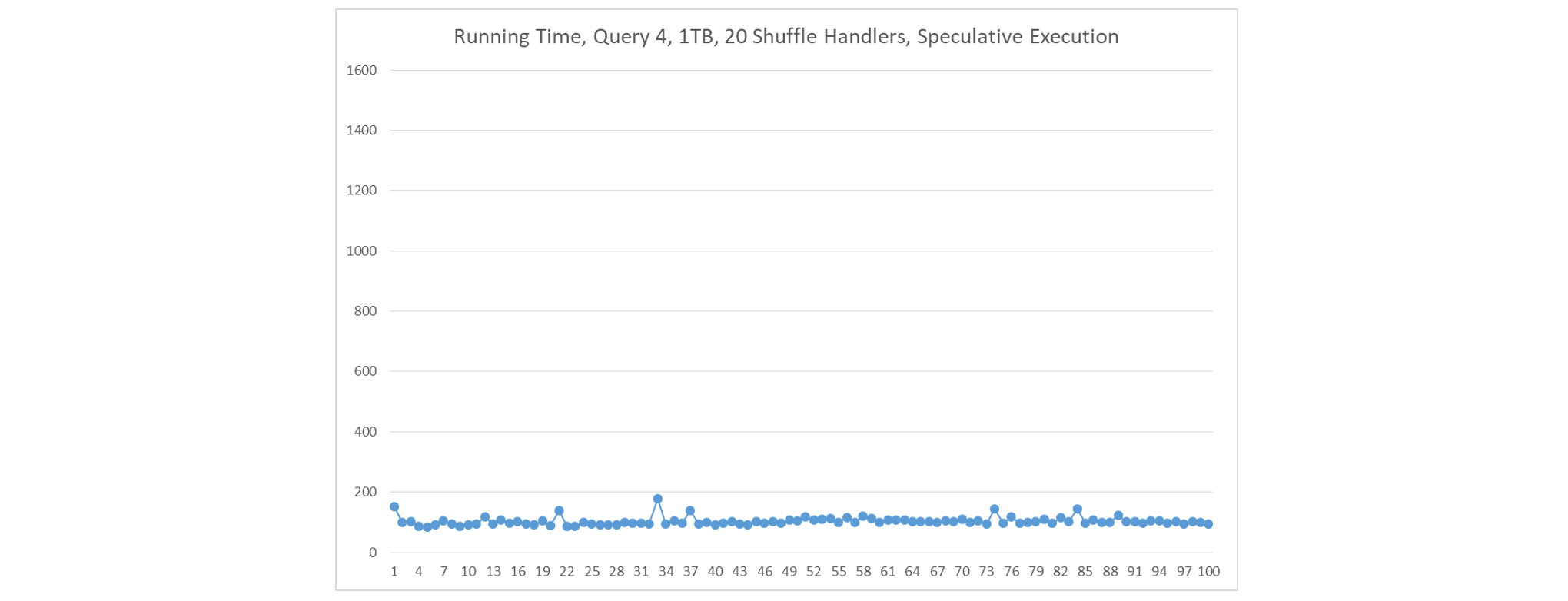
If we 1) deploy a single large ContainerWorker on each node, 2) create 10 shuffle handlers in each ContainerWorker, and 3) use speculative execution, fetch delays seldom occur. In this scenario, there are 10 shuffle handlers running on each node.
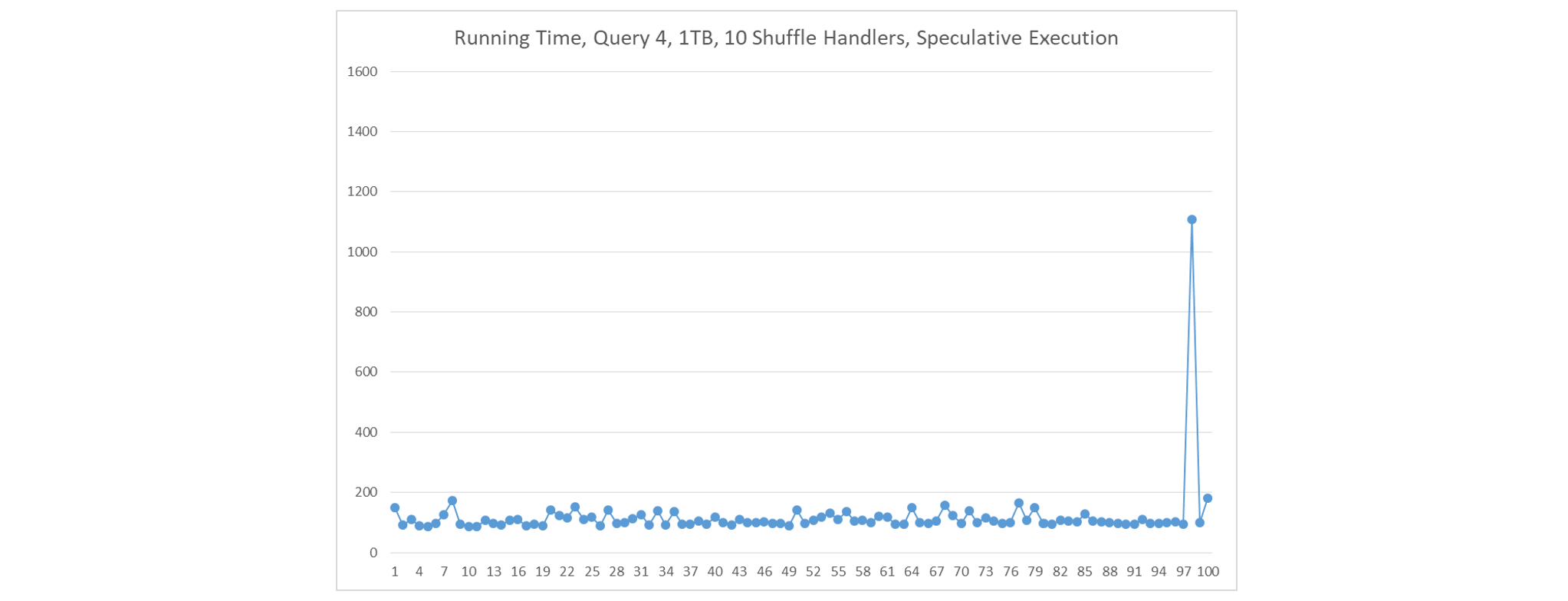
-
If we 1) deploy a single large ContainerWorker on each node, 2) create 20 shuffle handlers in each ContainerWorker, and 3) use speculative execution, fetch delays never occur. In this scenario, there are 20 shuffle handlers running on each node. Moreover the execution time is noticeably more stable than in the previous scenario.