The default configuration of Hive on MR3 is tailored to batch/interactive queries that involve join operators on multiple tables. Below we present a few suggestions that may improve the performance on simple queries that analyze single tables.
This page is work in progress and may be expanded in the future.
As a running example, we use the following query on a single table trade_record:
SELECT shop_id, partner, COUNT(DISTINCT unique_id)
FROM trade_record
GROUP BY shop_id, partner;
The default configuration works well
if the number of distinct values of the key unique_id is relatively small.
In our example,
we assume that the number is larger than the total number of records, e.g.:
> SELECT COUNT(*FROM trade_record;
9769696688
> SELECT COUNT(DISTINCT unique_id) FROM trade_record;
5361347747
hive.optimize.reducededuplication
By default, the configuration key hive.optimize.reducededuplication is set to true
in hive-site.xml
and produces the following query plan
where the key K corresponds to (shop_id, partner)
and the value V corresponds to unique_id:
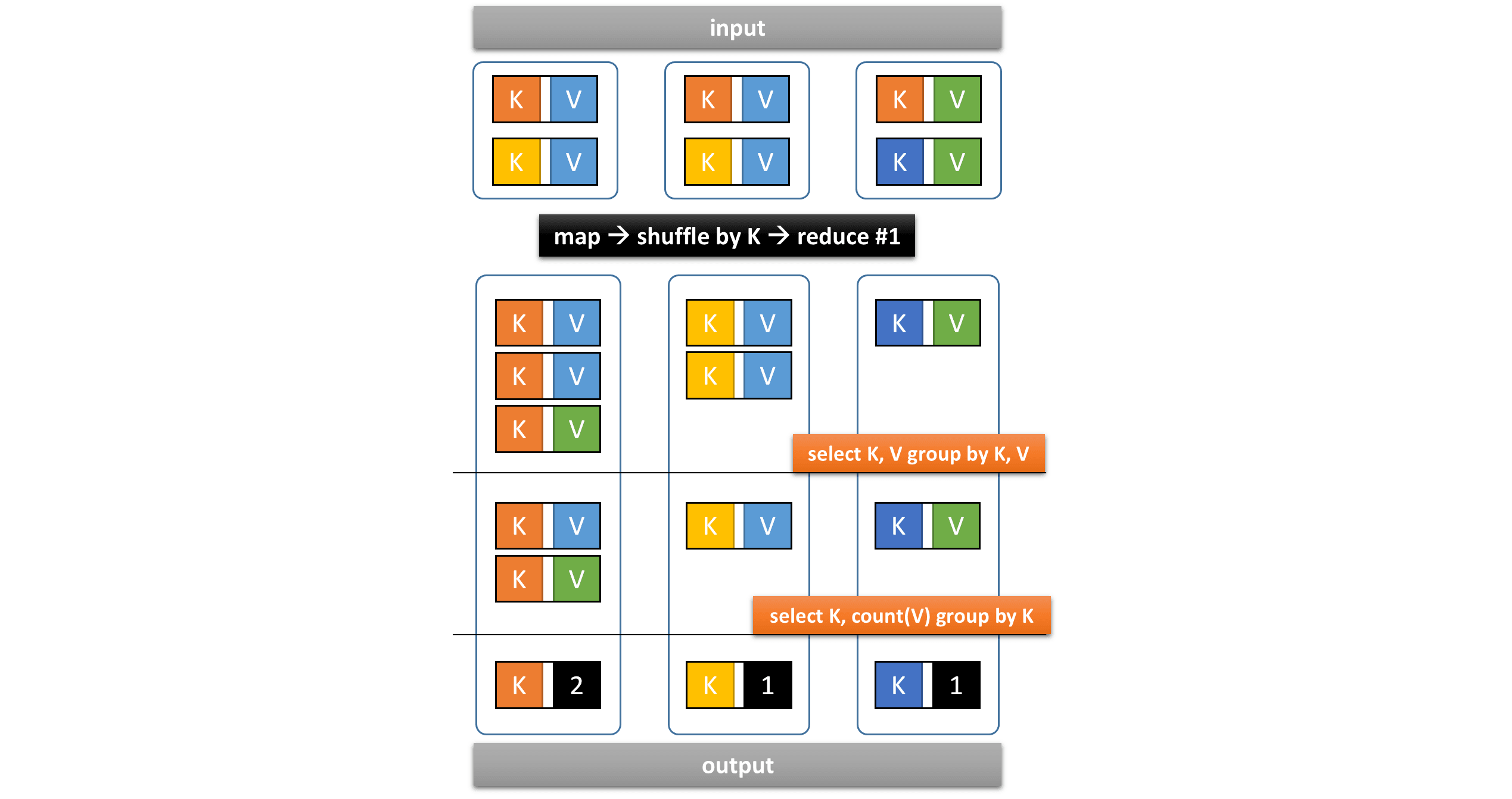
The query plan is already optimized in that
two GROUP BY operators are executed in a single vertex,
which, however, can become the performance bottleneck.
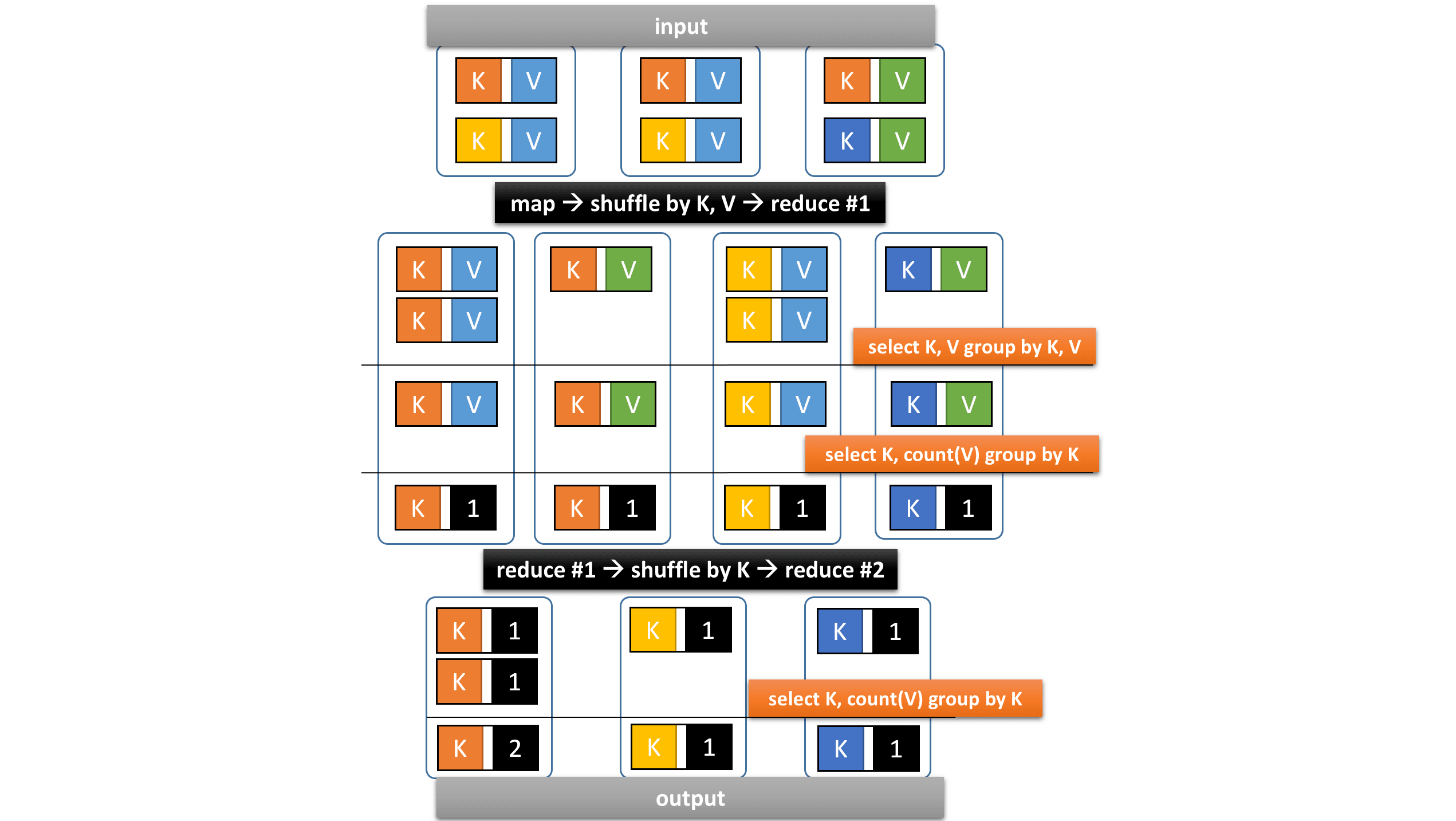
We can set hive.optimize.reducededuplication to false
in order to split the vertex into two.
A new shuffling stage is introduced, but the total execution time may decrease.
Skip merging ordered records
For a vertex producing ordered records,
Hive on MR3 can perform merging before shuffling to downstream vertices.
While this feature can reduce the execution time of shuffle-intensive queries,
it may not be useful for single-table queries.
The user can disable this feature
and enable pipelined shuffling instead
with the following changes in tez-site.xml:
- set
tez.runtime.pipelined-shuffle.enabledto true - set
tez.runtime.enable.final-merge.in.outputto false
To use pipelined shuffling, the user should disable speculative execution
by setting hive.mr3.am.task.concurrent.run.threshold.percent to 100 in hive-site.xml.
Enable memory-to-memory merging
By default,
Hive on MR3 performs disk-based merging to merge ordered records shuffled from upstream vertices.
If the number of ordered records to be merged in each reduce task is small,
memory-to-memory merging can be particularly effective.
The following changes in tez-site.xml enable memory-to-memory merging:
- set
tez.runtime.optimize.local.fetchto false - set
tez.runtime.shuffle.memory-to-memory.enableto true - set
tez.runtime.task.input.post-merge.buffer.percentto 0.9 (or any value close to 1.0)
